Algoritmos de transformación UTF-8
Buscando documentación acerca de UTF-8 en www.unicode.org
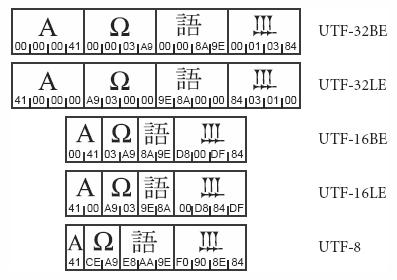
La imagen de la izquierda aparece en un documento al que puede accederse en versions/Unicode5.1.0, última versión de Unicode 5.1 con documentación de 5.0 Book Front Matter, donde se expone la documentación de Unicode desglosada en capítulos. Del Capítulo 2 General Structure, en su página 37, hemos extraído esta información que compara los distintos formatos UTF para codificar cuatro códigos Unicode: 65, 937, 35486 y 66436 en decimal (41, 3A9, 8A9E y 10384 en hexadecimal). En esta imagen los caracteres son a su vez imágenes, pues puede suceder que ciertos caracteres que aparecen más abajo no se presenten en el monitor, detalle que luego explicaremos.
El propósito es analizar como se realiza la codificación en UTF-8 y proponer algoritmos en VBScript para codificar y decodificar en UTF-8. Aunque ahora no trataremos los casos de UTF 16, 32, se observa que con UTF-32BE la disposición de los códigos es la misma que la del original en hexadecimal: 41, 3A9, 8A9E, 10384. En cuanto a BE, LE no nos adentraremos en este tema pues no afecta a UTF-8, bastando decir que se usan para serializar los bytes. Así con LE nos llegarían los bytes de forma invertida, con el de menor peso (Little Endian) primero, mientras que con BE nos llegan de forma normal, con el de mayor peso (Big Endian) primero. Como UTF-32 no necesita ninguna transformación, entonces con UTF-32BE sucede que la disposición de los bytes es la natural de lectura izquierda-derecha, coincidiendo visualmente con la disposición de los códigos Unicode.
La siguiente tabla contiene la información relacionada con cada caracter:
- Decimal Unicode: Unicode codifica unos 1.114.111 posiciones de caracteres, que en hexadecimal van de 0 a 10FFFF. Exceptuando un bloque de 2.048 posiciones (D800-DFFF) restringidas, quedan 1.112.064 posiciones para codificar caracteres. Una parte está ocupada por caracteres, otra parte están reservadas, pero de todas formas cada una de estas posiciones le corresponde un número de orden único.
- Hexadecimal Unicode: La posición decimal se expresa con más conveniencia en hexadecimal debido a que un btye (8 bits) se puede representar con 2 dígitos hexadecimales. Así por ejemplo, FF se corresponde con el decimal 255, es decir, 8 bits puestos a 1, el binario
11111111. - Carácter: En esta columna presentamos directamente el caracter usando la referencia a caracteres de HTML. Por ejemplo, la letra
Ala incluimos comoA, donde en este caso el código es el decimal Unicode. De igual forma hacemos paraΩ,語,𐎄. Los dos primeros caracteresAyΩpueden aparecer correctamente en el navegador sin más problemas. El tercero語es una caracter del grupo CJK (Chino, Japonés, Coreano). Para que se presente es necesario instalar los archivos de códigos en Windows, en el Panel de Control, Configuración regional y de idioma, Idiomas, Compatibilidad con idioma adicional, Instalar archivos para idiomas de Asia Oriental. En cuanto al último pertenece al Ugarítico que, la verdad, no nos importa nada saber lo que es y, aunque en Windows no aparece, tampoco es necesario instalarlo. Lo importante es que en esta columna se ubica el caracter tal cual, aunque no pueda ser visualizado. - Imagen: De todas formas en esta columna ponemos la imagen de cada caracter que hemos copiado del cuadro superior. Si pudo instalar los idiomas que faltan podrá observar que se corresponde la imagen con el caracter, aunque como hemos dicho, no será necesario como veremos más adelante.
- Definición: En la documentación de Unicode podemos obtener una lista completa de todos los códigos con la definición de cada caracter. Aquí la hemos trasladado.
- Hexadecimal UTF-8: Observando el cuadro anterior, anotamos aquí la codificación en la transformación a UTF-8 de cada caracter.
- Decimal UTF-8: Lo mismo pero en decimal.
| Decimal Unicode | Hexadecimal Unicode | Carácter | Imagen | Definición | Hexadecimal UTF-8 | Decimal UTF-8 |
|---|---|---|---|---|---|---|
| 65 | 41 | A | 0041;LATIN CAPITAL LETTER A | 41 | 65 | |
| 937 | 3A9 | Ω | 03A9;GREEK CAPITAL LETTER OMEGA | CE,A9 | 206,169 | |
| 35486 | 8A9E | 語 | 8A9E; kBigFive (CJK Unified Ideographs) | E8,AA,9E | 232,170,158 | |
| 66436 | 10384 | 𐎄 | 10384;UGARITIC LETTER DELTA | F0,90,8E,84 | 240,144,142,132 |
Ahora tenemos los siguientes objetivos:
- Por un lado comprobar si nuestro navegador tradujo correctamente la orden de inserción de caracteres realizada con la referencia a caracteres de HTML, hecha con
&#N;siendo N el decimal Unicode original sin transformar. - Aplicarlo en los casos en que leamos un fichero con el manejador de VBScript llamado FileSystemObject, con las siguientes acciones:
- Intentar crear un algoritmo para leer documentos en UTF-8. Es decir, dados lo códigos transformados de un documento en UTF-8, obtener los códigos Unicode originales. Con estos códigos originales podemos volcarlos en nuestro editor mediante la función de VBScript denominada
unescape("%uXXXX"). - Realizar la función inversa, transformar desde el código original de Unicode a UTF-8, con el objeto de poder guardar los cambios en el fichero.
