Un sitio personal para aprender desarrollo web
Mejoras de la aplicación Grafos SVG con la posibilidad de importar y exportar un grafo a los nuevos tipos DIMACS, DREADNAUT, GRAPH6, SPARSE6 y DIGRAPH6.
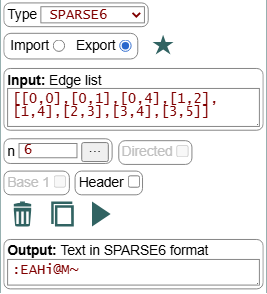
Se acompaña en esta página una aplicación para probar la importación y exportación de esos nuevos tipos, explicando como funcionan con el código JavaScript de su implementación.
Otras mejora implementada es la posibilidad de exportar una matriz de adyacencia con el formato de salida NSV de new-line separated values. Y también algunos atajos de teclado (keyboard shortcuts) para la edición de grafos.
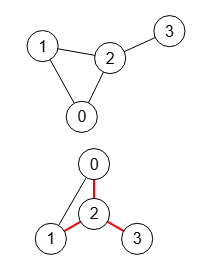
Un árbol Trémaux de un grafo no dirigido G es un árbol de recubrimiento (spanning tree) T tal que para cada arista [u,v] de G o "u" es un padre de "v" o "v" es un padre de "u" en T. Al ser T un árbol de recubrimiento que debe usar todos los vértices de G y algunas aristas de G y debe haber un único camino entre dos nodos de G donde debe definirse un nodo raíz, como es característico en un árbol. En el árbol de Trémaux las aristas que no forman parte del árbol se les denomina coaristas.
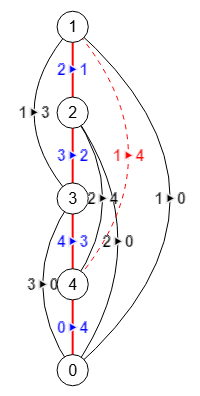
Ya vimos en el tema anterior que no es fácil implementar un algoritmo que nos diga si un grafo es plano. Pero parece que si ubicamos las coaristas en un árbol de Trémaux a derecha e izquierda del árbol sin que se crucen observaremos si es o no planar. En este tema se intenta implementar eso con el algoritmo isGrahPlanarTremaux().
Con ese algoritmo agremos un nuevo ajuste visual a planar, pues el algoritmo sólo nos devuelve las coaristas ubicadas en uno u otro lado del árbol de Trémaux, pero no lo presenta en pantalla. En la imagen adjunta vemos el resultado para el grafo completo K5, que sabemos que no es planar, donde la aplicación ubica todas las coaristas sin que se crucen a excepción de la 1-4 que no la pudo ubicar y se resalta con líneas de rayas rojas.
Un grafo es planar (o un grafo es plano) si puede dibujarse en un papel sin que se crucen aristas. Esta es una de las definiciones más fáciles de entender en la teoría de grafos. Pero no es fácil implementar un algoritmo que nos diga si un grafo es planar.
En este tema veremos los aspectos iniciales de este problema, exponiendo unos principios básicos de planaridad sobre los que implementaremos el algoritmo testGraphNoPlanar(), pues con esos principios puede asegurarse en ciertos casos que un grafo no es planar, pero no lo contrario. Veremos también los teoremas de Kuratowski, Wagner y la fórmula de Euler, pero que resulta díficil usarlos para implementar un algoritmo.
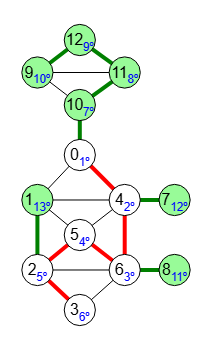
Con búsqueda en profundidad DFS o en anchura BFS obtenemos un árbol. Usualmente pensamos en un árbol como un tronco que parte desde un nodo raíz encadenando linealmente uno o más nodos y luego cero o más ramas que parten desde nodos en ese tronco. Podríamos pensar en las ramas como subárboles pues a su vez podríamos identificar un subtronco del árbol con subramas.
Definiendo un nodo como raíz, con el algoritmo getSubtrees() obtenemos el árbol usando DFS o BFS, identificando las hojas del árbol y a continuación buscamos en ese árbol el primer camino más largo entre el nodo raíz y cada una de los nodos hoja con el algoritmo findPath(). Este camino más largo será el tronco (camino en color rojo en la imagen). Luego identificamos las ramas entre el resto de caminos (color verde).
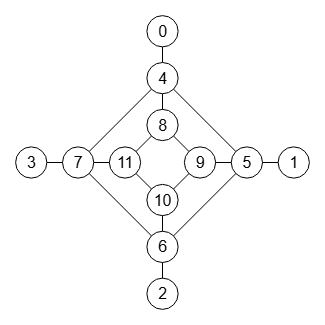
El grafo web es una serie de polígonos en círculos concéntricos con aristas radiales en sus vértices pero con el polígono exterior sin aristas circulares. Es como el grafo polígono, pero sin estas aristas exteriores. En la imagen vemos uno con un polígono de 4 lados en 3 círculos concéntricos, con el último sin aristas circulares. Lo de "web" es debido a que en Wolfram aparece con esa denominación.
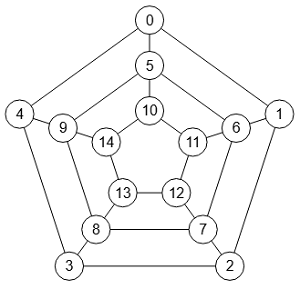
En la imagen vemos un grafo polígono generado con 5 lados y replicado en 3 círculos concéntricos con aristas radiales en sus vértices. Con sólo 1 círculo concéntrico esta generación es igual que la del grafo círculo. En Wolfram lo denomina stacked prism graph que se puede traducir como "grafo prisma apilado".
