Strings en JavaScript ES6
El tipo string y el objeto String
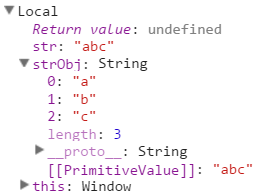
str de tipo string y otra strObj creada con el constructor String. Cuando nos iniciamos en JavaScript una de las cosas que más nos preocupa es la frase en JavaScript todo son objetos
. Cuando hacemos algo como let str = "abc"; para declarar una variable de tipo string, podemos preguntarnos dónde están ahí los dichosos objetos. Pues sí, está actuando de forma implícita el objeto String, con "S" maýuscula para diferenciarlo del tipo string. Este String y otros como Number o Boolean son los objetos built-in, estándar o intrínsecos de JavaScript.
En primer lugar las variables en JavaScript no tienen tipos, sólo los valores los tienen. Si hacemos let str; habremos declarado una variable sin tipo definido. Mejor dicho, JavaScript le adjudica realmente el valor undefined, otro objeto built-in cuyo tipo es undefined. Así console.log(str) nos devuelve el objeto undefined y console.log(typeof str) nos devuelve el tipo, la cadena "undefined". Es importante entender la diferencia entre el built-in y el tipo devuelto por typeof, que siempre es un string.
Por otro lado haciendo let str = "abc"; la variable toma un valor con tipo string. Lo anterior es lo que denominamos una declaración literal de una variable. Pero en el fondo la creación de un tipo de valor string supone que JavaScript aplique el constructor del objeto String. Así la declaración y asignación anterior es en última instancia let str = new String("abc");.
Aunque podemos usar el objeto String para crear la cadena "abc", esto no es recomendable. Porque hay unas diferencias muy importantes que debemos tener en cuenta. En el siguiente código podemos observar que el tipo del objeto String es function, que es a su vez un objeto. La variable strObj contiene ahora un tipo object, no un tipo string. Vea como obtenemos acceso a su constructor, la función String() que nos permite crear los valores. La variable contiene un objeto con posiciones para cada uno de sus caracteres, un propiedad length que almacena la longitud y finalmente el PrimitiveValue con el valor almacenado. Finalmente podemos acceder al carácter "b" que se encuentra en la posición 1.
//String es un tipo function
console.log(typeof String); // function
//Un string creado con el constructor String
let strObj = new String("abc");
console.log(strObj.constructor); // function String() { [native code] }
console.log(typeof strObj); // object
console.log(strObj); // String {0: "a", 1: "b", 2: "c", length: 3, [[PrimitiveValue]]: "abc"}
console.log(strObj[1]); // b
En cambio si hacemos lo mismo para una declaración literal observamos que ahora también la variable tiene el mismo constructor pero el tipo es ahora string y no object. La variable contiene ahora "abc" y no un objeto. Pero de igual forma podemos acceder al carácter "b" en la posición 1. Esto es porque el valor "abc" realmente está sustentado por el objeto String que usó JavaScript para crear ese valor.
//Un string literal
let str = "abc";
console.log(str.constructor); // function String() { [native code] }
console.log(typeof str); // string
console.log(str); // abc
console.log(str[1]); // b
El problema de la diferencia de tipos entre ambas declaraciones se manifiesta claramente cuando intentamos comparar ambas variables:
//Comparando ambas variables
console.log(str === strObj); // false
console.log(str == strObj); // true
console.log(str === strObj.toString()); //true
Con una comparación estricta "===" vemos que ambas variables no son iguales. Si usamos una comparación "==" que incluye coerción vemos que la comparación es correcta. Esto es debido a que JavaScript coerciona strObj al tipo string de str. El mismo resultado se obtendría al aplicar el método toString() al objeto y entonces compararlos.
Por lo tanto y aunque tenemos la posibilidad de usar los constructores de los objetos built-in, no siempre es recomendable usarlos y en su lugar utilizar declaraciones literales de variables.
Los métodos estáticos de String

Vimos antes que el objeto String sustenta un valor como "abc" aunque hayamos usado una declaración literal de la variable. Debemos entender eso para saber que el valor de cadena "abc" tiene disponible todos los métodos del objeto String.
Por ejemplo, typeof "abc".toUpperCase nos devuelve function pues toUpperCase() es un método del objeto String para convertir en mayúsculas las letras de la cadena de texto. Por lo tanto "abc".toUpperCase() nos devolverá la cadena "ABC".