- Intentar crear un algoritmo para leer documentos en UTF-8. Es decir, dados lo códigos transformados de un documento en UTF-8, obtener los códigos Unicode originales. Con estos códigos originales podemos volcarlos en nuestro editor mediante la función de VBScript denominada
Comprobación de la transformación de caracteres realizada por el navegador
Recordemos que este documento que está leyendo está codificado en UTF-8. Pues bien, cuando incluímos en la tercera columna de la tabla anterior la referencia Ω, el navegador tendría que sustituir dicho caracter por el correspondiente según Unicode. Sin embargo no podemos observar la codificación directamente en este documento, pues si lo abrimos como texto sólo aparece la referencia ellos. Pero si hay una forma de comprobarlo.
Copiamos los caracteres de la tercera columna, uno a uno, y los pegamos en un nuevo documento de texto que permita guardar en UTF-8, como el NotePad de Windows. Así lo hemos hecho y ese contenido está en el archivo de texto codigos-utf8.txt. Hemos dejado un espacio entre caracter y caracter al copiarlos en el NotePad. No importa que no se presenten algunos caracteres si no se han instalado las fuentes del idioma, pues a pesar de no verse, esos caracteres están ahí.
Luego usamos VBScript, que comentaremos más abajo, para extraer estos códigos: EF,BB,BF,41,20,CE,A9,20,E8,AA,9E,20,F0,90,8E,84
Esa cadena de bytes se corresponde con los 4 caracteres que hemos copiado desde la tercera columna en la tabla de esta página y hemos pegado en el NotePad, donde se observa que la transformación a UTF-8 realizada desde el navegador al NotePad fue correcta según la tabla expuesta más arriba:
EF,BB,BF: Esta es una marca llamada BOM que inserta NotePad al inicio del archivo para designar que se guardó como UTF-8. No nos adentraremos ahora en esto.41: Corresponde al caracter A. Los códigos Unicode menores o iguales que 127 (7F en hexadecimal), no sufren ninguna transformación UTF-8 y se quedan tal cual como ASCII, tal que cada caracter ocupa un byte.20: El código 20 corresponde al espacio que hemos insertado entre caracter y caracter al copiarlos en el NotePad.CE,A9: Corresponde al caracter Ω. Se observa que ocupa 2 bytes.20: Otro espacio.E8,AA,9E: Corresponde al caracter 語. Ocupa 3 bytes.20: Espacio.F0,90,8E,84: Corresponde al caracter 𐎄. Ocupa 4 bytes
Por lo tanto el primer objetivo está cumplido: el cuadro extraído de la documentación de Unicode con los ejemplos para esos cuatro caracteres coincide en la codificación UTF-8 con la que se ha guardado en el NotePad copiándolos directamente del navegador Explorer, como era de esperar por otro lado.
Seguridad sobre el uso de fileSystemObject
Antes de entrar en el objetivo de codificar y descodificar en UTF-8, conviene resaltar algunos detalles sobre el manejo de ficheros en VBScript.
VBScript es un lenguaje para uso de scripts con el navegador Internet Explorer. El que tenga capacidad para acceder al sistema de archivos supone un riesgo de seguridad. Por eso no ponemos ejemplos de ejecución de lo desarrollado aquí. Si lo desea puede descargar una carpeta comprimida con los archivos (ocupa unos 20 KB) y ejecutar en su ordenador, de forma local, la aplicación de ejemplo donde se observan estos algoritmos en ejecución. Y de paso también hay algunos usos relacionados con el manejo de ficheros mediante el fileSystemObject de VBScript. Después de descargar y descomprimir la carpeta, puede usar filesutf8.html con el navegador Explorer o bien usar filesutf8.hta directamente, pues es un ejecutable de VBScript.
Leer bytes desde un archivo de texto
Extraer cada byte es relativamente fácil usando FileSystemObject. A continuación reproducimos el código para extraer los bytes. Veáse que se abre el archivo en el modo 0, en ASCII, de tal forma que lee byte a byte. Con Hex(Asc(Mid(...))) extraemos un caracter, luego su código ASCII y por último lo convertimos en hexadecimal.
...
Set gfso = CreateObject("Scripting.FileSystemObject")
...
Set garchivoFile = gfso.GetFile(ruta)
...
Set archivoTexto = garchivoFile.OpenAsTextStream(1, 0)
If archivoTexto.AtEndOfStream Then Exit Sub
todo = archivoTexto.ReadAll
For i = 1 To Len(todo)
todoHex = todoHex & Hex(Asc(Mid(todo, i, 1))) & ","
Next
'Ya tenemos el resultado en todoHex
...
