Las funciones del buscador con PHP
La función general para buscar
Esta función buscar() es la que implementa el diagrama de flujo expuesto en uno de los temas anteriores. Aquí se gestiona todo el flujo del proceso de búsqueda y tiene la siguiente declaración:
function buscar($cadena_busqueda, $pagina=-1, $seleccion="documento", $tipo_busqueda="alguna", $palabras_completas=false, $sensible_mayusculas=false)
Desde la página que contiene el formulario se pasa la cadena de búsqueda y las opciones de búsqueda, así como el número de página que inicialmente con la primera búsqueda tiene un valor -1 y cuando solicitamos alguna página (estaremos entonces paginando) nos viene con el valor de esa página (referenciadas desde la 0).
El diagrama de flujo expuesto en un tema anterior es una primera aproximación a esta función buscar(). Pero si queremos más detalle sin tener que ir directamente al código podríamos usar pseudocódigo, que viene a ser algo así como expresar directamente con frases que es lo que hace el programa. Esto sería, expresado con frases, lo que hace esa función:
- Pasar
htmlentities()a la cadena de búsqueda para convertir los caracteres Unicode en entidades de caracter. - Preparamos el patrón con la función
preparar_patron()usando esa cadena de búsqueda y las opciones. Esta función también nos devolverá el array de palabras, es decir, hará la separación en palabras de la cadena de búsqueda. - Si el número de página es mayor que -1 y hay variable de sesión almacenada es que estaremos paginando resultados de una búsqueda anterior:
- Extraemos el patrón y el array de documentos de las variables de sesión correspondientes a la busqueda anterior, así como otras variables para controlar el escaneado o filtrado del array de documentos.
- En otro caso será una primera búsqueda:
- Extraemos el índice de claves.
- Buscamos documentos con
buscar_docs()usando el índice de claves y el array de palabras, lo que nos devolverá el array de documentos. - Si la función de buscar documentos se cortó por superar el límite de tiempo:
- Eliminar palabras del array de palabras.
- Volver a obtener el patrón con estas palabras.
- Si el array de documentos está vacío:
- Borrar las variables de sesión.
- En otro caso:
- Guardar los nuevos valores del array de documentos y el nuevo patron en las variables de sesión.
- Preparamos el paginado (si es primera búsqueda la página será la 0, en otro caso la que se haya pasado en el argumento).
- Extraemos el índice web.
- Extraemos esa página con la función
extraer_pagina()usando el array de documentos, el índice web, la posición donde se inicia el paginado, el array de palabras y las opciones de búsqueda, lo que nos devolverá el array de resultados. - Si la selección es por documento:
- Guardamos la variable de sesión escaneado = true, pues con esta opción se aceptan todos los documentos del array de documentos.
- En otro caso la selección es por apartados y podrían descartarse resultados:
- Realizamos un control sobre el número de páginas escaneadas, la última página extraida y el total de páginas. Mientras no se finalice el filtrado de todos los documentos contenidos en el array de documentos, la variable de sesión escaneado permanece con valor false.
- Si el array de documentos actual contiene menos elementos que el almacenado previamente en la variable de sesión, sobreescribimos la variable con el nuevo array de documentos, pues se han descartado resultados.
- Enviamos el array de resultados a la función
componer_pagina(), que a su vez nos devolverá una cadena literal con el HTML de los 10 resultados obtenidos para esa página así como la botonera de páginas. Si la selección es por apartados, sólo aparecerán las páginas extraidas hasta el momento y un botón para ir a paginar la siguiente. - Devolvemos un array con los resultados y otros datos necesarios para componer la página con el formulario.
En los siguientes apartados intentaré aclarar algunas cuestiones de interés.
Preparando lista de palabras y patrón de búsqueda
La función preparar_patron() tiene esta declaración:
function preparar_patron($cadena_busqueda, $seleccion, &$tipo_busqueda, $palabras_completas, $sensible_mayusculas, &$palabras, $repatronear=false)
Se observa que $tipo_busqueda y $palabras se pasan por referencia pues pueden ser modificadas en el interior de esta función. En resumen se trata de recibir la cadena y las opciones de búsqueda y preparar el patrón de expresión regular.
