Isomorfismos: poda con automorfismos
Obtener automorfismos con árbol de particiones con sólo refinamiento

En la Figura vemos un grafo que nos servirá para explicar la poda con automorfismos, el mismo grafo que usamos para explicar el refinamiento en el tema anterior, al que agregamos su árbol de particiones resaltando en color las ramas que se podan con automorfismos. Puede ver el JSON de ambos en graph-sample-2.txt para importar en la aplicación. Lo he tomado del documento [D2]. En una tema anterior ya explicamos que eran los automorfismos de un grafo. En este tema vamos a ver como podamos con automorfismos el árbol de particiones.
Ejecutando el algoritmo getPartitionTree() obtenemos el árbol de particiones con refinamiento y sin más podas, activando el trazado que nos devuelve el siguiente resultado:
Time: 4 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc",
"targetCell":"max-length-first","typeCanon":"edges",
"useMcr":false,"useMcrPlus":false,"useMcrBreak":false,
"typeIndicator":"none",
"timeTotal":4,"timeIni":1,"timeRef":0,
"iter":17,"refine":13,"indexTree":12,
"leaves":8,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanon":true,
"canonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[],[]],[0,[],[]],[0,[],[]],[0,[],[]]],
[[0,[],[],"f*"],[0,[],[],"=(0 2)(3 5)(6 8)"],[1,[],[],"=(1 3)(2 6)(5 7)"],[1,[],[],"=(0 6 8 2)(1 3 7 5)"],[2,[],[],"=(0 2 8 6)(1 5 7 3)"],[2,[],[],"=(0 8)(1 5)(3 7)"],[3,[],[],"=(0 6)(1 7)(2 8)"],[3,[],[],"=(0 8)(1 7)(2 6)(3 5)"]]],
"nodeBest":[2,0],
"mcr":null,
"fixMcr":null,
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":0,
"tree":[{"index":0,"value":"(1 3 5 7)(0 2 6 8)(4)","parent":-1},
{"index":1,"value":"(1)(3 5)(7)(0 2)(6 8)(4)","parent":[{"index":0,"value":"1"}]},
{"index":2,"value":"(1)(3)(5)(7)(0)(2)(6)(8)(4)","parent":[{"index":1,"value":"3"}]},
{"index":3,"value":"(1)(5)(3)(7)(2)(0)(8)(6)(4)","parent":[{"index":1,"value":"5"}]},
{"index":4,"value":"(3)(1 7)(5)(0 6)(2 8)(4)","parent":[{"index":0,"value":"3"}]},
{"index":5,"value":"(3)(1)(7)(5)(0)(6)(2)(8)(4)","parent":[{"index":4,"value":"1"}]},
{"index":6,"value":"(3)(7)(1)(5)(6)(0)(8)(2)(4)","parent":[{"index":4,"value":"7"}]},
{"index":7,"value":"(5)(1 7)(3)(2 8)(0 6)(4)","parent":[{"index":0,"value":"5"}]},
{"index":8,"value":"(5)(1)(7)(3)(2)(8)(0)(6)(4)","parent":[{"index":7,"value":"1"}]},
{"index":9,"value":"(5)(7)(1)(3)(8)(2)(6)(0)(4)","parent":[{"index":7,"value":"7"}]},
{"index":10,"value":"(7)(3 5)(1)(6 8)(0 2)(4)","parent":[{"index":0,"value":"7"}]},
{"index":11,"value":"(7)(3)(5)(1)(6)(8)(0)(2)(4)","parent":[{"index":10,"value":"3"}]},
{"index":12,"value":"(7)(5)(3)(1)(8)(6)(2)(0)(4)","parent":[{"index":10,"value":"5"}]}],
"automorphisms":
[[[0,2],[1],[3,5],[4],[6,8],[7]],
[[0],[1,3],[2,6],[4],[5,7],[8]],
[[0,6,8,2],[1,3,7,5],[4]],
[[0,2,8,6],[1,5,7,3],[4]],
[[0,8],[1,5],[2],[3,7],[4],[6]],
[[0,6],[1,7],[2,8],[3],[4],[5]],
[[0,8],[1,7],[2,6],[3,5],[4]]],
"automorphismsPlus":0}En primer lugar observamos las opciones del algoritmo useMcr": false, "useMcrPlus": false, "useMcrBreak": false para podar con automorfismos, ahora todas desactivadas, donde usamos las siglas MCR que provienen de los documentos de referencia a partir de Minimum Cell Representative y que entenderemos después.