De UTF-8 a Unicode: Algoritmo para leer documentos UTF-8
En el mismo origen de la documentación de Unicode que mencionábamos más arriba versions/Unicode5.0.0, podemos encontrar el Capítulo 3 Conformance, donde en la página 78 encontramos el siguiente cuadro:
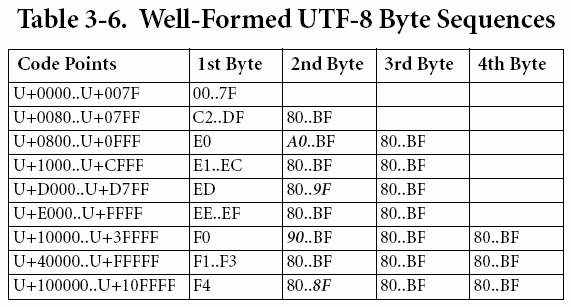
Este cuadro contiene la clave para extraer el código original desde un código transformado en UTF-8. Observamos que se clasifican las posibles posiciones de Unicode de 0 a 10FFFF, es decir, todas las posiciones posibles en el universo de códigos Unicode. Pero dependiendo de unos rangos se aplican de uno a cuatro bytes. Los primeros 128 bytes (0 a 127, 0 a 7F en hexadecimal) se corresponden con el ASCII no extendido. A partir de ahí se necesita más de un byte para expresar un caracter.
Hemos tomado los datos de esta tabla para crear la siguiente:
| byte 1 | byte 2 | byte 3 | byte 4 | rango 1 | rango 2 | rango 3 | rango 4 | Rango total | Salto | De Dec. | A Dec. | De Hex. | A Hex. | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| de | a | de | a | de | a | de | a | ||||||||||
| 0 | 127 | 128 | 1 | 1 | 1 | 128 | 0 | 127 | 0 | 7F | |||||||
| 194 | 223 | 128 | 191 | 30 | 64 | 1 | 1 | 1920 | 128 | 2047 | 80 | 7FF | |||||
| 224 | 224 | 160 | 191 | 128 | 191 | 1 | 32 | 64 | 64 | 2048 | 2048 | 4095 | 800 | FFF | |||
| 225 | 236 | 128 | 191 | 128 | 191 | 12 | 64 | 64 | 1 | 49152 | 4096 | 53247 | 1000 | CFFF | |||
| 237 | 237 | 128 | 159 | 128 | 191 | 1 | 32 | 64 | 1 | 2048 | 53248 | 55295 | D000 | D7FF | |||
| 238 | 239 | 128 | 191 | 128 | 191 | 2 | 64 | 64 | 1 | 8192 | 2048 | 57344 | 65535 | E000 | FFFF | ||
| 240 | 240 | 144 | 191 | 128 | 191 | 128 | 191 | 1 | 48 | 64 | 64 | 196608 | 65536 | 262143 | 10000 | 3FFFF | |
| 241 | 243 | 128 | 191 | 128 | 191 | 128 | 191 | 3 | 64 | 64 | 64 | 786432 | 262144 | 1048575 | 40000 | FFFFF | |
| 244 | 244 | 128 | 143 | 128 | 191 | 128 | 191 | 1 | 16 | 64 | 64 | 65536 | 1048576 | 1114111 | 100000 | 10FFFF | |
| Total posiciones | 1112064 | ||||||||||||||||
Hemos convertidos los valores hexadecimales de la tabla anterior en decimales para efectuar los cálculos que se explican a continuación, por lo que todas las columnas están en decimales a excepción de las dos últimas columnas que están en hexadecimal y son la conversión de las dos columnas anteriores.
Se observan 9 filas correspondientes a la división en sectores de todo el universo Unicode. En total 1.112.064 posiciones de código. En las columnas De Dec., A Dec. se exponen los códigos primero y último de cada rango. Se observan que son correlativos, 0-127, 128-2047, 2048-4095, etc. Sin embargo se produce un salto entre la posiciones 55296 y 57343 (D800 a DFFF en hexadecimal). Son exactamente 2048 posiciones de código que no son extraíbles. Se usan para transformaciones en UTF-16 que no vamos a explicar ahora, pero que para nuestros efectos es como si no existieran. Por eso hay un total de 1.112.064 posiciones, pero van desde la 0 a la 1.114.111 debido a ese salto.
Las columnas rango n son el resultado de calcular cuantas posiciones haya en cada byte. Por ejemplo, el primer byte de la primera fila va desde 0 a 127, por tanto hay 127-0+1 = 128 posiciones. El rango total es el producto de rango 1 x rango 2 x rango3 x rango 4, lo que nos da el total de posiciones que pueden expresarse en cada fila.