En principio la aplicación de expresiones regulares para buscar coincidencias está limitada a la función extraer_pagina(). Y con la selección por documento incluso sólo se aplica a la selección de los encabezados identificados. En cualquier caso hay que preparar el patrón para ofrecer cualquiera de las páginas de resultados, tanto la primera como las siguientes y, además, si el patrón cambia entre una petición y otra podemos saber que el usuario ha modificado algo en las condiciones de la búsqueda.
Pero para buscar los documentos donde se producen coincidencias, lo cual hacemos analizando el índice de claves, no necesitamos aplicar expresiones regulares. Como ese índice se referencia por términos o palabras clave, hemos de extraer esas palabras desde la cadena de búsqueda. Y esas palabras serán almacenadas en la variable $palabras al mismo tiempo que construimos el patrón.
Para extraer las palabras usamos la función palabrear() que divide en palabras la cadena de búsqueda. Se trata de eliminar letras y dígitos sueltos así como signos ortográficos. También eliminamos ciertas palabras de uso frecuente que no se encontraran en el array índice de claves. Por supuesto, porque ese array se construyó también usando esta función palabrear(). Esas partículas son preposiciones, adverbios, artículos, etc. Al final obtenemos una cadena de palabras separadas por espacio.
La variable $palabras es un array con dos entradas
$palabras["con-acute"]$palabras["sin-acute"]
Por ejemplo, la palabra función nos llega aquí en la cadena de búsqueda escapada, es decir, nos llega función (al pasar htmlentities() a la cadena de búsqueda inmediatamanente tras ser recibida desde el formulario). Por lo tanto función se almacena en $palabras["con-acute"] y funcion sin tilde se almacenará en $palabras["sin-acute"], que es la que usaremos para realizar la búsqueda en el índice de claves. Para quitar los acentos hacemos esto:
function quitar_acutes($cadena){
$cadena = preg_replace("/&([aeiouAEIOU])acute;/", "$1", $cadena);
$cadena = str_replace("ñ", "ny", $cadena);
return $cadena;
}Incluso cambiamos la ñ (la "ñ") por "ny". Pero esto no afectará a la búsqueda, pues si en el índice de claves hay una entrada como tamanyo es que cuando construimos ese índice la modificamos de la original tamaño. Pero cuando busquemos en el índice web, donde realmente están los contenidos con las palabras escapadas, aplicaremos el patrón con el array $palabras["con-acute"] usando tamaño que es la que el usuario verá en los resultados.
La razón de esto que parece complejo está en la sencillez del array de índice de claves. Es más fácil almacenar una única versión de una palabra que tener una con tilde y otra sin tilde. Además la función que explora el índice de claves puede encontrar coincidencias parciales. Así si pasamos en la cadena de búsqueda la palabra función con la opción de palabras completas desactivada, buscaremos otras variantes partiendo de esa raíz en el índice como funciones, funcionar, fucionamiento etc. Esto sólo lo podemos hacer si usamos un índice sin acentos, pues de otra forma tendríamos en el índice la palabra función que no podría ser raíz (lo impide la "ó") de las otras variantes.
Además del motivo anterior hay algunos factores que aconseja escapar los unicode como entidades de caracter en un sistema de búsqueda. Las expresiones regulares tienen menos problemas si sólo tienen que buscar caracteres ASCII. Por otro lado y aunque todos mis documentos están codificados en UTF-8, es posible que haya que indexar una combinación de documentos en varias codificaciones. Por eso cuando construimos los índices convertimos cualquier codificación a UTF-8 y luego escapamos los unicode con entidades de caracter. Así en el índice web tendremos la palabra "función" como parte del texto de los apartados, por lo que los resultados de la búsqueda pueden ser presentados en cualquier página sin tener en cuenta que codificación usa. Mientras que en el índice de claves tendremos "funcion" sin tilde, en la cadena de búsqueda si nos pueden pasar "función" con la tilde, pero al recibido de esa cadena del formulario le aplicamos también htmlentities() para escapar ese Unicode.
La preparación del patrón depende de las opciones de búsqueda. Si la selección es por documento el patrón se conforma con las alternativas de las palabras. Y esto independientemente de la opción buscar alguna o todas las palabras. Por ejemplo, si la lista de palabras es abc,def el patrón resultante será /abc|def/i. Con la opción de palabras completas quedaría como /\babc\b|\bdef\b/i. Recuerde que la opción por documentos usa todos los que se encuentre con la función buscar_docs() que no utiliza el patrón, sino que hace una comparación directa con las claves del índice de claves. Así si la opción es buscar todas las palabras, el filtrado lo hacemos realizando una intersección entre los documentos coincidientes con cada palabra de la lista.