El método toUpperCase() y otros muchos están dentro del objeto prototype del objeto String (ver Figura). Pero antes de meternos con esos métodos veámos porqué hay algunas funciones que están por fuera del prototipo:
fromCharCode([code1[, code2[, ...[, codeN]]]]): Devuelve un string partiendo de uno o más valoresUnicode. Por ejemplo,String.fromCharCode(97, 98, 99)nos devolverá"abc", pues esos son los valores Unicode para esos caracteres. Esta función existe desde la versión ES1, es decir, desde la primera versión de JavaScript.fromCodePoint(). Es una nueva función que se introduce en ES6 que hace lo mismo que la anterior, pero que permite valores Unicode superiores aFFFF(216). En varios apartados más abajo explicaremos más detalles sobre el nuevo soporte de ES6 para Unicode.raw(), función nueva de ES6 que devuelve un string con los caracteres realmente escritos. Vea este código:console.log('abc\tdef'); // abc def console.log(String.raw`abc\tdef`); // abc\tdefUn escape tabulador
\ten JavaScript se convierte en el espacio de tabulación. Pero conString.rawseguido de un plantilla literal (template literal) extraemos los caracteres reales tal como fueron escritos. Esto nos da una primera idea del método, pero requiere una exposición más extensa en otro tema.
Lo importante ahora es entender que son tres funciones para construir cadenas de texto. Por lo tanto al ejecutarlas JavaScript está creando nuevos string y, por tanto, aplicando el constructor de String. Por eso son métodos estáticos y no del prototipo de String.
Los métodos del prototipo de String
__proto__. Cuando el constructor de String crea una variable de tipo string copia su prototipo en la instancia implícita creada, apareciendo como __proto__, tal como se observa en la Figura. Se trata de una propiedad interna de los objetos, no ideada en principio para manipular externamente. En la documentación a veces lo vemos escrito como [[prototype]]. Hay muchos métodos en el prototipo y sería interesante listar las disponibles en el navegador actual. Pero las propiedades y métodos de los prototipos no son enumerables, por lo que no podemos extraerlos usando un típico bucle for in.
Recuerde que podemos crear objetos en JavaScript y usando defineProperty/ies dotar a sus propiedades de las características enumerable, writable y configurable. Pues bien, los prototipos resultan ser siempre no enumerables, aunque eso no quiere decir que no podamos acceder a sus miembros. Para conseguir esa lista vamos a usar este código que se ejecuta en el siguiente ejemplo al pulsar el botón:
wxL.iterarPrototipoString = function() {
"use strict";
let proto = Object.getPrototypeOf(new String(""));
let names = Object.getOwnPropertyNames(proto);
names.sort();
let lista = "";
for (let i=0; i<names.length; i++) {
let name = names[i];
lista += '<li><code>' + name + '</code>: ' + typeof proto[name] + '</li>';
}
const lms = document.getElementById("lista-metodos-string");
lms.style.height = "15em";
lms.innerHTML = '<ol>' + lista + '</ol>';
};
Con getPrototypeOf accedemos a __proto__ de un objeto string vacío (o cualquier string, es indiferente). En ES5 el argumento debe ser necesariamente un objeto, pero en ES6 es posible pasar una string literal pues JavaScript lo coerciona a un objeto. Al menos en Chrome 48 y Firefox 44, porque en IE11 da error.
A continuación con getOwnPropertyNames obtenemos todos los nombres de propiedades de un objeto, enumerables o no. Las ordenamos alfabéticamente y luego iteramos por ellas para extraer el nombre de la propiedad y su tipo en __proto__.
Ejemplo: Métodos String en este navegador
en este navegadorEn los navegadores consultados todas las entradas son tipo function a excepción de la propiedad length que nos da la longitud del string. Actualmente puedo ver que hay 43 entradas en Chrome, 45 en Firefox y 35 en IE11.
En el siguiente ejemplo interactivo puede probar los métodos de String en su navegador. En el resto de apartados de este tema se explican los pormenores de cada método. Cada explicación también se expondrá al ejecutar el método en este ejemplo.
