Otros detalles del buscador con PHP
Algoritmo recursivo para construir permutaciones
En los temas anteriores intento dejar claro que el objetivo principal es tratar de reducir los tiempos de proceso. Y una forma de hacerlo es tratar de evitar la ejecución de expresiones regulares. Esta es una técnica muy poderosa para realizar búsquedas, pero si no se tiene cuidado con los patrones construidos puede resultar muy ineficiente en términos de tiempos de ejecución. Por lo tanto he limitado el uso de las expresiones regulares al paginado de un conjunto de 10 resultados o menos, pues el primer filtrado se realiza sin expresiones regulares usando el índice de claves. Entonces aquí si entran en juego pero tratando de que sean lo más sencillas que se pueda. Hasta que nos topemos con la opción de buscar todas las palabras en cualquier orden.
A pesar de haber buscado o intentado idear un patrón para buscar un conjunto de palabras en cualquier orden no pude encontrar algo mejor que realizar las permutaciones señaladas. En un ejemplo expuesto en el tema anterior teníamos que buscar las palabras bordes,tabla en cualquier orden, lo que daba lugar al patrón /bordes.*?tabla|tabla.*?bordes/i. En definitiva necesitamos construir las permutaciones de ese conjunto de palabras {bordes, tabla}.
Pero el número de permutaciones de N elementos es N!. Así si nos pasan 10 palabras tendríamos un patrón con 10! = 3.628.800 permutaciones. Por lo tanto limitamos el número de palabras a permutar en la variable global $limite_alternativas = 4. Así sólo tomaremos la 4 primeras palabras de la lista y desecharemos el resto. Esto da lugar a 4! = 24 permutaciones como máximo. Este problema también es una razón de peso de porqué eliminamos las partículas de la cadena de búsqueda. No tendría sentido que los adverbios, preposiciones, artículos, etc. que vengan en la cadena de búsqueda formen parte de estas permutaciones pues sería impracticable, aparte de que esas partículas no aportan nada desde el punto de vista de buscar conceptos.
¿Cómo construimos adecuadamente las permutaciones?. Si son 2 palabras es fácil, /bordes.*?tabla|tabla.*?bordes/i. Aún con 3 es posible hacerlo manualmente, pero si son 4 ya estamos hablando de 24 permutaciones. Entonces decidí fabricarme uno usando la técnica de la recursividad. Por supuesto que no estoy inventando "la pólvora", pero este propósito ayudará a entender un poco más esa técnica de los algoritmos recursivos, término que expliqué para otro propósito en ese enlace del tema introductorio. El código del algoritmo para permutar es el siguiente:
function permutar($elementos, $concatena=""){
$num = count($elementos);
if ($num > 2){
$array_resultado = array();
foreach($elementos as $posicion => $actual){
//Extracción: Hacemos una copia del array
//y luego quitamos el actual
$extraidos = $elementos;
array_splice($extraidos, $posicion, 1);
//permutamos estos, finalizará cuando
//encuentre 2
$perm2 = permutar($extraidos, $concatena);
//Recomposición: a la vuelta concatenamos el actual
foreach($perm2 as $valor){
$array_resultado[] = $actual.$concatena.$valor;
}
}
return $array_resultado;
} else if ($num == 2){
//Este es el caso base cuando inicialmente hay
//más de 2 elementos. Se trata de permutarlos.
return array($elementos[0].$concatena.$elementos[1],
$elementos[1].$concatena.$elementos[0]);
} else if ($num == 1){
//Si inicialmente tiene 1 elemento saldrá por
//aquí con el mismo elemento que se pasó. Si inicialmente
//hay más de 2 no sale por aquí.
return array($elementos[0]);
} else {
//Lo mismo de antes pero cuando se pasa array
//vacío inicial.
return array();
}
} Todo algoritmo recursivo debe tener un caso base que nos asegure que el algoritmo termina. Si hay más de 2 elementos en el conjunto entonces buscamos todas las permutaciones, llamándose la función a sí misma de forma recursiva. Si hay exactamente 2 elementos en el conjunto entonces los permutamos, que es simplemente cambiarlos de orden. Y este es el caso base que asegura que el algoritmo termina. Bueno, también pueden existir otros casos base excepcionales, como cuando permutamos un conjunto de un único elemento o bien un conjunto vacío.
Hay que tener muy claro que exista el caso base. Veáse que el algoritmo va reduciendo el tamaño del problema en cada pasada hasta que encuentre ese caso base. En nuestro ejemplo se va reduciendo el conjunto de elementos hasta que queden únicamente dos, que será el caso base. De no llegar a ese punto entonces el algoritmo seguirá ejecutándose indefinidamente pues no se producirá la vuelta o recomposición de resultados. No hay ningún método que nos permita decir en cada problema cuál es el caso base, pero es estrictamente necesario saber detectarlo pues de otra forma no se puede plantear el problema mediante esta técnica.