Si alguna palabra está acentuada, el patrón se construye con las dos versiones de esa palabra. Por ejemplo, la búsqueda por documento de la palabra función construirá el patrón /función|funcion/i lo que nos servirá para detectar ambas palabras (o raíces de esa palabra) en los encabezados identificados.
Además en esta selección por documento sólo cabe que no sea sensible mayúsculas-minúsculas, por lo que siempre tendrá el modificador i este patrón. Esto es debido a que el filtrado se realiza con las las claves del índice de claves que están en minúsculas, por lo que no cabe esa diferenciación.
En la búsqueda por apartados si necesitamos diferenciar adecuadamente el patrón, pues filtraremos los distintos apartados con este patrón. Veámos un resumen de las opciones posibles usando la cadena de búsqueda bordes de tabla que da lugar a la lista de palabras bordes,tabla:
| Opción | Patrón | Notas |
|---|---|---|
| Alguna palabra | /bordes|tabla/i | Alternativas que viene a ser una disyuntiva: "bordes" O "tabla" |
| Todas las palabras en ese orden | /bordes.*?tabla/i | Es una conjuntiva: "bordes" Y "tabla" |
| Todas las palabras en cualquier orden | /bordes.*?tabla|tabla.*?bordes/i | Se trata de componer todas las permutaciones de las alternativas que contengan todas las palabras. |
| Cadena completa | /bordes[ \s]+de[ \s]+tabla/i | En este caso no eliminamos las partículas de la cadena de búsqueda y se incorporan al patrón. |
En estos ejemplos además cabe sensible mayúsculas (aparecerían los patrones sin el modificador i al final del patrón) y palabras completas. Ahora para las palabras acentuadas no usamos la versión sin tilde como hacíamos en la búsqueda por documento, pues el patrón se aplicará directamente sobre los apartados buscando fielmente lo que el usuario nos pide. El caso de todas las palabras en cualquier orden es de especial atención pues hay que construir las permutaciones. Esto lo vemos en el siguiente tema, en el apartado de un algoritmo recursivo para construir permutaciones.
La función para buscar documentos
Esta función buscar_docs() tiene la siguiente declaración:
function buscar_docs(&$indice_claves, $palabras, $tipo_busqueda, $palabras_completas)
El objetivo general de este buscador es lograr reducir los tiempos de proceso de búsqueda. Tal como se comentó en el tema anterior y a modo de resumen, el proceso completo de búsqueda, extracción y composición de página de resultados se divide en dos fases:
- En la primera búsqueda con la función
buscar_docs()ejecutamos un proceso para encontrar coincidencias con el índice de claves. En esto no intervienen las expresiones regulares y las coincidencias se realizan buscando la palabra en la clave del índice, simplemente usando la función PHParray_key_exists(), o en el peor de los casos por comparación usando la función PHPstrpos(). Pero siempre esto es más eficiente que usar expresiones regulares. Así obtenemos un conjunto de números de documentos (el array de documentos$arr_docs) donde se produce la coincidencia. - El conjunto de documentos de coincidencias puede ser mayor que la primera página de resultados que vamos a ofrecer al usuario (declaramos que se enviarán 10 resultados por cada página solicitada por el usuario). Así la segunda parte de este proceso es para extraer página mediante la función
extraer_pagina(). Aquí es donde intervienen las expresiones regulares que se aplican a los textos completos incluidos en el índice web, para así realizar un filtrado a posteriori del array de documentos. Se obtiene el array de resultados ($arr_resen el código) que nos servirá para componer la página de resultados que le enviamos al cliente. Aunque aplicamos expresiones regulares en esta fase, sólo lo hacemos para el conjunto de resultados a enviar (10 por página) y no sobre el total de resultados encontrados en la primera fase que puede ser muy superior.
Antes de llegar a esta versión definitiva hice muchos intentos. El primero buscador con PHP leía directamente los contenidos de los documentos, iterando recursivamente por el árbol de archivos. Luego mediante expresiones regulares como preg_match_all() buscaba todas las coincidencias de las palabras de la búsqueda. Esto funcionaba, pero era de todo menos rápido.