() (0 2)(3 5)(6 8) (1 3)(2 6)(5 7) (0 6 8 2)(1 3 7 5) (0 2 8 6)(1 5 7 3) (0 8)(1 5)(3 7) (0 6)(1 7)(2 8) (0 8)(1 7)(2 6)(3 5)
Activando la traza obtenemos en azul todos los automorfismos del grafo, al que hay que añadir el de la permutación identidad que es trivial. Muchas veces se presentan en los documentos en forma normalizada tal como explicamos en el tema de automorfismos, al que agregamos la permutación identidad ().
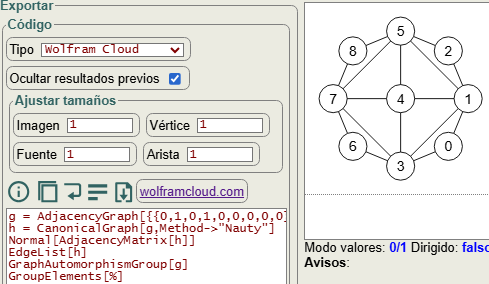
La aplicación permite obtener el grafo canónico y los automorfismos en Wolfram Cloud usando la función CanonicalGraph con los métodos "Nauty" o "Bliss" con el código siguiente, donde se obtienen los automorfismos con GraphAutomorphismGroup y con GroupElements:
g = AdjacencyGraph[{{0,1,0,1,0,0,0,0,0},{1,0,1,1,1,1,0,0,0},{0,1,0,0,0,1,0,0,0},{1,1,0,0,1,0,1,1,0},{0,1,0,1,0,1,0,1,0},{0,1,1,0,1,0,0,1,1},
{0,0,0,1,0,0,0,1,0},{0,0,0,1,1,1,1,0,1},{0,0,0,0,0,1,0,1,0}}, ImageSize -> 213, VertexSize -> {"Scaled", 0.15}, VertexLabels -> {1 -> Placed[0,Center],
2 -> Placed[1,Center], 3 -> Placed[2,Center], 4 -> Placed[3,Center], 5 -> Placed[4,Center], 6 -> Placed[5,Center], 7 -> Placed[6,Center], 8 -> Placed[7,Center],
9 -> Placed[8,Center]}, VertexLabelStyle -> Directive[Black,17.5], EdgeLabelStyle -> Directive[Black,17.5,Bold],
VertexStyle -> White, EdgeStyle -> {{Black,Thickness[0.005]}}];
h = CanonicalGraph[g,Method->"Nauty"]
Normal[AdjacencyMatrix[h]]
EdgeList[h]
GraphAutomorphismGroup[g]
GroupElements[%]Obtenemos en GroupElements[%] los siguientes automorfismos:
{Cycles[{}], Cycles[{{2,4},{3,7},{6,8}}], Cycles[{{1,3},{4,6},{7,9}}],
Cycles[{{1,3,9,7},{2,6,8,4}}], Cycles[{{1,7,9,3},{2,4,8,6}}], Cycles[{{1,7},{2,8},{3,9}}],
Cycles[{{1,9},{2,6},{4,8}}],Cycles[{{1,9},{2,8},{3,7},{4,6}}]}Recordando que en Wolfram los índices de los vértices se inician en 1 y en nuestra aplicación en 0, comprobamos que en ambos casos son los mismos automorfismos:
() Cycles[{}]
(0 2)(3 5)(6 8) Cycles[{{1,3},{4,6},{7,9}}]
(1 3)(2 6)(5 7) Cycles[{{2,4},{3,7},{6,8}}]
(0 6 8 2)(1 3 7 5) Cycles[{{1,7,9,3},{2,4,8,6}}]
(0 2 8 6)(1 5 7 3) Cycles[{{1,3,9,7},{2,6,8,4}}]
(0 8)(1 5)(3 7) Cycles[{{1,9},{2,6},{4,8}}]
(0 6)(1 7)(2 8) Cycles[{{1,7},{2,8},{3,9}}]
(0 8)(1 7)(2 6)(3 5) Cycles[{{1,9},{2,8},{3,7},{4,6}}]A continuación mostramos el árbol de particiones que también vimos en el tema anterior aplicando solo el refinamiento, donde observamos las 8 hojas o particiones triviales, que vienen a ser 8 permutaciones del total 9! = 362880 que tiene ese grafo con 9 nodos. Este árbol es exactamente igual que el que podemos ver en el documento de referencia [D2].

