Construir índices de los buscadores
Descarga
Los recursos para construir el índice de encabezados con Javascript y el índice de palabras así como un buscador interno de prueba con PHP se encuentran en la carpeta comprimida descarga.zip. Como el resto de aplicaciones que he desarrollado en este sitio wextensible.com puede copiar, usar, modificar y distribuir la copia resultante siempre que aplique este mismo principio de licencia de uso a la copia resultante. Esta descarga contiene lo siguiente:
- Archivos de la herramienta para construir índices:
- index.php.txt, que tras suprimir la extensión .txt será la herramienta que nos permite construir los índices.
- indexa.php.txt, suprimir .txt para tener el script que junto al anterior nos permite construir los índices.
- indice.txt, un archivo de texto donde se construye el índice de encabezados para el buscador Javascript o bien el índice previo para el buscador PHP. Inicialmente está vacío.
- indice-web.txt, un archivo de texto inicialmente vacío donde se guardarán el índice web para el buscador PHP.
- indice-claves.txt, un archivo de texto inicialmente vacío donde se guardarán el índice de claves para el buscador PHP.
- Archivos del buscador PHP:
- buscador-indices.php.txt, tras eliminar la extensión .txt tenemos el script del buscador de índices PHP.
- buscador.php.txt, sin la extensión .txt tenemos la página php/html para probar el buscador de índices PHP.
La herramienta para construir índices está pensada sólo para usar en un servidor localhost, de tal forma que los archivos de texto de los índices construidos se subirán al servidor. De todas formas para probar todo esto puede descargar todo el contenido en alguna carpeta de su localhost y empezar a realizar pruebas.
Herramienta para construir índices
Tanto para el buscador de encabezados con Javascript como para el buscador de índice de palabras con PHP, necesitamos crear previamente los índices. He preparado esta herramienta PHP para usar en un servidor local para este cometido. No debe usarse en un servidor real pues no está preparado desde el punto de vista de la seguridad. Al fin y al cabo lo único que queremos es obtener unos archivos de texto con los índices, archivos que luego subiremos al sitio real. En este apartado explico el funcionamiento para usar esta herramienta, pero no sus propios detalles de construcción.
Veámos unas capturas de pantallas para verla en funcionamiento:
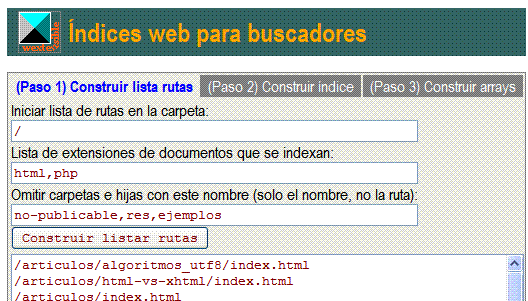
Se trata de un proceso en 2 fases para obtener el índice de encabezados del buscador Javascript y de una fase más para obtener los arrays de los índices del buscador PHP. La primera fase siempre es para obtener una lista de rutas de documentos de nuestro sitio. Lo hacemos sobre los documentos que tenemos en localhost. Todas las rutas se referencian desde una carpeta de inicio. Ponemos "/" para indicar que comience a buscar documentos a partir de la carpeta raíz, si fuera el caso. O bien podemos sólo listar rutas para una carpeta. El proceso es recursivo de tal forma que busca en esa carpeta y en sus hijas de forma recursiva.
define("RAIZ", $_SERVER["DOCUMENT_ROOT"]); que apuntará a esa carpeta. Si por ejemplo nuestro sitio en localhost está en la carpeta C:/web/sitio (en Windows) entonces la carpeta raíz quedaría como C:/web/sitio/.En los campos donde haya de rellenarse una lista de expresiones, estas deben separarse por una coma sin espacios entre las comas. Es el caso de la lista de extensiones de los documentos que queremos indexar. En este caso son documentos estáticos como html o bien semiestáticos como php. Hay que tener presente que estos últimos deben ser verdaderos HTML aunque incorporen partes de script para procesar algún trozo del HTML. De hecho los script PHP puros, es decir, los que no lanzan HTML, deberían ubicarse fuera de la carpeta raíz por motivos de seguridad, por lo que no deberíamos encontrar ninguno de estos.