Descartada la búsqueda sobre el texto original de los documentos probé con el uso de índices de palabras claves. Resuelto el problema de como construir el índice, pasé a buscar las palabras directamente en ese índice y, en la misma fase, filtrar TODOS los resultados encontrados con expresiones regulares. Esto aún consumía mucho tiempo. Caí en la cuenta de que el usuario no necesita en la búsqueda inicial más que los 10 primeros resultados para la primera página. Entonces la clave del asunto estaba en separar ese proceso en dos tal como expuse.
Para realizar la primera parte buscando documentos en el índice usamos algo de la teoría de conjuntos. Supongamos que estamos buscando la cadena "borde de tabla" que da como resultado el conjunto de palabras {borde, tabla} al omitir la partícula "de". Estas dos palabras aparecen en el array índice de claves realmente así:
Array( ... [borde] => Array([0]=>62 [1]=>69) ... [tabla] => Array([0]=>6 [1]=>62 [2]=>65 [3]=>74) ...)
Buscar esas palabras en el índice de claves es tan sencillo como iterar por el conjunto de palabras a buscar {borde, tabla} y hacer un array_key_exists() de cada una de ellas obteniendo los conjuntos de números de documento donde se encuentran. Así la palabra "borde" se encuentra en los documentos con número 62 y 69 del array índice web. Por otro lado "tabla" se encuentra en los documentos 6, 62, 65 y 74. Se ve claro que si estamos buscando alguna palabra, esto se corresponde con la unión de esos dos conjuntos:
{62,69} ∪ {6,62,65,74} = {6,62,65,69,74}Pero si la opción de búsqueda es para buscar todas las palabras es evidente que hemos de aplicar la intersección de esos dos conjuntos:
{62,69} ∩ {6,62,65,74} = {62}Y el lenguaje PHP nos ofrece para esto una agradable sorpresa pues se puede implementar ambas operaciones tratando los arrays como conjuntos. Para la unión usaríamos array_merge(A,B) que nos daría el array (62,69,6,62,65,74). Quitaríamos los duplicados (el 62) usando la función array_unique() quedando el conjunto resultante de la unión {62,69,6,65,74} con este array:
Array([0]=>62 [1]=>69 [2]=>6 [4]=>65 [5]=>74)
Vemos que, aparte de estar desordenado por los valores, se ha perdido la correlatividad en las claves (falta la clave 3). Aunque estas claves no referencian nada en concreto, en procesos posteriores necesitaremos que no se produzca esto. Podemos arreglarlo con la función sort() que, aparte de ordenar los valores, reconstruye las claves numéricas partiendo desde 0 quedando finalmente:
Array([0]=>6 [1]=>62 [2]=>65 [3]=>69 [4]=>74)
Para la intersección de conjuntos usamos la función array_intersect(A,B). Las claves también se mantienen tras esta operación, por lo que hay que volver a pasar array_unique() y sort().
Estas funciones trabajan sobre arrays con claves y valores numéricos, por lo que el coste de las mismas no es muy alto. Y en todo caso se aprecia una notable mejora en comparación con las otras alternativas que probé.
Mejoras de la fase de buscar documentos
Podemos incorporar a esta fase la opción de búsqueda de palabras completas. Por ejemplo, si estamos buscando la cadena "cabeza y pie de una página" con esa opción de buscar palabras completas, realmente buscaríamos en el índice de claves las palabras "cabeza", "pie" y "pagina" (esta última sin el acento). Pero sin esa opción tendríamos que buscar todas las coincidencias con cualquier parte de esas palabras. Así encontraríamos "encabezado", "propiedad" o "paginados" entre otras aparte de las buscadas que también están en el índice. Para lograr esto en la primera fase de buscar documentos donde aún no usamos expresiones regulares, se declara la función buscar_docs() de esta forma:
function buscar_docs($indice_claves, $palabras, $tipo_busqueda, $palabras_completas)
Aparte del índice de claves y la lista de palabras a buscar, pasamos la opción de palabras completas y también la del tipo de búsqueda que podía ser buscar alguna palabra o todas, lo que nos permitirá saber si hemos de usar la unión o intersección de conjuntos como se expuso en el apartado anterior. En pseudocódigo esta función para buscar documentos se puede esquematizar así:
Sea A = Ø un conjunto vacío.
Hacer bucle desde la primera a la última palabra
que vienen con la cadena de búsqueda:
Sea B = Ø un conjunto vacío.