Ese árbol "tree" sólo se devuelve si está activada la traza, pues el algoritmo getPartitionTree() maneja el árbol en el campo "nodes" que devolvemos también en el resultado:
"nodes": [[[-1,[],[]]], [[0,[],[]],[0,[],[]],[0,[],[]],[0,[],[]]], [[0,[],[],"f*"],[0,[],[],"=(0 2)(3 5)(6 8)"],[1,[],[],"=(1 3)(2 6)(5 7)"],[1,[],[],"=(0 6 8 2)(1 3 7 5)"],[2,[],[],"=(0 2 8 6)(1 5 7 3)"],[2,[],[],"=(0 8)(1 5)(3 7)"],[3,[],[],"=(0 6)(1 7)(2 8)"],[3,[],[],"=(0 8)(1 7)(2 6)(3 5)"]]]
En el tercer nivel están las hojas, que presentamos ahora en vertical para su mejor visualización:
[-1,[],[]]
[0,[],[]]
[[0,[],[],"f*"]
[0,[],[],"=(0 2)(3 5)(6 8)"]
[0,[],[]]
[1,[],[],"=(1 3)(2 6)(5 7)"]
[1,[],[],"=(0 6 8 2)(1 3 7 5)"]
[0,[],[]]
[2,[],[],"=(0 2 8 6)(1 5 7 3)"]
[2,[],[],"=(0 8)(1 5)(3 7)"]
[0,[],[]]
[3,[],[],"=(0 6)(1 7)(2 8)"]
[3,[],[],"=(0 8)(1 7)(2 6)(3 5)"]Recordemos que con la traza activada agregamos a las hojas las notas "f" (de "first"), "=", "<" o ">" con un "*" para indicar cuál es la hoja canónica. Cada vez que lleguemos a una hoja con un etiquetado igual ("=") a la canónica (canonical label) habremos encontrado un automorfismo. Por eso, con la traza activada, agregamos los automorfismos a cada hoja en "nodes", a falta de la identidad "()" que se adjudica a la canónica marcada con "f*". En este ejemplo la canónica es la primera y el resto son todas iguales. Y también agregamos los automorfismos encontrados con cada hoja "=".
Poda con automorfismos
He de reconocer que esta parte de la poda con automorfismos es la que me resulta más díficil de implementar, pues no acabo de entender del todo los esquemas de esta parte de los algoritmos que he visto en la documentación. En cualquier caso he llevado a cabo mi implementación basándome en ejemplos de grafos que exponían también el árbol de particiones comprobando que eran iguales, o en algunos casos muy similares. Además lo complemento con el algoritmo testIsomorphisms() que veremos después y que verifica que el etiquetado canónico obtenido es correcto.
En cualquier caso vamos a exponer el primer principio para la poda con autormorfismos, que podemos ver en el punto tercero de la página 28 del documento de referencia [D7] de McKay y también en [D5] de McKay y Piperno:
Si μ1 y μ2 son hojas del árbol donde se encuentra el automorfismo γ tal μ2 = (μ1)γ, entonces γ mapea el subárbol descendente de μ1 en el árbol descendente de μ2. Así que cualquier etiquetado descendente de μ2 es igual que alguno descendente de μ1.
En el fondo viene a decir lo mismo que el punto (c) del teorema 2.15, página 56, del documento de referencia [D1] también de McKay:
Si μ1, μ2 ∈ T(G, π) y μ1 ~ μ2 entonces T(G, π, μ2-μ1) no contiene nodos identidad.