Veámos ahora con nuestros caracteres de ejemplo 65, 937, 35486 y 66436 en decimal (41, 3A9, 8A9E y 10384 en hexadecimal) que usamos más arriba. Su transformación en UTF-8 daba los códigos 41 para el original 41, CEA9 para el original 3A9, E8AA9E para el original 8A9E y F0908E84 para el 10384. Como vemos se trata de 4 ejemplos con 1 a 4 bytes. Partiendo de la transformación y, mediante la tabla anterior, queremos obtener los códigos originales. La cadena que leeríamos desde un archivo de texto sería en hexadecimal:
41,CE,A9,E8,AA,9E,F0,90,8E,84
y en decimal
65,206,169,232,170,158,240,144,142,132
- Leemos un byte, el
65. Se comprueba en la tabla anterior, a que fila pertenece, viendo que el 65 está en el primer byte en 0-127, entonces le corresponde la fila primera y no hay que leer más bytes. Restamos el código del inicial de la fila: 65-0 = 65. Como no hay más bytes aquí acaba el cálculo. El código original es el mismo que el UTF, el 65. - Leemos el siguiente byte, el
206. El primer byte 206 está en la 2ª fila según vemos, entre 194 y 223. Por lo tanto este caracter tiene un segundo byte que habrá que leer, el169. El primer byte ocupa la posición 206-194 = 12. Como por cada posición del primer byte hay 64 bytes en el segundo, entonces la posición relativa será 12 x 64 = 768. Además hay que sumar la posición inicial donde empieza la fila (128) más la posición relativa que ocupa el segundo byte 169-128 = 41. En total 128 + 768 + 41 = 937. Este 937 es el código original Unicode para este caracter. - Leemos el siguiente byte, el
232. Se sitúa en la fila 4ª, en las posiciones 225-236 de byte 1, exactamente en la posición 232-225 = 7. Vemos que hemos de leer 2 bytes más. El segundo será el170y el tercero el158. Por cada posición del byte 1º existen 64 posiciones en el byte 2º y 64 en el 3º. Por lo tanto el byte 1º está en la posición relativa 7 x 64 x 64 = 28672. El byte 2º se sitúa en la posición 170-128 = 42. Por cada posición del byte 2º existen 64 posiciones en el byte 3º. Por lo tanto el byte 2º se sitúa en la posición relativa 42 x 64 = 2688. El byte 3º está en la posición 158-128 = 30 y es el último pues no hay byte 4º. Por lo tanto la posición final será, sumando la inicial de la fila 4096 (en la columna De Dec.), 4096 + 28672 + 2688 + 30 = 35486. Este 35486 es el código original para el tercer caracter. - Leemos el siguiente byte, el
240. Se sitúa en la fila en la 7ª fila, entre 240-240. Hay que leer tres bytes más,144,142y132. El byte 1º está en la posición 240-240 = 0 y la relativa 0 x 48 x 64 x 64 = 0. El byte 2º está en la posición 144-144 = 0 y la relativa 0 x 64 x 64 = 0. El byte 3º está en la posición 142 - 128 = 14 y la relativa 14 x 64 = 896. El byte 4º está en la posición 132 - 128 = 4 y no hay más bytes. Siendo la posición inicial de la fila la 65536 entonces sumamos 65536 + 0 + 0 + 896 + 4 = 66436. Este 66436 es el código original Unicode del cuarto caracter.
Se observa que podemos extraer el código original partiendo de la tabla. Entonces para la implementación en VBScript almacenamos la tabla en arrays. Sólo necesitamos 9 columnas de datos para los rangos de cada byte y el inicio del código de cada fila. Para cargar los datos sólo una vez hemos dispuesto el procedimiento cargaArrysUtf8. Así por ejemplo gini(n, m) es el array que contiene el valor de inicio del byte m en la fila n, mientras que gfin(n, m) contiene el valor final del byte m en la fila n. Por último el array ginicio(n) contiene el valor del inicio de la fila n.
'CODIFICAR Y DESCODIFICAR CARACTERES UTF8
'byte1 byte2 byte3 byte4 De Dec.
' 0-127 0
'194-223 128-191 128
'224-224 160-191 128-191 2048
'225-236 128-191 128-191 4096
'237-237 128-159 128-191 53248
'238-239 128-191 128-191 57344 (salta D800-DFFF)
'240-240 144-191 128-191 128-191 65536
'241-243 128-191 128-191 128-191 262144
'244-244 128-143 128-191 128-191 1048576
Sub cargaArraysUtf8()
Dim arr, i
arr = Array(194,224,225,237,238,240,241,244)
For i = 0 To 7
gini(0, i) = arr(i)
Next
arr = Array(223,224,236,237,239,240,243,244)
For i = 0 To 7
gfin(0, i) = arr(i)
Next
arr = Array(128,160,128,128,128,144,128,128)
For i = 0 To 7
gini(1, i) = arr(i)
Next
arr = Array(191,191,191,159,191,191,191,143)
For i = 0 To 7
gfin(1, i) = arr(i)
Next
arr = Array(0,128,128,128,128,128,128,128)
For i = 0 To 7
gini(2, i) = arr(i)
Next
arr = Array(0,191,191,191,191,191,191,191)
For i = 0 To 7
gfin(2, i) = arr(i)
Next
arr = Array(0,0,0,0,0,128,128,128)
For i = 0 To 7
gini(3, i) = arr(i)
Next
arr = Array(0,0,0,0,0,191,191,191)
For i = 0 To 7
gfin(3, i) = arr(i)
Next
ginicio = Array(128,2048,4096,53248,57344,65536,262144,1048576)
gcargadoArrayUtf8 = True
End Sub
El código del descodificador de UTF-8 a Unicode se expone a continuación. Como argumentos se pasa la cadena en UTF-8 desde donde queremos extraer sus códigos Unicode originales.