Si NO buscamos palabras completas:
Hacer bucle por las claves del índice de claves:
Sea C el conjunto de esa clave.
Si la palabra es igual a la clave o la palabra
está contenida en la clave:
B = B ∪ C.
Fin si.
Fin bucle.
En otro caso buscamos palabras completas y si
existe esa palabra en el índice de claves:
Sea B el conjunto de esa clave.
Fin si.
Si buscamos alguna palabra:
A = A ∪ B.
En otro caso si las buscamos todas:
Si A == Ø (primer conjunto):
A = B.
En otro caso:
A = A ∩ B.
Fin si.
Si A == Ø rompemos el bucle.
Fin si.
Fin bucle.Se trata de iterar por las palabras que nos vienen de la cadena de búsqueda. Si no estamos buscando palabras completas entonces hemos de recorrer todo el índice de claves para comprobar si la palabra en cuestión está en las claves del índice o forma parte de alguna clave. Por ejemplo, la palabra "pie" está en las claves del índice pero también forma parte de otras claves como "propiedad". Como estamos buscando partes de palabras, hemos de devolver todas las coincidencias. Si estamos buscando palabras completas, sólo hemos de comprobar que esa palabra es alguna clave. De este primer paso obtenemos el conjunto B que unimos con el conjunto A (el que finalmente obtendremos) si estamos buscando alguna palabra, o bien los interseccionamos si estamos buscando todas las palabras.
La implementación final de este esquema contempla una mejora relativa al coste de recorrer el array del índice de claves. Se trata de limitar en tiempo esta iteración, declarando un límite de 100 milisegundos en la variable global $limite_tiempo. Antes de entrar en cada pasada de ese bucle interior comprobamos si se ha sobrepasado el lapso de tiempo declarado. En ese caso cortamos la iteración y sólo presentamos los resultados relativos a las palabras ya encontrados. El límite de tiempo hemos de declarlo tras haber realizado algunas pruebas con algún ejemplo que nos ponga en el peor caso. El campo de búsqueda está limitado a un tamaño de 75 caracteres. Además cada palabra ha de tener 2 o más caracteres pues las letras y dígitos sueltos son eliminados de la lista de palabras. Así como mucho podemos enviar unas 25 palabras de 2 caracteres. Por ejemplo, enviando estas 25 palabras:
ba be bi bo bu ca ce ci co cu fa fe fi fo fu ga ge gi go gu ta te ti to tu
Recuerde que se trata de buscar estas sílabas dentro y en cualquier posición de las claves. En localhost el bucle consume los 100 milisegundos y se corta en torno a la palabra co, por lo que procesa las 9 primeras en un promedio de 11 milisegundos por cada palabra de las 25. Así para procesarlas todas tardaría unos 25x11=275 milisegundos. En el servidor real, que es por supuesto más rápido que mi ordenador si no está sobrecargado, puede aún procesar algunas palabras más en esos 100 ms. Aunque ahora es posible aceptar los 275 milisegundos para que procese las 25 palabras, creo que conviene imponer alguna limitación puesto que ahora el índice de claves tiene 1642 claves (lo que da un total de 25x1642=41050 iteraciones), pero si ampliamos ese índice con nuevos documentos entonces también se incrementarán esos 275 ms (recuerde que este es sólo el tiempo del proceso de búsqueda, pues además hay que sumar otros tiempos de otros procesos). En cualquier caso y siempre que sea posible hemos de controlar la duración de los procesos en informática, y más si estamos en un servidor web.
La función para extraer página
Esta función extraer_pagina() tiene esta declaración:
function extraer_pagina(&$arr_docs, $desde, $patron,$indice_web, $palabras, $seleccion, $tipo_busqueda, $sensible_mayusculas, $palabras_completas)
Una vez pasada la fase anterior de búsqueda de documentos disponemos en el array de documentos ($arr_docs) los números de posición en el array índice web de los documentos donde se encuentran las palabras a buscar. Si es la primera búsqueda hemos de ofrecer al usuario un primer conjunto de los 10 primeros resultados. Esto lo hacemos con la función de extración de página extraer_pagina().