Para ver cómo funciona el algoritmo, hagamos un ejemplo. Supongáse el conjunto de elementos {a, b, c}. Debe darnos la lista de 3! = 6 permutaciones abc, acb, bac, bca, cab, cba (concatenándo los elementos con una cadena vacía). Tiene más de 2 elementos por lo que entrará por el primer condicional e iteraremos por el conjunto. No es fácil representar esquemáticamente como evoluciona un recursivo, pero lo intentaré. Este esquema refleja las iteraciones donde se realiza la extracción de un elemento consecutivamente del conjunto, eliminándose de una copia de ese conjunto. Es sobre esa copia donde se hacen las permutaciones. En este ejemplo resulta que ya es un caso base, por lo que obtenemos las 2 permutaciones, de tal forma que a la vuelta en la recomposición tenemos las permutaciones con los 3 elementos.
[1] extrae (a) --> permuta({b,c}) --> caso base: bc, cb
--> recompone: abc, acb
[2] extrae (b) --> permuta({a,c}) --> caso base: ac, ca
--> recompone: bac, bca
[3] extrae (c) --> permuta({a,b}) --> caso base: ab, ba
--> recompone: cab, cba
--> finaliza devolviendo abc, acb, bac, bca, cab, cbaQuizás habrá algún algoritmo más eficiente para hacer esto, pero dado que está limitado a un bajo número de elementos (4 declarados), esta implementación es más que suficiente para nuestro propósito.
Tamaño de los índices y mejoras de los tiempos de respuesta
El buscador acompaña una utilidad que traza los tiempos de ejecución en cada parte del proceso. Esta traza puede ser desactivada con la variable global $traza. Y quizás eliminar todo el código de la traza para no ocupar tiempo en ella. Pero he preferido dejarla para comprobar los tiempos de ejecución. Será algo como esto para una primera búsqueda:
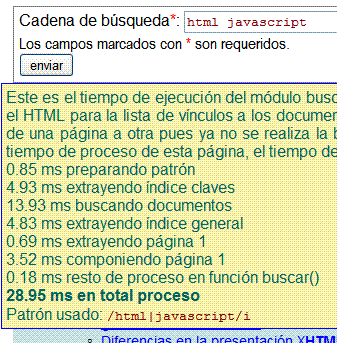
round(), pues este total no se calcula sumando las partes, sino midiendo lo que dura el proceso en total. Luego deduciendo lo que dura la suma de las partes (sin redondear) obtenemos la duración del resto del proceso de la función buscar(), esos 0.18 ms.El array de índice de claves actual contiene unas 1646 palabras obtenidas de 76 documentos presentes en el array del índice web. Es decir, este sitio contiene ahora 76 documentos con extension html/php que, conteniendo información estática, componen el índice web. Pues dejo fuera las páginas de ejemplos que no aportan términos conceptuales (en total el sitio tiene actualmente unos 340 documentos html/php y unos 710 si incluimos también otras extensiones css, js, archivos de imagen, etc.).
Por lo tanto este sitio es relativamente pequeño. Pero en las pruebas que hice en localhost use un conjunto de 1020 documentos en el índice web y de 3432 palabras claves en el índice de claves. Aún así los resultados en tiempos de ejecución seguían manteniéndose en un nivel aceptable, principalmente porque el índice de claves no era excesivamente mayor. Es decir, aunque el número de documentos se multiplica por 13 el de claves sólo se duplica, por lo que de todas formas no es una muestra representativa (esto es porque en parte usé varias copias de los mismos documentos). Lamentablemente no dispongo de tantos documentos como para crear un conjunto de claves mayor.
En todo caso tenemos identificado los puntos críticos que pueden producir una sobrecarga. Son aquellos bucles que iteran por un número desconocido (a priori) de elementos, en las funciones buscar_docs() y extraer_pagina(). Ahí hemos puesto limitadores de tiempo que cortaran la ejecución mostrando los resultados gestionados hasta ese momento. En las otras funciones los bucles están perfectamente limitados, por ejemplo al número de resultados por página (10), por lo que el tiempo de respuesta está de alguna forma bajo control.
Hay un aspecto que podría mejorarse en la función buscar_docs() si el índice de claves fuese mucho mayor. Se trata de considerar la posibilidad de que no se tenga que iterar por todo el índice para buscar partes de palabra sino sólo el inicio o raíz de la misma. Por ejemplo, con la palabra "form" devolveríamos esa si existe y otras como "forma", "formación", "formato", "formulario", etc. Quizás primero preguntaríamos si existe la clave "form", en cuyo caso iteramos y vamos devolviendo claves hasta que encontremos alguna que ya no empiece con esa raíz (el índice estaría, y de hecho ahora lo está, ordenado alfabéticamente). Si no existiera esa clave "form" en el índice, quizás podíamos disponer de un segundo índice que resumiera las 2 letras de cada clave del índice. Así tendríamos un índice de claves secundarias (de menor tamaño) con una de ellas como "fo" que nos apuntaría a la primera clave del indice primario que empiece con esas letras y entonces buscar la primera que empiece por "form" y seguir como el proceso anterior.