El argumento mostrarUnicode puede tomar valores 0, 1 o 2. Aparte de descodificar una cadena en UTF-8 (con el valor 0), esta función también sirver para extraer una muestra de los códigos UNICODE de cada caracter en decimal o hexadecimal con los valores 1 o 2 para ese argumento. En este caso se pone un límite al número de códigos extraídos, lo cual se especifica en la variable hasta.
El proceso es el mismo que el expuesto en el ejemplo. Si el caracter sólo tiene un byte se muestra tal cual. En otro caso se toma un byte y se busca la fila para saber cuantos bytes más hay que leer. Luego se hace el proceso de cálculo igual a como hicimos en el ejemplo anterior. El resultado se extrae cuando ya no hay más bytes que leer.
Function descodificaUtf8(cadenaUtf8, mostrarUnicode)
Dim cod(4), i, j, k, todo, lonCadena, unicod, prod, hunicod, fila
Dim hayError, preguntar, preguntarOtraVez, nodoCar, codMas, hasta
If Not gcargadoArrayUtf8 Then cargaArraysUtf8
'Este valor límita el número de muestras de códigos extraídos cuando mostrarUnicode vale 2 o 3
hasta = 50
lonCadena = Len(cadenaUtf8)
hayError = False
preguntar = True
preguntarOtraVez = False
i = 1
'comprueba BOM para UTF8 si lo tiene puesto, en cuyo caso lo ignora y comienza a partir del
'siguiente caracter. El BOM es EF BB BF que se corresponde con los códigos 239,187,191
gbom = ""
If lonCadena>=3 Then
If Asc(Mid(cadenaUtf8, 1, 1)) = 239 And Asc(Mid(cadenaUtf8, 2, 1)) = 187 And _
Asc(Mid(cadenaUtf8, 3, 1)) = 191 Then
gbom = Chr(239) & Chr(187) & Chr(191)
i = 4
End If
End If
Do While i <= lonCadena
If mostrarUnicode > 0 And i > hasta Then Exit Do
cod(0) = Asc(Mid(cadenaUtf8, i, 1))
If cod(0) < 128 Then
If mostrarUnicode = 0 Then
todo = todo & Chr(cod(0))
ElseIf mostrarUnicode = 1 Then 'código Unicode en decimal
todo = todo & cod(0) & ", "
Else '2, código Unicode en hexadecimal
todo = todo & Hex(cod(0)) & ", "
End If
ElseIf cod(0) < 194 Or cod(0) > 244 Then
todo = todo & Chr(cod(0))
hayError = True
Else 'estará en la tabla 194 a 244
'busca en el primer byte la fila a la que pertenece
fila = -1
For j = 0 To 7
If cod(0) >= gini(0, j) And cod(0) <= gfin(0, j) Then
fila = j
Exit For
End If
Next
If fila = -1 Then
todo = todo & Chr(cod(0))
hayError = True
Else
'extrae y comprueba los siguientes bytes
unicod = ginicio(fila)
For j = 1 To 4
If j=4 Or gini(j, fila) = 0 then 'ya no hay más bytes
unicod = unicod + cod(j-1) - gini(j-1, fila)
hunicod = "" & Hex(unicod)
If mostrarUnicode = 0 Then
If len(hunicod)>4 Then 'es unicode con más de 2 bytes
'ponemos la referencia HTML al caracter porque la función unescape() no
'permite más de 2 bytes
Set nodoCar = Document.GetElementById("car")
nodoCar.innerHtml = "&#" & unicod & ";"
codMas = nodoCar.innerHtml
ElseIf len(hunicod)<4 Then 'menos de 2 bytes usamos unescape("%uXXXX")
codMas = unescape("%u" & String(4-Len(hunicod), "0") & hunicod)
Else 'exactamente 2 bytes, usamos unescape("%uXXXX")
codMas = unescape("%u" & hunicod)
End If
todo = todo & codMas
ElseIf mostrarUnicode = 1 Then 'unicode en decimal
todo = todo & unicod & ", "
Else '2, unicode en hexadecimal
todo = todo & hunicod & ", "
End If
Exit For
Else
i = i + 1
If i>LonCadena Then
todo = todo & Chr(cod(0))
hayError = True
Exit For
End If
cod(j) = Asc(Mid(cadenaUtf8, i, 1))
If cod(j) >= gini(j, fila) And cod(j) <= gfin(j, fila) Then
prod = 1
For k = j To 3
prod = prod * (gfin(k,fila)-gini(k,fila)+1)
Next
unicod = unicod + (cod(j-1)-gini(j-1, fila))*prod
Else
todo = todo & Chr(cod(0))
hayError = True
Exit For
End If
End If
Next
End If
end if
If hayError And preguntar Then
If MsgBox("Se ha encontrado un error: Puede que el texto no esté en UTF-8, " & _
"¿Seguir descodificando?",4) = 7 Then
hayError = False
Exit Do
Else
preguntarOtraVez = True
preguntar = False
End If
End If
i = i + 1
Loop
descodificaUtf8 = todo
If hayError Then
Alert("No se efectuó correctamente la descodificación del texto desde UTF-8. " & _
"Puede que el texto tuviera otra codificación, inténtelo con UTF-16, ASCII o Sistema.")