Ejemplo: Métodos del prototipo de String
- Código que se ejecuta:
- Resultado es :
Métodos String para construir elementos HTML
Desde la primera versión de ES1 se consideró necesario métodos para construir literales HTML, pues con algo como "abc".big() obteníamos el literal HTML "<big>abc</big>", que posteriormente podríamos incluir en el DOM con algún método como innerHTML. Pero esto tiene una corta utilidad, en parte porque no se contemplan todos los elementos HTML posibles y además muchos de ellos ya no se usan. La lista de los que se considerarán obsoletos en ES6, aunque es posible que funcionen aún en los navegadores por razones de compatibilidad, son: big, blink, bold, fixed, fontcolor, fontsize, italics, small, strike, sub y sup. Siguen considerándose anchor(name) y link(href).
anchor(name)
Devuelve un string literal del elemento ancla de HTML <a name>, donde el argumento name pasa a ser su atributo del mismo nombre.
link(href)
Devuelve un string literal del elemento vínculo de HTML <a href>, donde el argumento href pasa a ser su atributo del mismo nombre.
Métodos String para consultar posiciones de caracteres y UNICODE
En JavaScript podemos escapar caracteres con \x00 hasta \xFF cubriendo los primeros 256 de ASCII extendido. Si queremos ampliar el rango hemos de usar escapes Unicode. Desde las primeras versiones contemplaban caracteres hasta FFFF (65535 en decimal). Son, por tanto, necesarios 2 bytes para presentar un carácter. Así podíamos (y aún podemos) escapar caracteres con los escapes \u0000 hasta \uFFFF.
Pero el total de Unicode llega hasta 10FFFF (1114111 en decimal). JavaScript maneja Unicode sólo con UTF-16, por lo que para completar el alcance hasta el total de Unicode se utilizan las transformaciones UTF-16. Las 2048 posiciones Unicode D800 a DFFF son reservadas para ese propósito. Por lo tanto para escapar un carácter superior a FFFF se necesitan dos escapes seguidos llamados pares subrogados.
Para ampliar los escapes de JavaScript ahora ES6 permite usar \u{000000} hasta \u{10FFFF} con lo que ya no necesitaremos poner dos escapes seguidos en nuestro código, tras la necesaria transformación a UTF-16. Veámos el siguiente ejemplo presentando un Unicode en la posición decimal 128274, hexadecimal 1F512 y con transformación UTF-16 D83D DD12. Puede ver este carácter, un icono de un candado cerrado, en la página de tablas Unicode Unicode-table:
Ejemplo: Unicode y JavaScript
- Escape HTML hexadecimal
🔒🔒 - Escape HTML decimal
🔒🔒 - Escape en UTF-16 hasta ES5
\uD83D\uDD12 - Escape sin transformar a partir de ES6
\u{1F512}
\u{1F512} son soportados por CH48+, FF44+ e IE12+.Los dos primeros son escapes HTML que hemos presentado directamente en la página. Los siguientes los cargamos con JavaScript usando el botón que insertará el escape de ES5 o ES6 correspondiente. Lo hacemos así para evitar posibles no soportes de navegadores con el nuevo escape de ES6. Todo esto es sólo para dar una idea general de cómo JavaScript maneja Unicode y presentar los métodos relacionados a continuación.
charAt(posicion)
Devuelve un string con el carácter en la posición especificada. Si la posición no existe devuelve una cadena vacía. Otra forma de obtener un único carácter sería accediendo como si fuera un array, por ejemplo, si str es un string, con str[pos] obtenemos el carácter en esa posición. O también con str.substring(pos, pos+1).
Dado que las primeras versiones de ES sólo contemplaban códigos Unicode hasta 216 (65535 en decimal o FFFF en hexadecimal), este método no devolvería el carácter adecuado con valores de Unicode superiores. ES6 no contempla otro método para arreglar esto, como hace por ejemplo con charCodeAt y el nuevo codePointAt. Podríamos hacer String.fromCodePoint(str.codePointAt(pos)) para obtener un carácter con cualquier Unicode, usando el método estático String.fromCodePoint() que comentamos más arriba.
En el ejemplo "a\u260Ec".charAt(1) recuperamos el carácter "\u260E" en la segunda posición de la cadena "a☎c", carácter que tiene el código 9742 inferior a 65536.
charCodeAt(posicion)
Devuelve un tipo number número entero no negativo menor que 216 (65536) que es el código Unicode del carácter en la posición indicada por el argumento. Las posiciones empiezan desde cero. Si esa posición no existe en la cadena se devuelve el tipo NaN.
En el ejemplo "a\u260Ec".charCodeAt(1) tenemos la cadena con tres caracteres: "a", "\u260E" y "c". El segundo carácter es el escape en JavaScript para "☎", el código Unicode 9742, 260E en hexadecimal, que representa un icono de un teléfono. Estamos buscando el código Unicode de esta segunda posición en la cadena (posicion = 1). Con JavaScript hasta ES5 podíamos representar un Unicode desde "\u0000" hasta "\uFFFF" (total 65536 posiciones).