Sigamos con el ejemplo expuesto más arriba donde teníamos la cadena de búsqueda "borde de tabla" que da como resultado el conjunto de palabras {borde, tabla}. Ahora las opciones para este ejemplo son:
- Seleccionar por: documento
- Buscar palabras: todas
- Buscar palabras completas: no
- Patrón:
/borde|tabla/i
Con estas opciones el array de documentos devuelto es:
Array([0]=>62 [2]=>65 [3]=>74)
Esto quiere decir que las palabras (o parte de esas palabras) {borde, tabla} se encuentran, al mismo tiempo, en los documentos cuyo número de posición en el índice web son los incluidos en ese array: 62, 65, y 74. Estos documentos del array índice web son los siguientes, donde los puntos suspensivos es texto o encabezados donde no existen esas palabras:
[62] => Array( [u] => "/temas/xhtml-css/css-dimension.html" [t] => "..." [d] => "... bordes ..." [k] => "... bordes ..." [i] => Array( ... [7] => Array( [0] => "ancho-tabla" [1] => "... tabla") [8] => Array( [0] => "border-s" [1] => "BORDES ...") ... [11] => Array( [0] => "border-e2" [1] => "...{borde ... tabla") ... (Hay hasta 74 encabezados, muchos contienen también las palabras "borde" y/o "tabla y que no mostramos para abreviar) ) ) [65] => Array( [u] => "/temas/xhtml-css/css-posicion.html" [t] => "..." [d] => "..." [k] => "..." [i] => Array( ... [6] => Array( [0] => "border-imagen" [1] => "...bordes ...") ... [25] => Array( [0] => "ejemplo-display-table" [1] => "... tablas ...") ... [38] => Array( [0] => "caption-side" [1] => "... tabla ...") ... ) ) [74] => Array( [u] => "/temas/xhtml-css/tabla.html" [t] => "... tablas" [d] => "... tablas ... bordes ..." [k] => "tabla ... bordes ..." [i] => Array( [0] => Array( [0] => "h0" [1] => "... TABLAS") ... [8] => Array( [0] => "table-border" [1] => "bordes de una tabla...>") ... (Hay unos 82 encabezados, muchos contienen las palabras "borde" y/o "tabla" también y que no mostramos para abreviar) ) )
Con la selección por documento se presentan estos 3 encontrados en la fase de búsqueda. Pero en la fase de extracción hemos de filtrar los encabezados del subcampo [i] que cumplan el patrón /borde|tabla/i. Veáse que este patrón, aunque es una alternativa, lo usamos también para filtrar con la opción de todas las palabras pues ya hicimos la selección con la intersección en la fase de búsqueda. Lo que estamos asegurando con la intersección es que esas dos palabras existen en el documento, aunque quizás no en el mismo apartado.
Pero cuando la búsqueda es por apartados estaremos buscando todas las palabras en cada apartado, entonces el patrón que se prepara es /borde.*?tabla/i para el caso de todas las palabras en ese orden. Esto significa que el documento 65 no cumple ese patrón, pues en ninguno de sus campos [u], [t], [d], [k] o en los subcampos [i] se encuentran al mismo tiempo esas dos palabras. Por lo tanto este documento 65 será descartado del array de documentos y no se presentará en los resultados. Si se descartan documentos se vuelve a sobreescribir la variable de sesión que guarda el array de documentos. Así si se solicitara una página de resultados que se obtuvo en un momento anterior, estos estarían ya filtrados.
En la búsqueda por apartados entonces mostraríamos los documentos 62 y 74, seleccionando los encabezados que contengan ambas palabras en ese orden en el mismo encabezado del subcampo [i]. En este caso ya no haría falta pasar el patrón a los subcampos [u], [t], [d], [k] pues todos estos acompañan siempre al resultado. Si no hubiese ningún encabezado coincidente, buscaríamos en los [u], [t], [d], [k] si hay coincidencia de ambas palabras. Si no hubiera coincidencia en ninguno se descartaría ese documento.
Esta tarea de filtrado y descartado posterior solo tiene efecto cuando usamos la opción por apartados, realizando un filtrado posterior a la selección por documento que en todos los casos se realiza en la fase previa de buscar documentos. Se va ejecutando a medida que el usuario va solicitando nuevas páginas de resultados de una búsqueda y, aunque se aplican expresiones regulares para el filtrado, estas sólo ocurren como mucho para 10 documentos. Así tenemos los tiempos de proceso de esta función extraer_pagina() controlados y limitados de alguna forma.