End If
End FunctionSe controlan los errores pues si algún byte no está en los rangos de la primera columna da un error con la posibilidad de no seguir descodificando. Aunque lee la marca BOM de entrada que nos permite detectar si un archivo está codificado en UTF-8 (EF BB BF), hay que tener en cuenta que no siempre estará presente esta marca. De hecho se recomienda no incluir esta marca en los documentos, pues supone un estorbo para ciertas aplicaciones. Por ejemplo, si creamos un XHTML en un NotePad en UTF-8, el NotePad agrega esta marca al inicio. Luego no podremos validar el DTD del documento pues un XML debe tener al inicio, antes que nada, algo como <?xml version="1.0" encoding="UTF-8"?>. Por lo tanto no pondremos como condición necesaria que un documento en UTF-8 tenga la marca, aunque si la tiene hemos de detectarla para no manejarla como un caracter.
Una vez conocido el código original Unicode hemos de trasladarlo al texto, agregando ese caracter a la variable todo que va almacenando los caracteres convertidos, variable que luego devolveremos al final de la función. El código Unicode, variable unicod lo convertimos a hexadecimal, variable hunicod, en forma de un String "XXXX". Se dan los casos:
- Si el código hexadecimal tiene 4 dígitos, lo convertimos a un caracter con la función de VBScript
unescape("%u" & hunicod). - Si el código tiene menos de 4 dígitos, formateamos con cero hasta completar los cuatro dígitos, por ejemplo, "00XX" y aplicamos
unescape("%u" & "00XX"). - Si tiene más de 4 dígitos (puede tener hasta 6), no podemos aplicar
unescape. Entonces usamos una vía indirecta. Obligamos a que sea el propio navegador quién incruste el caracter en una parte del documento. Para ello disponemos de un elemento<div id="car" style="display:none"></div>en el cuerpo del documento HTML. Este elemento queda oculto y medianteinnerHtmlrecibe el caracter que luego recogemos para añadir a nuestra variabletodo.
El algoritmo expuesto antes es, por supuesto, mejorable. Especialmente en lo referente a los cálculos de multiplicaciones con el objeto de conseguir una mejora en el coste de las mismas, pues se podrían almacenar en una tabla para no tener que efectuarlas. Por ejemplo, cuando la posición relativa del primer byte es 0 no sería necesario que realice las multiplicaciones. Además habría que controlar las posiciones no accesibles D800-DFFF e ignorarlas, aunque en un UTF-8 bien formado no deberían encontrarse estas posiciones de código.
Hemos realizado una prueba en VBScript usando el archivo de muestra codigos-utf8.txt, abriéndolo con las tres opciones posibles que nos permite el objeto de VBScript FileSystemObject así como abierto con el algoritmo descodificador utf8 expuesto antes:
| Modo de abrir | Imagen obtenida en pantalla |
|---|---|
| ASCII con FileSystemObject | |
| Sistema con FileSystemObject | |
| Unicode UTF-16 con FileSystemObject | |
| UTF-8 con nuestro algoritmo |
El modo Sistema del FileSystemObject no es capaz de detectar la marca BOM del UTF-8 ( correspondientes a EF,BB,BF), por lo que el resultado es que abre el archivo como el modo ASCII, aplicando un caracter por byte leído. El modo UTF-16, también del FileSystemObject, no reconoce la marca BOM de UTF-8, por lo que intenta aplicar UTF-16 de tal forma que el texto no es reconocible. Sólo con el algoritmo anterior se consigue convertir adecuadamente los 4 caracteres. Si se han instalado las fuentes para idiomas de Asia Oriental (chino, japonés, coreano,...), se podrá ver el tercer caracter de los cuatro que contiene el archivo, pues los dos primeros se verán sin necesidad de instalar otras fuentes. Recordemos que el cuarto caracter es del grupo Ugaritic en Unicode y que aquí no pudimos instalar su fuente.
De Unicode a UTF-8: Algoritmo para escribir documentos UTF-8
Se trata de tomar los caracteres que hemos escrito en el área de texto y convertirlos a UTF-8. Primero tenemos que saber cuál es el código Unicode de cada caracter. Usando la función escape nos dará el código en UTF-16. Sólo tenemos que saber leer UTF-16 y convertirlo en UTF-8.
Nuestra cadena de ejemplo A, Ω, 語, 𐎄 se correspondía con los códigos Unicode A, Ω, 語, 𐎄. Entonces aplicando unescape a cada uno de estos caracteres nos daría:
escape(A) = "A"escape(Ω) = "%u03A9"escape(語) = "%u8A9E"escape(𐎄) = "%uD800%uDF84"
Las funciones escape/unescape se confirieron para escapar caracteres Unicode en las dirección URI. Por eso los caracteres ASCII hasta 127 que no sean signos de puntuación se pasan tal cual, como en este ejemplo la "A". Su código Unicode es el Asc("A") = 65, es decir, el código ASCII. El resto se codifica con "%uXXXX", donde XXXX es el código Unicode pero en UTF-16. Nosotros detectaremos cuando una conversión comienza con "%" teniendo en cuenta que hasta el código Unicode FFFF (65535 en decimal), en UTF-16 se representa tal cual, sin ninguna tranformación. Asi la cadena "%u03A9" tiene el Unicode hexadecimal 3A9 que es el 937 en decimal. El siguiente "%u8A9E" será el Unicode hexadecimal 8A9E, 35486 en decimal. Los Unicode a partir de FFFF, es decir de 10000 hasta 10FFF se transforman en dos grupos o sustitutos, como en este ejemplo "D800 DF84". El primer sustituto estará en el rango D800-DBFF y el segundo en el rango DC00-DFFF (en decimal 55296-56319 y 56320-57343).