Para obtener Unicodes cualesquiera hay que usar el nuevo método codePointAt() de ES6, donde podemos usar la nueva forma desde "\u{000000}" hasta "\u{10FFFF}", que es el valor más alto de Unicode (1114111). Hay más información que explica los rangos de Unicode en el tema algoritmos de transformación UTF-8.
codePointAt(posicion)
Devuelve un number entero no negativo menor o igual que 1114111 (máximo valor de Unicode) del carácter en la posición del argumento. Si la posición no existe devolverá undefined. Este nuevo método de ES6 se ha de utilizar en lugar de charCodeAt() para recuperar cualquier Unicode.
En el ejemplo "a\u{1F512}c".codePointAt(1) recuperamos el segundo carácter "\u{1F512}" de la cadena "a🔒c", cuyo código 128274 (un icono de un candado cerrado) es superior a 65535. Observe como en ES6 escribimos el hexadecimal Unicode entre llaves.
normalize([forma])
Devuelve un string con la Forma Normalizada Unicode (Unicode Normalization Form) de un string dado. Un uso del método es con el argumento "NFKD" que intentaré explicar a continuación.
Ciertos caracteres Unicode agrupan varios en un único carácter. Por ejemplo, el carácter "fi" es la posición Unicode FB01 y representa la ligadura de los caracteres "f" e "i". Vea el siguiente ejemplo:
let texto = "Era una gran \uFB01esta.";
console.log(texto); // Era una gran fiesta.
texto = texto.normalize("NFKD");
console.log(texto); // Era una gran fiesta.
let bus = texto.match(/\bfiesta\b/);
console.log(bus); // ["fiesta", index: 13, input: "Era una gran fiesta."]
Normalizamos el texto para deshacer la ligadura "fi" con los dos caracteres "fi" y así poder aplicar el patrón de búsqueda con éxito. El argumento del método usado para esto ha sido "NFKD", permitiendo también otros tres valores "NFC", "NFD" y "NFKC". El argumento es opcional, siendo "NFC" el valor por defecto. Lo anterior nos da una idea general de la finalidad de este método, sin entrar en más detalle dado que es necesario previamente entender el Anexo 15 de la especificación Unicode denominada Unicode Normalization Forms.
Métodos String para búsquedas y sustituciones
Una de las tareas más comunes que haremos con cadenas de texto es realizar búsquedas y sustituciones. Los métodos indexOf() o lastIndexOf() ya existían desde ES1. En ES3 se introdujeron los Métodos de JavaScript para expresiones regulares como search(), match(), replace() y split(). Ahora con ES6 se incorpora includes(), startsWith() y endsWith().
indexOf(busqueda[, desde])
Devuelve un number de la posición donde se localiza la cadena del primer argumento. Las posiciones siempre cuentan desde cero. Si no se encuentra devolverá -1. El segundo argumento es opcional y establecerá desde donde empezará a buscar. Por defecto será la posición cero. Por ejemplo, "abc".indexOf("bc") nos devuelve la posición 1 donde se encuentra la primera aparición de "bc".
lastIndexOf(busqueda[, desde])
Devuelve un number de la posición donde se localiza la cadena del primer argumento. La diferencia con indexOf() es que éste empieza a buscar desde la posición del segundo argumento hacia adelante, mientras que lastIndexOf() lo hace hacia atrás. El valor por defecto del segundo argumento será la última posición en la cadena. Por ejemplo, "bcabc".lastIndexOf("bc") nos devuelve la posición 3 donde encontramos la última aparición de "bc".
includes(busqueda[, desde])
Devuelve un boolean para comprobar si una cadena de búsqueda está contenida en otra en cualquier posición, tomando la cadena que empieza en la posición del segundo argumento. Éste es opcional con valor cero por defecto. Por ejemplo "abcd".includes("bc") nos da verdadero.
startsWith(busqueda[, desde])
Devuelve un boolean para comprobar si una cadena de búsqueda está contenida en otra, tomando como inicio de comprobación la posición del segundo argumento opcional, cuyo valor por defecto es cero. Por ejemplo, "abc".startsWith("bc") nos daría falso, pues no empieza por esa cadena. Lo mismo podría conseguirse con "abc".substr(0, 3) === "bc" aplicando el método substr().