Al final esta función extraer_pagina() nos devuelve el array de resultados $arr_res siguiente con la opción de selección por documento y todas las palabras:
Array([0]=>Array([0]=>62 [1]=>Array([0]=>7 [1]=>8 ... )) [1]=>Array([0]=>65 [1]=>Array([0]=>6 [1]=>25 ... )) [2]=>Array([0]=>74 [1]=>Array([0]=>0 [1]=>1 ... )))
En amarillo están los números de documento. Por cada uno hay un array con la lista de encabezados que hemos cortado con puntos suspensivos para abreviar, conteniendo los índices de los encabezados del subcampo [i] del array índice web. Estos dos arrays se pasan para componer la página, proceso que es una continuación de este pero que hemos separado en otra función componer_pagina() para no complicar el código y tener claro que se hace en cada momento.
Por último exponemos el código de esta función extraer_pagina() para ver con detalle como aplicamos las expresiones regulares para el filtrado:
function extraer_pagina(&$arr_docs, $desde, $patron,
$indice_web, $palabras, $seleccion, $tipo_busqueda,
$sensible_mayusculas, $palabras_completas){
global $limite_tiempo;
global $cortado_en;
global $docs_pagina;
$error = false;
$arr_res = array();
$arr_docs_no_encontrados = array();
$docs_pag = $docs_pagina;
//Extraerá 1 página más para comprobar si, en caso de
//que no hayan exactamente $docs_pagina entonces es que aún hay más
if (!$_SESSION["escaneado"]) $docs_pag++;
$ini_time = microtime(true);
$n_bucle = 0;
$t_doc = count($arr_docs);
for($idoc=$desde; $idoc<$t_doc; $idoc++){
$n_bucle++;
if ((1000*(microtime(true) - $ini_time)) > $limite_tiempo) {
$cortado_en .= "extraer página, posición ".$n_bucle.
" en un bucle de ".$t_doc."posiciones";
break;
}
if (count($arr_res) == $docs_pag) break;
$n_doc = $arr_docs[$idoc];
if ($error) break;
if (array_key_exists($n_doc, $indice_web)){
$campos = $indice_web[$n_doc];
$hid = array();
if (array_key_exists("u", $campos)){
$encontrado = false;
if (array_key_exists("i", $campos)){
foreach($campos["i"] as $n_id => $arr_valor_id){
if (@preg_match($patron, $arr_valor_id[1])){
$hid[] = $n_id;
$encontrado = true;
}
if (!is_null(error_get_last())) {
$error = true;
break 2;
}
}
}
if ($seleccion == "documento"){
//En la selección por documento se da por encontrado
//en todo caso todos los buscados con buscar_docs()
$encontrado = true;
} else {
if ((!$encontrado) && (array_key_exists("k", $campos)) &&
(@preg_match($patron, $campos["k"]))) $encontrado = true;
if (!is_null(error_get_last())){
$error = true;
break;
}
if ((!$encontrado) && (array_key_exists("d", $campos)) &&
(@preg_match($patron, $campos["d"]))) $encontrado = true;
if (!is_null(error_get_last())){
$error = true;
break;
}
if ((!$encontrado) && (array_key_exists("t", $campos)) &&
(@preg_match($patron, $campos["t"]))) $encontrado = true;
if (!is_null(error_get_last())){
$error = true;
break;
}
if ((!$encontrado) &&
(@preg_match($patron, $campos["u"]))) $encontrado = true;
if (!is_null(error_get_last())){
$error = true;
break;
}
}
if ($encontrado){
if (!empty($hid)){
$arr_res[] = array($n_doc, $hid);
} else {
$arr_res[] = array($n_doc);
}
} else {
$arr_docs_no_encontrados[] = $n_doc;
}
}
}
}
if (count($arr_docs_no_encontrados)>0) {
//Eliminamos los no encontrados
$arr_docs = array_diff($arr_docs, $arr_docs_no_encontrados);
}
return $arr_res;
}Destacamos algunos detalles:
- Si el conjunto de resultados no está totalmente escaneado, lo que se aplica para la opción de búsqueda por apartados, entonces extraemos un resultado más, es decir, 11 resultados, con objeto de saber si hay más páginas que escanear.
- Iniciamos un contador de tiempo pues vamos a controlar aquí también el bucle de iteración.