Si num1, num2 son los valores decimales del primero y segundo sustituto respectivamente, entonces hallamos la diferencia que hay con la base de cada rango, es decir, restaSup = num1 - 55296 y restaInf = num2 - 56320. Así el número Unicode final se calcula con num = 65536 + restaSup * 1024 + restaInf. Veámos esto para el ejemplo:
El D800 en hexadecimal es el num1 = 55296
El DF84 en hexadecimal es el num2 = 57220
Por lo tanto restaSup = num1 - 55296 = 55296 - 55296 = 0
Y restaInf = num2 - 56320 = 57220 - 56320 = 900
Finalmente num = 65536 + restaSup * 1024 + restaInf = 66436.
En resumen, ya tenemos los códigos Unicode 65, 937, 35486, 66436 de cada caracter leídos directamente desde, por ejemplo, un elemento HTML como <textarea>. La segunda parte es convertirlos en UTF-8. Para ello hacemos la operación inversa de la señalada antes:
65. Buscamos en la tabla la fila a la que pertenece observando por las columnas De Dec. a Dec., por el inicio del rango. En este caso está en la primera fila y devolvemos el código tal cual65.937. Le corresponde la segunda fila (De 128 a 2047). Primero buscamos la posición relativa en esa fila937-128 = 809. Luego Multiplicamos los valores derango2 x rango3 x rango4 = 64 x 1 x 4 = 64. Realizamos la división entera809 \ 64 = 12. Este valor más el inicial del primer byte en esa fila, es decir12 + 194 = 206será el primer byte UTF-8. Vemos el resto de la división809 Mod 64 = 41y lo aplicamos al segundo byte41 + 128 = 169, siendo este el segundo btye UTF-8. Así el Unicode937se convierte en el UTF-8206, 169en decimal o elCE, A9en hexadecimal.35486. Le corresponde la fila4096 a 53247. La posición relativa será35486 - 4096 = 31390. El producto de rangos es64 x 64 x 1 = 4096. La división entera31390 \ 4096 = 7, entonces el primer byte será225 + 7 = 232. El resto31390 Mod 4096 = 2718. Como este valor supera el margen del segundo byte, volvemos a aplicar el procedimiento, pero ahora reduciendo los rangos de los productos, es decirrango3 x rango 4 = 64 x 1 = 64. La división entera2718 \ 64 = 42. Segundo byte42 + 128 = 170. El resto es2718 Mod 64 = 30, por lo que el tercer byte será30 + 128 = 158. Entonces el Unicode35486se transforma en el UTF-8232, 170, 158en decimal, elE8,AA,9Een hexadecimal.66436. Fila65536 - 262143. Resta66436-65536=900. Producto rangos48x64x64=196608. División900 \ 196608 = 0. Primer byte0 + 240 = 240. Resto900 Mod 196608 = 900. Producto rangos64x64=4096. División900 \ 4096 = 0Segundo byte0 + 144 = 144. Resto900 Mod 4096 = 900. Producto rangos64. División900 \ 64 = 14. Tercer byte14 + 128 = 142. Resto900 Mod 64 = 4. Cuarto byte4 + 128 = 132. Por tanto el Unicode66436se compone en UTF-8 de 4 bytes240, 144, 142, 132, es decirF0, 90, 8E, 84en hexadecimal.
Por lo tanto la cadena Unicode 65, 937, 35486, 66436 en decimal o bien 41, 3A9, 8A9E, 10384 en hexadecimal, que hemos extraído del elemento <textarea> y la hemos convertido a UTF-8 en 41, CE, A9, E8, AA, 9E, F0, 90, 8E, 84. Usamos la función siguiente para convertir un caracter Unicode a UTF-8. Pero hay que leer caracter a caracter en el <textarea>, extraer el código Unicode tal como hicimos arriba y luego aplicar esta función para transformar ese código Unicode en 1 a 4 bytes UTF-8. Esta función devuelve un String con los códigos decimales de 1 a 4 bytes separados por comas. En el procedimiento de vuelta reemplaza esos valores decimales con Chr() para insertar un byte ASCII en el archivo final ya en UTF-8.