endsWith(busqueda[, longitud])
Devuelve un boolean para comprobar si una cadena de búsqueda está contenida en otra, tomando como final de comprobación la longitud del segundo argumento opcional, cuyo valor por defecto es la longitud de la cadena que se tendrá en cuenta empezando por el último carácter. Por ejemplo, "abc".endsWith("bc") nos daría verdadero pues finaliza así. Al omitir el segundo argumento es como incluirlo con valor 3, que es la longitud de la cadena "abc".
localeCompare(con[, locales[, opciones]])
Devuelve un number positivo, negativo o cero para comparar el orden entre la cadena y el primer argumento. Por ejemplo, "abc".localeCompare("az") nos devuelve un número negativo (-1) para indicar que "az" es alfabéticamente posterior a "abc". Si fuera anterior nos devolvería positivo, cero si ambos son iguales. Los argumentos opcionales no son soportados totalmente por los navegadores. Introducen adaptaciones para la internacionalización al idioma usado, por ejemplo "es" para español en locales. Para entender esos argumentos es necesario ampliar la información, pudiendo empezar por la página de Mozilla que habla sobre el objeto built-in Intl.
search(regexp)
Devuelve un number con la posición encontrada en la cadena al aplicar la expresión regular de su argumento. Éste puede también ser un string, en cuyo caso se convertirá implícitamente en una expresión regular con new RegExp(). Si no se encuentra coincidencia devolverá -1. Con "abab".search(/b/) obtendremos la posición 1 donde encontramos la primera aparición de "b". Este método es equivalente a indexOf() pero con la particularidad de permitir expresiones regulares.
Puedes ver más sobre los métodos que usan expresiones regulares search(), match(), replace() y split() en el tema Métodos de JavaScript para expresiones regulares.
match(regexp)
Devuelve un object construido con el built-in Array con las coincidencias encontradas por el patrón de expresión regular del argumento. Éste puede también ser un string, en cuyo caso se convertirá implícitamente en una expresión regular con new RegExp(). El ejemplo "abab".match(/b/g) nos devolverá el array ["b", "b"] pues encontró dos apariciones de "b" en la cadena. Con "abab".match("b") se convierte el argumento en new RegExp("b"), por lo que la búsqueda no será global, es decir, tendríamos "abab".match(/b/) buscándose sólo la primera aparición y devolviendo el array ["b"].
Puedes ver más sobre los métodos que usan expresiones regulares search(), match(), replace() y split() en el tema Métodos de JavaScript para expresiones regulares.
replace(regexp, con)
Devuelve un string con las sustituciones del segundo argumento encontradas por la expresión regular del primer argumento. Éste puede también ser un string, en cuyo caso se convertirá implícitamente en una expresión regular con new RegExp(). El segundo argumento podría ser también una función a modo de callback. Con "abc".replace(/b/g, "x") sustituímos todas las apariciones de "b" por "x".
Puedes ver más sobre los métodos que usan expresiones regulares search(), match(), replace() y split() en el tema Métodos de JavaScript para expresiones regulares.
split(regexp[, limite])
Devuelve un object de Array dividiendo la cadena por el separador del primer argumento. Éste puede también ser un string, en cuyo caso se convertirá implícitamente en una expresión regular con new RegExp(). El segundo argumento nos limitará el número de posiciones del array que van a recuperarse. Como ejemplo "a,b,c".split(/,/) obtenemos el array ["a", "b", "c"].
Puedes ver más sobre los métodos que usan expresiones regulares search(), match(), replace() y split() en el tema Métodos de JavaScript para expresiones regulares.
Métodos String para edición de cadenas
Los métodos siguientes nos permiten la edición de cadenas. Siempre hemos de tener en cuenta que el método no modifica la cadena sobre la que se aplica, sino que devuelve la modificación. Así let miVar = str.toLowerCase() nos devuelve en la variable miVar la cadena de str convertida a minúsculas, sin que str resulte alterada.
toLowerCase()
Devuelve un string con la cadena convertida a minúsculas. Por ejemplo "ABC".toLowerCase() nos devuelve la cadena "abc". Existe otro método toLocaleLowerCase() cuyo uso se destina a idiomas específicos, pero usualmente no en los occidentales, donde ambos métodos producen el mismo resultado.