Tiempos de lectura de los archivos de índices
Otro detalle donde se consume tiempo y que no está del todo bajo nuestro control es en la extracción de los arrays de índices. El control de esos tiempos está en manos del servidor web mediante el uso del módulo de PHP y, en última instancia, del propio sistema operativo. Recordemos que estos archivos de índices están serializados y almacenados como archivos de texto. Actualmente el archivo serializado del array índice de claves ocupa 64 KB con 1646 palabras claves. El de índice web ocupa 134 KB para unos 76 documentos. Se recuperan con la función PHP unserialize() y usando las funciones PHP para leer archivos.
En ciertas ocasiones coincidiendo con la primera búsqueda tras abrir la página del formulario en este servidor real se pueden registrar 50 ms para el índice web y 30 ms para el de claves, aunque estos tiempos suelen variar pues al estar leyendo en disco dependerá de las circunstancias. En las siguientes búsquedas o solicitudes de páginas el tiempo decrece enormemente (menos de 10 ms, incluso sobre los 2-3 ms) y permanece de forma similar independientemente del navegador usado. Este se debe a que las lecturas desde el disco son introducidas en cachés de memoria a compartir por más de un usuario del servidor y, mientras se estén usando, las conserva para posteriores accesos. Así es posible que tras un determinado tiempo sin acceder a esa caché, sea eliminada y una nueva lectura obligue a acceder al disco. Veámos la función que carga los índices:
function extraer_indice(&$indice, $archivo){
$mensaje = "";
$error = false;
$archivo_indice = "/../prvt/php/buscador-web/".$archivo;
$contenido = "";
if (($contenido = @file_get_contents($_SERVER["DOCUMENT_ROOT"].$archivo_indice)) === false){
$mensaje = "Error: No pudo leerse el archivo de índices.";
$error = true;
} else {
$indice = unserialize($contenido);
}
return array("error"=>$error, "mensaje"=>$mensaje);
} El uso de la función PHP file_get_contents() asegura un buen rendimiento cuando cargamos en memoria un archivo desde el disco. Al menos eso asegura el manual PHP que dice literalmente "es la manera preferida de transmitir el contenido de un archivo a una cadena. Usa técnicas de mapeado de memoria, si está soportado por su sistema operativo, para mejorar el rendimiento." Un artículo de Wikipedia nos habla del mapeado de memoria, haciendo también mención en las referencias finales a esa función file_get_contents(). La otra opción sería usar las funciones que abren un fichero (fopen) y luego lo leen (fread).
function extraer_indice(&$indice, $archivo){
$mensaje = "";
$error = false;
$archivo_indice = "/../prvt/php/buscador-web/".$archivo;
$contenido = "";
if (($fichero = @fopen($_SERVER["DOCUMENT_ROOT"].$archivo_indice, "r")) === false){
$mensaje = "Error: No pudo leerse el archivo de índices.";
$error = true;
} else {
$tamanyo = filesize($_SERVER["DOCUMENT_ROOT"].$archivo_indice);
if ($tamanyo == 0){
$mensaje = "Error: El archivo de índices está vacío.";
$error = true;
} else {
$contenido = @fread($fichero, $tamanyo);
$indice = unserialize($contenido);
}
}
return array("error"=>$error, "mensaje"=>$mensaje);
}Si usamos esta función no se aprecian cambios significativos en los tiempos que se registran para esos tamaños de archivos (64KB y 134KB). Reiniciando mi ordenador para que vacíe toda la memoria y volviendo a lanzar una búsqueda ahora con el fopen y fread, volvemos a apreciar que la primera lectura de esos archivos ocupa más tiempo al leer en disco, pero luego la introduce en alguna caché de memoria y las siguientes lecturas, incluso desde navegadores distintos, vuelven a situarse en torno y por debajo de los 10 ms.
En cuanto a la nota del manual PHP sobre el mapeado de memoria que mejora la respuesta de file_get_contents() frente a fopen(), fread() y tras ver que al menos yo no aprecio diferencias, es interesante comprobar como también alguién coincide con esto. En esa página del manual file_get_contents() hay un comentario en el encabezado "corey at effim dot com 09-Jun-2009 09:35". Se observa que realizó algunas pruebas y tampoco encontró diferencias. Me sumo a su propuesta en el sentido de aportar ambas opciones de lectura y usar aquella que preste mejores resultados. Como ahora no hay diferencias apreciables, usaré file_get_contents(). Pero si se observan tiempos no asumibles entonces deberíamos probar con la otra opción de lectura.
Es posible, aunque no lo puedo asegurar, que ni siquiera las dos opciones de lectura arreglen el problema cuando los archivos de índices sean muy grandes. En ese momento habría que ir pensando en almacenar esos índices en una base de datos y optimizar los tiempos en las consultas SQL. Pero esa es otra historia.