Si tiene dudas acerca de las extensiones php no las incluya. Hay que tener en cuenta que el constructor de índices aplica la función PHP get_meta_tags() para obtener los elementos de metainformación como title, description y keywords. Además también usamos expresiones regulares para obtener el elemento <meta http-equiv="content-type" content="text/html; charset=UTF-8" /> y saber la codificación del documento y, por otro lado, para obtener los encabezados h1 a h6. Por lo tanto si el documento es .php, al menos estos elementos deben ser HTML puro, sin mezclar con código PHP.
Es importante entender que en un PHP se puede lanzar un elemento HTML como por ejemplo echo "<h1>Encabezado</h1>"; que escribe un elemento de encabezado en la página. Esto es desaconsejable porque entonces no podemos procesar ese documento PHP como un HTML. En ese caso bastaría con poner <h1>Encabezado</h1> sin la orden echo y el resultado es el mismo. Así que todos los encabezados o metainformación que no sean HTML puro no podrán ser indexados con esta herramienta.
Yo trabajo con un entorno de programación donde tengo los mismos documentos de este sitio con la misma estructura. Las modificaciones que hago en localhost luego las subo al sitio real. Todo lo que hago en localhost que no quiera subir al sitio real lo ubico en una carpeta llamada no-publicable. Además he estructurado el sitio para incluir en carpetas denominadas res todos los recursos de imágenes, script, etc. Por otro lado los ejemplos que se exponen con la teoría también los ubico en carpetas de ejemplos. Así en cualquier nivel donde se encuentren carpetas con este nombre y sus hijas no serán incluidas en el recursivo que lista la rutas.
Esto obedece a la estructura que actuamente tengo pero no será la misma para su sitio. Por ejemplo, no incluyo los documentos de ejemplo pues no aportan nada al buscador. Pero si su sitio tiene otra estructura quizás deba modificar ese script para adaptarlo. En todo caso la lista de rutas se construye y se presenta en el área de texto inferior de la herramienta, pero no se guarda en ningún archivo pues sólo la necesitamos como base para el siguiente paso. En este momento puede eliminar las rutas que considere si no desea indexar esos documentos.
Construir índice de encabezados para buscador Javascript
El segundo paso nos permite usar la lista de rutas anterior y construir el índice de encabezados (con esa opción tal como se ve en esta imagen) o bien un índice previo para el buscador PHP (con la opción "completo" que veremos en el siguiente apartado).
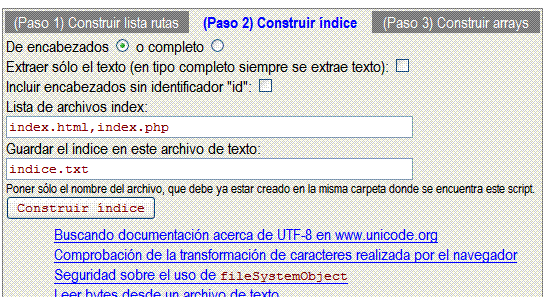
Esta imagen captura el proceso de buscar encabezados <h1> a <h6> en los documentos de la lista de rutas. Observamos la opción de extraer sólo el interior de esos elementos cómo sólo texto o como HTML. Por ejemplo, si un encabezado es <h1>AB<i>CD</i>EF</h1>, con la opción de sólo texto obtenemos ABCDEF eliminando el elemento interior, pero sin esa opción obtenemos el literal interior completo.
El objeto de este buscador es indexar encabezados identificados, pues así obtenemos unos resultados que apuntan al vínculo interior. Pero en todo caso podemos indexarlos sin que tengan ese atributo id de tal forma que el vínculo construido apuntará al documento en lugar de al encabezado.
Los archivos index son los que por defecto se abren en nuestro sitio cuando la URL es una carpeta. Así en un documento de la lista de rutas como /articulos/algoritmos_utf8/index.html se detecta el index.html de tal forma que la ruta final se construirá como /articulos/algoritmos_utf8/#seguridad eliminándose el archivo index (ese ruta es para el vínculo "Seguridad sobre el uso de fileSystemObject" que se observa en la imagen anterior).
El índice de encabezados se guarda como texto en un archivo cuyo nombre hemos de declarar (indice.txt en la imagen). Sólo hemos de poner el nombre del archivo, pues se ubicará en la misma carpeta donde se encuentra esta herramienta. El resultado mostrado en la imagen es ese índice en formato HTML para probar su funcionamiento, pues el archivo de texto contendrá algo como lo que vimos en un tema anterior, aunque cada entrada estaría en una única línea:
...
<div id="cabecera" class="item">
...