En lo anterior μ1 y μ2 son hojas del árbol de particiones T(G, π). La expresión μ1 ~ μ2 es una relación de equivalencia que significa que hay un automorfismo γ tal que μ2 = (μ1)γ. Un nodo terminal (u hoja) es identidad si no hay otro terminal anterior al que sea equivalente. Es lo que nosotros denominamos partición canónica (canonicalPartition) que marcamos con "*". Y con μ2-μ1 se denomina el subárbol generado para llegar a la hoja μ2 que comparte un padre común con el subárbol en el que se genera la hoja μ1. El que ese subárbol no contenga nodos identidad significa que ahí no va a encontrar alguna partición canónica, por lo que ese subárbol puede podarse.
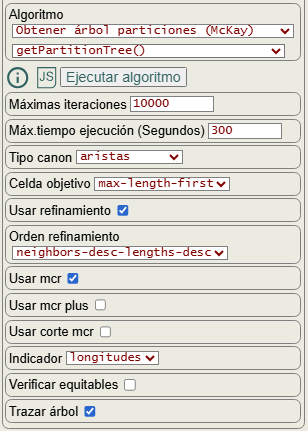
En la Figura vemos las opciones para ejecutar getPartitionTree(). Ya hemos explicado la opción usar refinamiento en el tema anterior, donde también expusimos las opciones celda objetivo (targetCell), orden refinamiento (orderRefine) así como verificar equitables.
En este tema veremos las opciones para poda con automorfismos, donde la principal es usar mcr (useMcr), con otras dos opciones usar mcr plus (useMcrPlus) y usar corte mcr (useMcrBreak) auxiliares que sólo se tienen en cuenta si la primera está activada, opciones que explicamos en un siguiente tema.
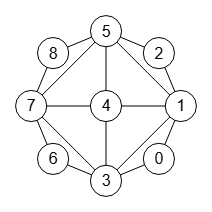
Siguiendo con el mismo grafo de ejemplo que vimos en el apartado anterior cuyo grafo del documento [D2] volvemos a repetir en la Figura y que puede importar en la aplicación con el JSON del archivo graph-sample-2.txt, vamos a obtener el árbol de particiones con refinamiento y poda automorfismos (sólo "useMcr"):
Time: 2 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":2,"timeIni":1,"timeRef":0,
"iter":11,"refine":6,"indexTree":5,
"leaves":3,
"prunningMcr":3,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanon":true,
"canonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[],"PA","PA"]],
[[0,[1],[]],[0,[3],[],"PA"]],
[[0,[1,3],[],"f*"],[0,[1,5],[],"=(0 2)(3 5)(6 8)"],[1,[3,1],[],"=(1 3)(2 6)(5 7)"]]],
"nodeBest":[2,0],
"mcr":[0,1,4],
"fixMcr":
[[[1,4,7],[0,1,3,4,6,7]],
[[0,4,8],[0,1,2,4,5,8]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":4,
"tree":[{"index":0,"value":"(1 3 5 7)(0 2 6 8)(4)","parent":-1},
{"index":1,"value":"(1)(3 5)(7)(0 2)(6 8)(4)","parent":[{"index":0,"value":"1"}]},
{"index":2,"value":"(1)(3)(5)(7)(0)(2)(6)(8)(4)","parent":[{"index":1,"value":"3"}]},
{"index":3,"value":"(1)(5)(3)(7)(2)(0)(8)(6)(4)","parent":[{"index":1,"value":"5"}]},
{"index":4,"value":"(3)(1 7)(5)(0 6)(2 8)(4)","parent":[{"index":0,"value":"3"}]},
{"index":5,"value":"(3)(1)(7)(5)(0)(6)(2)(8)(4)","parent":[{"index":4,"value":"1"}]}],
"automorphisms":
[[[0,2],[1],[3,5],[4],[6,8],[7]],
[[0],[1,3],[2,6],[4],[5,7],[8]]],
"automorphismsPlus":0}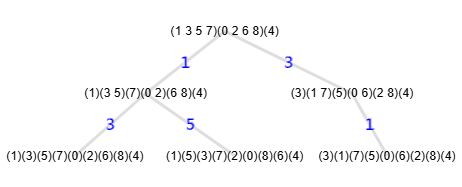
Con poda automorfismos hemos pasado de un árbol con sólo refinamiento de la Figura con 13 nodos, de los cuáles 8 eran hojas, a un árbol con 6 nodos y 3 hojas. Observe en la traza anterior "prunningMcr":3 que son las 3 podas realizadas en las ramas 7, 5 y 7 que veremos a continuación.