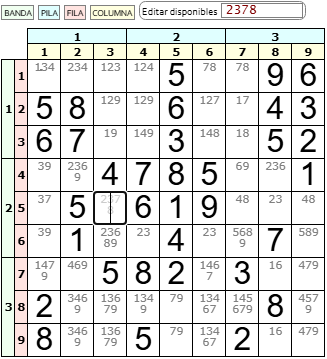
Ya hace bastante tiempo que publiqué la aplicación SUDOKU y ahora, a petición de un usuario, voy a implementar algunas mejoras. Una de ellas es la edición de disponibles como se observa en la imagen, que permitirá la edición manual de los disponibles pues antes sólo era posible usando el botón de pistas.
Otras mejoras implementadas son exportar e importar el tablero actual con disponibles, guardar y leer el estado actual o el inicial diferenciadamente, controlar y advertir cuando lleguemos a una situación con celdas sin disponibles, comprobar si el tablero tiene solución, exportar e importar la configuración o ajustes de la aplicación y hacer una captura de imagen del tablero.

Ya había comentado en temas anteriores que mi implementación del algoritmo getPartitionTree() para obtener el árbol de particiones y el etiquetado canónico se basa en los conceptos del algoritmo de McKay y ejemplos consultados en varios documentos de referencia. Pero la mejor forma de ir comprobando la corrección de la implementación es disponer del algoritmo testIsomorphisms(), donde se trata de obtener el etiquetado canónico del grafo inicial y luego de un conjunto de permutaciones aleatorias verificando que en todas se obtiene el mismo etiquetado.
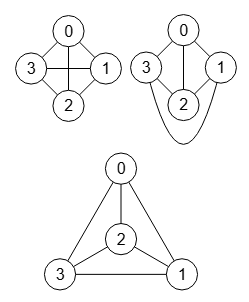
En este tema veremos como se comporta el algoritmo para algunas familias de grafos que se pueden obtener en la web nauty and Traces de McKay y Piperno, en la sección de Libraries of benchmark graphs. Y al mismo tiempo comprobar que su test de isomorfismos es correcto. En la imagen vemos el grafo Miyazaki MZ de 40 nodos, primero de la serie de tamaños hasta 1000 nodos, observando en la gráfica como evolucionan los tiempos de ejecución.
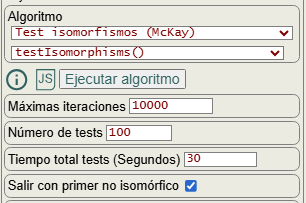
Para verificar la corrección del algoritmo de McKay en nuestra implementación, usamos el algoritmo testIsomorphisms() como se observa en la imagen, algoritmo que nos permite verificar que la obtención del etiquetado canónico es correcta. Se trata de obtener el etiquetado canónico del grafo y luego permutarlo aleatoriamente tantas veces como especifique el campo número de tests, aunque limitado con el campo tiempo total tests (segundos), pues cuando se supere ese tiempo finalizará devolviendo los resultados alcanzados. Con cada permutación del grafo se obtiene su etiquetado canónico y se comprueba que sea igual que el del grafo original. En un tema anterior ya habíamos comprobado la corrección con la poda con automorfismos usando un conjunto de grafos de ejemplo. Y ahora en este tema comprobamos la corrección usando indicadores.
En los temas anteriores vimos la poda con automorfismos en el algoritmo de McKay, que simplificábamos con poda mcr de minimum cell representative. En algunos grafos es posible además aplicar una poda con indicadores que reduce mucho más el tamaño del árbol de particiones y, por tanto, de los tiempos de ejecución.
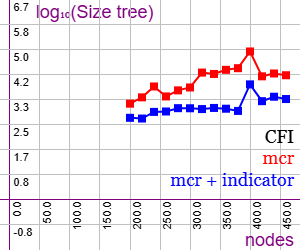
En la imagen vemos la ejecución del árbol de particiones con el grafo CFI con ejemplares de 200 a 460 vértices del grafo, midiendo el tamaño del árbol de particiones con el número de sus nodos (Size tree) en una escala logarítmica en base 10, donde valores como 1, 2, 3, 4, 5 significan 10, 100, 1000, 10000, 100000 nodos del árbol.
Con sólo poda automorfismos (mcr) tenemos la gráfica en color rojo, observando que para el último ejemplar de 460 vértices necesita un árbol de particiones con 13868 nodos (4.14 en el eje logarítmico vertical). Mientras que agregando la poda indicadores (mcr + indicator) en la gráfica en azul se reducen los nodos del árbol hasta 2232 nodos (3.35 en valor logarítmico). Esto supone una reducción de casi un 84% en número de nodos del árbol, algo que que se traduce en tiempos de ejecución, pues el tamaño del árbol de particiones es proporcional al tiempo de ejecución.
El objetivo principal del algoritmo de McKay con la implementación que llevo a cabo con getPartitionTree() es obtener el etiquetado canónico del grafo que se devuelve en el campo canonicalLabel del resultado. Pero también esta implementación me sirve para analizar y trazar la ejecución del árbol de particiones, automorfismos y cómo las opciones de ejecución pueden modificar el resultado.
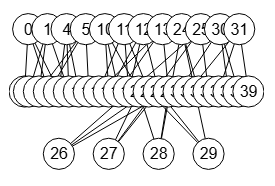
Para ver esto último tomaremos el grafo de Miyazaki de 40 nodos que se observa en la imagen. El árbol de menor tamaño con 76 nodos se consigue con las opciones de ejecución orden refinamiento neighbors-desc-lengths-desc y celda objetivo max-joins, siendo el de mayor tamaño con 343 nodos con neighbors-asc-lengths-desc y min-length-last respectivamente.