<div style="text-indent:3em">
<a href="/temas/xhtml-css/cabecera.html#h0" class="h0">
Elementos XHTML de cabecera
</a>
</div>
...
</div>
...Sólo resta copiar el contenido de ese archivo y ponerlo en el documento que maneja el buscador, dentro del elemento con id="indiceContenidos":
<div id="resultados"></div>
<div id="indiceContenidos">
...PEGAR AQUÍ EL ÍNDICE...
</div>Construir índice de palabras para buscador PHP
Si vamos a construir un índice de palabras para el buscador PHP usamos la opción de índice completo. La siguiente opción siempre será sólo texto esté o no desactivada esa casilla.
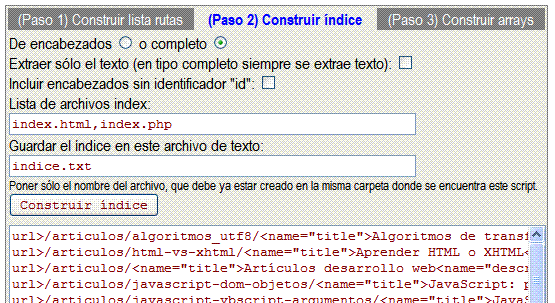
Ahora el contenido del archivo indice.txt y lo que muestra el área de texto es lo mismo. Se trata de líneas de texto donde cada una es para un documento de la lista de rutas. Por ejemplo, la primera línea contiene esto:
url>/articulos/algoritmos_utf8/< name="title">Algoritmos de transformación UTF-8< name="description">Saber como funciona la codificación...< name="keywords">unicode, utf-8, utf8, utf 8,...< id="ap0">Buscando documentación acerca de UTF-8 en...< id="ap1">Comprobación de la transformación de...< id="seguridad">Seguridad sobre el uso de fileSystemObject< id="leer-bytes">Leer bytes desde un archivo de texto< ...el final es un salto de línea
Todo esto es lo que está en la primera línea, que hemos separado en varias líneas aquí para poder explicarlo (también suprimimos texto con los puntos suspensivos). En definitiva se trata de los campos url, title, description, keywords y los propios encabezados separados por el caracter "<". Dentro de cada campo se separan los subcampos con el caracter ">". Usar estos caracteres es porque dentro de los textos de cada campo nunca podrán estar estos pues siempre extraemos los interiores de los encabezados como sólo texto.
El siguiente paso es construir los arrays del índice:
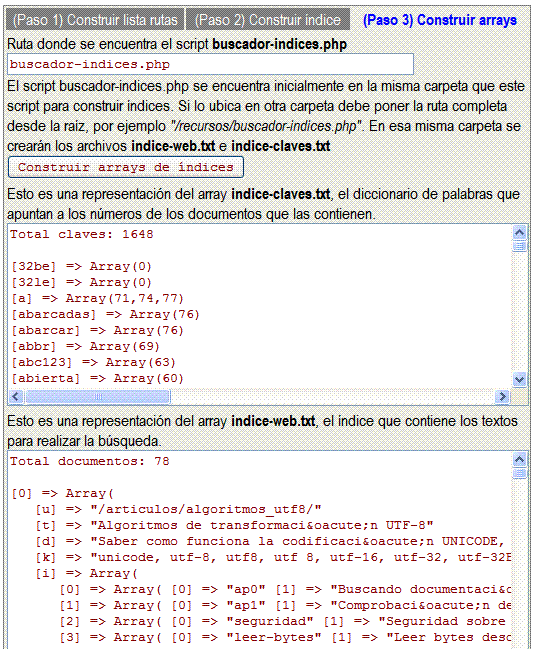
Hay que especificar donde se encuentra el script buscador-indices.php. Inicialmente con la descarga de archivos se ubica en el mismo sitio que esta herramienta, pero quizás luego lo ubique en su sitio definitivo. Si es así debe poner la ruta relativa a la raíz del sitio. Se generan los archivos de texto indice-web.txt e indice-claves.txt que son la serialización de los arrays de índices. Como prueba se ponen en las áreas de texto una representación de esos arrays, aunque lo que se guarda en los archivos son los mismos serializados.
En el borde inferior de la herramienta hay un vínculo que le permite lanzar el buscador PHP de ejemplo incluido en la descarga y probar el buscador:
Una vez construido los índices de palabras pasamos al siguiente tema que explica el funcionamiento del buscador.php basado en el script buscador-indices.php y manejando los archivos de índices indice-claves.txt e indice-web.txt.