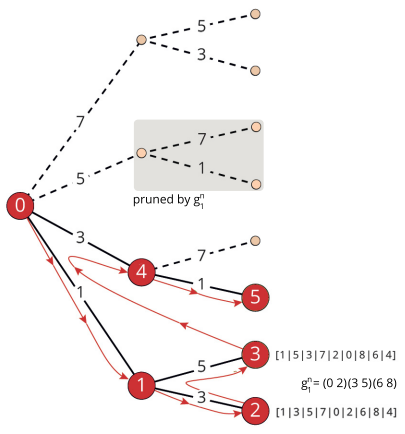
En la Figura vemos el árbol completo resaltando en color las ramas que se podan, podándose en las aristas 7, 5 y 7, lo que da lugar a que no se ejecuten sus subramas. Mientras que en la Figura vemos una imagen del mismo árbol que aparece en el documento de referencia [D2], de McKay y Piperno, donde los números de nodos se refieren al orden en que van siendo visitados, obteniéndose el mismo resultado.
Para explicar esto tenemos que ver el campo "nodes" que la aplicación maneja para las poda con automorfismos e indicadores, que no es otra cosa que el propio árbol de particiones que ya explicamos en un tema anterior, que junto a otros campos relacionados del resultado obtenido con poda automorfismos volvemos a repetir a continuación:
"nodes": [[[-1,[],[],"PA","PA"]], [[0,[1],[]],[0,[3],[],"PA"]], [[0,[1,3],[],"f*"],[0,[1,5],[],"=(0 2)(3 5)(6 8)"],[1,[3,1],[],"=(1 3)(2 6)(5 7)"]]], "nodeBest":[2,0], "mcr":[0,1,4], "fixMcr": [[[1,4,7],[0,1,3,4,6,7]], [[0,4,8],[0,1,2,4,5,8]]], "lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":4,
Observamos en "nodes" las 3 hojas del árbol de la Figura que junto a las particiones de las hojas vemos a continuación:
[[0,[1,3],[],"f*"], (1)(3)(5)(7)(0)(2)(6)(8)(4) [0,[1,5],[],"=(0 2)(3 5)(6 8)"], (1)(5)(3)(7)(2)(0)(8)(6)(4) [1,[3,1],[],"=(1 3)(2 6)(5 7)"]]], (3)(1)(7)(5)(0)(6)(2)(8)(4)
La primera hoja marcada con "f*" es la canonica (canonical label). Al llegar a la segunda al compararla y ser igual "=" encuentra el primer automorfismo (0 2)(3 5)(6 8). Al llegar a la tercera hoja "=" encuentra (1 3)(2 6)(5 7).
En "nodes" cada nodo tiene la estructura [indexParent, [], []], donde indexParent es el índice del nodo del nivel inmediato anterior que es el padre en el árbol. El primer subarray se usa para "fixMcr" que veremos en reconstruir el MCR en el tema siguiente. El segundo subarray se usa con la poda con indicadores que veremos en un siguiente tema. Los nodos hojas acompañan una cadena con texto informativo al final que sólo aparece cuando la traza está activada (f, =, <, >, *), algo que ya hemos explicado y que no es necesaria para la estructura de "nodes". La cadena "PA" también es informativa y se incluye cuando se produce una poda con automorfismos. Comprobamos en la Figura que se producen dos podas "PA" en el nodo raíz y otra "PA" en el segundo nodo del segundo nivel.