Function codificaByteUtf8(cod)
Dim devuelve, fila, codRango, i, j, prod, numero, num, conError, ok
If Not gcargadoArrayUtf8 Then cargaArraysUtf8
If Not(IsNumeric(cod)) Then 'Error, no es un número
codificaBytesUtf8 = ""
Exit Function
ElseIf cod<0 Then 'Error, no puede ser negativo
codificaBytesUtf8 = ""
Exit Function
ElseIf cod < 128 Then 'lo devuelve tal cual
codificaBytesUtf8 = cod
Exit Function
ElseIf cod > 1114111 Then 'Error, supera máximo código de Unicode
codificaBytesUtf8 = ""
Exit Function
Else 'busca la fila
ok = False
For fila = 1 To 7
If ginicio(fila) > cod Then
fila = fila -1
ok = True
Exit For
End If
Next
If Not ok Then fila = 7
End If
codRango = cod - ginicio(fila)
devuelve = ""
conError = False
For i = 1 To 4
If i=4 Or gini(i,fila) = 0 Then 'no hay más bytes o estamos en el cuarto byte y no nay más
devuelve = devuelve & "," & (gini(i-1,fila)+codRango)
Exit For
Else
prod = 1
For j = i To 3
prod = prod * (gfin(j, fila)-gini(j,fila)+1)
Next
numero = codRango \ prod
num = gini(i-1,fila) + numero
If gini(i-1,fila) <= num <= gfin(i-1,fila) Then
If devuelve = "" Then
devuelve = num
Else
devuelve = devuelve & "," & num
End If
codRango = codRango Mod prod
Else 'supone error
conError = True
Exit For
End If
End If
Next
If conError Then
codificaByteUtf8 = ""
Else
codificaByteUtf8 = devuelve
End If
End Function
La función que usa la anterior y que convierte un texto en UTF-8 es la siguiente, donde el argumento "cadena" es el texto extraído del <textarea> y que será devuelto transformado en UTF-8. Primero busca el código Unicode que le corresponde a cada caracter y luego llama a la función anterior (señalado en azul) para transformar a UTF-8 ese caracter. Luego va agregando bytes a la salida que se devolverá.
Function codificaUtf8(cadena)
Dim i, lonCadena, todo, car, car0, car1, car2, numHex, num, strCod, arrayCod, j
Dim restaSup, restaInf, hayError
cadena = escape(cadena)
lonCadena = Len(cadena)
i = 1
hayError = 0
Do While i<=lonCadena
car0 = Mid(cadena, i , 1)
If car0 = "%" Then
i = i + 1
If i>lonCadena Then
hayError = 1
Exit Do
End If
car1 = Mid(cadena, i, 1)
If car1 = "u" Then 'otros caracteres con ASCII > 255 se ponen como %uXXXX
i = i + 4
If i>lonCadena Then
hayError = 2
Exit Do
End If
car2 = Mid(cadena, i-3, 4)
Execute "numHex = &H" & car2
num = CLng(numHex)
If num<0 Then
num = 65536+num
End If
If num>55295 And num<57344 Then
'Será un Unicode en UTF16 para Unicodes >= &H10000; (65536 en decimal) de tal forma
'que se codifica con los dos sustitutos D800-DBFF y DC00-DFFF, en total 4 bytes
If num>55295 And num<56320 Then 'El primer byte sustituto estará en D800-DBFF
restaSup = num - 55296 'Restamos de D800 = 55296
i = i + 6 'extraemos el segundo sustituto como "%uXXXX"
If i>lonCadena Then
hayError = 3
Exit Do
End If
car2 = Mid(cadena, i-5, 6)
If Left(car2, 2) = "%u" Then
car2 = Right(car2, 4)
Execute "numHex = &H" & car2
num = CLng(numHex)
If num<0 Then
num = 65536+num
End If
If num>56319 And num<57344 Then 'El 2º byte sustituto estará en DC00-DFFF
restaInf = num - 56320 'Restamos de DC00 = 56320
'Extraemos el número Unicode con esta fórmula
num = 65536 + restaSup * 1024 + restaInf
Else 'En otro caso será un error de codificación
hayError = 4
Exit Do
End If
Else 'será error
hayError = 5
Exit Do
End If
Else 'En otro caso será un error de codificación
hayError = 6
Exit Do
End If
End If
strCod = codificaByteUtf8(num)
If strCod="" Then
hayError = 7
Exit Do
Else
arrayCod = Split(strCod, ",", -1, 1)
If IsEmpty(arrayCod) Or UBound(ArrayCod)=-1 Then
hayError = 8
Exit Do
Else
For Each j In arrayCod
todo = todo & Chr(j)
Next
End If
End If
Else 'Son ASCII <= 255, espacios, puntuaciones y otros ASCII extendidos se ponen como %XX
i = i + 1
If i>lonCadena Then
hayError = 9
Exit Do
End If
car2 = Mid(cadena, i, 1)
Execute "numHex = &H" & car1 & car2
num = CLng(numHex)
If num>=0 And num<=127 Then 'los ASCII<=127 se pasan tal cual
todo = todo & Chr(num)
Else 'Para códigos en 128 - 255 los convierte a UTF-8 también
strCod = codificaByteUtf8(num)
If strCod="" Then
hayError = 10
Exit Do
Else
arrayCod = Split(strCod, ",", -1, 1)
If IsEmpty(arrayCod) Or UBound(ArrayCod)=-1 Then
hayError = 11
Exit Do
Else
For Each j In arrayCod
todo = todo & Chr(j)
Next
End If
End If
End If
End If
Else 'Los ASCII sin incluir espacios, puntuaciones y otros se pasan tal cual (letras, dígitos)
todo = todo & car0
End If
i = i + 1
Loop
If hayError>0 Then
Alert("Error al codificar en UTF-8 (Error " & hayError & "). No se codificó a UTF-8.")
codificaUtf8 = cadena
gError = True
Else
codificaUtf8 = todo
gError = False
End If
End Function