- Hacemos un bucle desde la posición del documento pasada en el argumento de la función, que se corresponde con el primero de la página solicitada. El final queda abierto, es decir, hasta el último del array de documentos, pues si estamos filtrándolos seguiremos en el bucle hasta que consigamos 11 resultados.
- Si el array de documentos es excesivamente largo y hay numerosos descartes, el bucle puede estar ejecutándose más tiempo del que podamos permitirnos. Por eso controlamos esto con la misma limitación de 100 ms que hicimos para la función de buscar documentos.
- Cuando tengamos los 11 resultados rompemos el bucle con
break. - Buscamos el documento en el índice web y comprobamos el patrón en todos los encabezados del subcampo
[i]. Esto lo hacemos tanto en la opción de selección por documento como por apartados. - Observe que todas las expresiones regulares se aplican con
@preg_matchbuscando sólo la primera coincidencia y además el patrón no tiene subexpresiones de captura, todo esto con objeto de reducir los tiempos de ejecución. Además evitamos que se muestren errores con@y los controlamos con la función de PHPerror_get_last(). Ante cualquier error de patrón salimos de todos los bucles. - Si la selección es por documento ya no buscamos en el resto de apartados. En otro caso lo vamos haciendo de forma gradual, es decir, si no se ha encontrado previamente en los apartados por el orden
[i],[k],[d],[t]y[u]. En cuanto se encuentre en alguno ya no aplicará el patrón al resto de apartados. Este orden obedece a la importancia de la información en cada apartado. Es razonable pensar que primero busquemos en los encabezados pues se aplica en ambas opciones de selección. El subcampo[u]será el último pues si bien alguno o todos los anteriores pudieran no aparecer en el índice web para un documento, este en cambio si es el mínimo obligatorio. - Si el documento fue encontrado se agrega al array de resultados
$arr_res. En otro caso los vamos acumulando a un array temporal de no encontrados. Al final quitaremos todos estos del array de documentos usando la función PHParray_diff()
La función para componer página
Esta función componer_pagina() tiene la siguiente declaración:
function componer_pagina($arr_res, &$indice_web, $pagina, $patron, $palabras, $tipo_busqueda, $sensible_mayusculas, $palabras_completas)
La función para componer página no merece mayor atención. Se trata simplemente de tomar el array con los 10 resultados y formatearlos con HTML literal para ser enviados al usuario. Se usan el patrón del filtrado para resaltar las coincidencias y también se construye una botonera navegadora entre páginas.
En esta composición de la botonera tenemos en cuenta si la opción de selección es por apartados, que es cuando pueden producirse los descartes de resultados al aplicar el patrón de búsqueda a los distintos apartados de un documento. En esta captura de pantalla de una búsqueda con las opciones selección por apartados y todas las palabras en cualquier orden, vemos que con la primera página siempre aparece la botonera incluyendo sólo un botón para la página 1 y otro con la flecha derecha para seguir paginando:

La función buscar_docs() extrajo 28 documentos que se almacenaron en el array de documentos. Entonces en principio se paginarán en 3 páginas pues cada una lleva 10 documentos (la última tendría 8). Si bien para la primera página tenemos los 10 filtrados e incluso que habrá una página siguiente pues siempre filtramos los 11 resultados siguientes con el propósito de saber si existe otra página, lo que aún no sabemos es si el resto de resultados pasarán el filtro del patrón de encontrar las dos palabras en el mismo apartado en cualquier orden. Por eso sólo aparece la flecha a la derecha y la frase "filtradas hasta el momento de un total de 3 páginas" . Solicitamos la siguiente página:

En la segunda página tampoco hubieron descartes y aún queda la última:
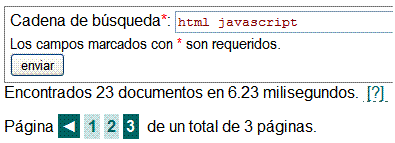
Vemos que 5 resultados fueron descartados y ya no es necesaria la flecha derecha pues hemos llegado al final. Esto lo podemos saber en la función de composición pues la variable $_SESSION["escaneado"] tendrá un valor true que se originó al realizar el filtrado con la función extraer_pagina().
En el último tema que sigue se habla de algunas particularidades como el algoritmo para hacer permutaciones y detalles sobre el control de los tiempos de ejecución y como podrían mejorarse si crece el tamaño de los índices.