toUpperCase()
Devuelve un string con la cadena convertida a mayúsculas. Por ejemplo "abc".toUpperCase() nos devuelve la cadena "ABC". Existe otro método toLocaleUpperCase() cuyo uso se destina a idiomas específicos, pero usualmente no en los occidentales, donde ambos métodos producen el mismo resultado.
concat()
Devuelve un string concatenando la cadena y el argumento. Es un método que no se usa mucho pues "abc".concat("def") devuelve lo mismo que "abc" + "def", usando el operador de concatenación "+".
repeat(veces)
Devuelve un string conteniendo tantas veces la cadena como especifica su argumento, un número entero no negativo. Si es cero devuelve una cadena vacía. Por ejemplo, "abc".repeat(2) nos devolverá "abcabc". Antes de ES6 se conseguía repetir una cadena dos veces con Array(2+1).join("abc"), pues Array(n) nos construye un array de n posiciones con valores undefined (que se coercionarán a cadenas vacías) y luego usando su método join lo convertimos en string, concatenando los valores vacíos con la cadena que queremos repetir.
substr(inicio[, longitud])
Devuelve un string extrayendo una sección de una cadena indicada en sus argumentos, empezando en la posición inicio y con la longitud de caracteres indicada. Si el primer argumento es negativo se usa la longitud de la cadena menos ese valor. Si la longitud es cero o negativa se devuelve una cadena vacía. Si es omitida se extrae hasta el final de la cadena. Con "abcd".substr(1, 2) obtenemos la cadena "bc", pues se inicia en la posición 1 que ocupa la "b" y toma 2 caracteres.
substring(inicio[, fin])
Devuelve un string extrayendo una sección de una cadena indicada en sus argumentos, empezando en la posición inicio y terminando en el carácter anterior a la posición fin. Vea que no incluye la posición final. Los argumentos negativos o NaN se toman como cero. Si la longitud es cero se devuelve una cadena vacía. Si es omitida se extrae hasta el final de la cadena. Si inicio es mayor que fin entonces los argumentos se intercambian, es decir, substring(5, 2) se ejecutará como substring(2, 5). Con el ejemplo "abcd".substring(1, 3) obtenemos la cadena "bc", pues se inicia en la posición 1 que ocupa la "b" y llega hasta la posición anterior a la tercera, la "c".
slice(inicio[, fin])
Devuelve un string extrayendo una sección de una cadena indicada en sus argumentos, empezando en la posición inicio y terminando en el carácter anterior a la posición fin. Vea que no incluye la posición final. Si el segundo argumento es omitido se extrae hasta el final de la cadena. Con "abcd".slice(1, 3) obtenemos la cadena "bc", pues se inicia en la posición 1 que ocupa la "b" y finaliza en la posición anterior a la tercera, la "c".
Este método hace lo mismo que substring(), con la principal diferencia que ambos argumentos pueden ser negativos, en cuyo caso se usa la longitud de la cadena menos ese valor. Esto equivale a decir que se extrae partiendo del final. Por ejemplo, "abcd".slice(-3, -1) puede entenderse que se va a extraer la porción que empieza en el tercer carácter contando desde el final, la "b", hasta el anterior al primer carácter contando desde el final, la anterior a "d", con lo que pretendemos extraer "bc". Al final se ejecutará como "abcd".slice(4-3, 4-1), es decir, "abcd".slice(1, 3). Esto es útil cuando tenemos una cadena muy larga y queremos extraer algo muy corto al final de la misma, en cuyo caso es más fácil contar pocas posiciones hacia atrás que no hacia adelante.
A diferencia de substring(), si inicio es mayor que fin los argumentos no son intercambiados devolviendo una cadena vacía.
trim()
Devuelve un string eliminando los espacios blancos en ambos lados de la cadena. Son espacios blancos el espacio normal, tabulador, retornos de carro, etc.
Con " a b c\n\t".trim() obtenemos la cadena "a b c" sin espacios a ambos lados pero conservando los espacios intermedios.
Hasta ES5 veníamos simulando este método con cadena.replace(/^\s+|\s+$/, ""). El escape \s en una expresión regular debería incluir el espacio simple y todos los espacios blancos \t\n\v\r\f, como expongo en el tema sintaxis de expresiones regulares. Pero hay que tener en cuenta si queremos incluir en el patrón de expresión regular otros espacios Unicode como \uFEFF, que es un espacio de ancho cero no separable.
Chrome y Firefox soportan además trimLeft() y trimRight() para eliminar espacios sólo en uno de los lados. No es estándar y otros navegadores no lo soportan.