El campo "nodeBest":[2,0] almacena el nivel y posición del canónico, que es está en el segundo nivel, posición 0 (la primera hoja). A continuación explicaremos el campo "mcr" mientras que el campo "fixMcr" sólo se usa si al comparar hojas encontramos alguna que no sea "=", para lo cual habrá que reconstruir el MCR, algo que no pasa en este ejemplo.
Encontramos el primer automorfismo (0 2)(3 5)(6 8) en la segunda hoja "=", automorfismo que realmente se gestiona como [[0,2],[1],[3,5],[4],[6,8],[7]], del que obtenemos el MCR o minimum cell representative (representante mínimo de celda) tomando el primer vértice de cada celda, siendo entonces mcr= [0,1,3,4,6,7] que se guarda en el campo "mcr". Los vértices a fijar en cada nodo deben estar en mcr, pues en otro caso se podará ese nodo y su rama descendente. El algoritmo continua en el nodo raíz pues le quedan por computar los vértices "3,5,7".
Entrará en la rama que fija "3" en el nodo raíz pues ese vértice está en mcr= [0,1,3,4,6,7], entonces llega a la tercera hoja "=" encontrando el automorfismo (1 3)(2 6)(5 7) que es con Arrays [[0],[1,3],[2,6],[4],[5,7],[8]], siendo su mcr = [0,1,2,4,5,8]. Al encontrar este segundo mcr realiza la intersección con el anterior mcr = {0,1,3,4,6,7} ∩ {0,1,2,4,5,8} = {0,1,4} que es el que se guarda en el campo "mcr". Así al volver de la tercera hoja donde debe fijar el vértice 7 para llegar a la cuarta hoja, como "7" no está en mcr = [0,1,4] resultará podada. El algoritmo volverá al nodo raíz para fijar los vértices "5" y "7" que no están en mcr = [0,1,4], por lo que resultarán podadas también.
Observando los árboles de Figura y Figura esquematizamos a continuación la evolución del algoritmo:
node mcr partition automorphism
----------------------------------------------------------------------------------------
[[-1,[],[]] null (1 3 5 7)(0 2 6 8)(4)
[0,[1],[]] null (1)(3 5)(7)(0 2)(6 8)(4)
[0,[1,3],[],"f*"] null (1)(3)(5)(7)(0)(2)(6)(8)(4) ()
[0,[1,5],[],"="] null (1)(5)(3)(7)(2)(0)(8)(6)(4) (0 2)(3 5)(6 8)
[0,[3],[]] 0,1,3,4,6,7 (3)(1 7)(5)(0 6)(2 8)(4)
[1,[3,1],[],"="] 0,1,3,4,6,7 (3)(1)(7)(5)(0)(6)(2)(8)(4) (1 3)(2 6)(5 7)
[1,[3,7],[],"="] 0,1,4 (3)(7)(1)(5)(6)(0)(8)(2)(4) (0 6 8 2)(1 3 7 5)
[0,[5],[]] 0,1,4 (5)(1 7)(3)(2 8)(0 6)(4)
[2,[5,1],[],"="] 0,1,4 (5)(1)(7)(3)(2)(8)(0)(6)(4) (0 2 8 6)(1 5 7 3)
[2,[5,7],[],"="] 0,1,4 (5)(7)(1)(3)(8)(2)(6)(0)(4) (0 8)(1 5)(3 7)
[0,[7],[]] 0,1,4 (7)(3 5)(1)(6 8)(0 2)(4)
[3,[7,3],[],"="] 0,1,4 (7)(3)(5)(1)(6)(8)(0)(2)(4) (0 6)(1 7)(2 8)
[3,[7,5],[],"="] 0,1,4 (7)(5)(3)(1)(8)(6)(2)(0)(4) (0 8)(1 7)(2 6)(3 5)En este esquema tenemos los nodos que se visitan, con las celdas subrayadas que son las objetivo en cada nodo que no es partición discreta, en azul vemos los vértices que se fijan, que se filtran todos mientras "mcr" es nulo, pero en otro caso se filtran sólo si están en "mcr". En gris vemos los nodos que se podan. El campo "mcr" se intersecciona con el anterior cada vez que se encuentra un automorfismo. Al final resulta que todas las ramas que se podan son isomorfismos de las que no se podan.
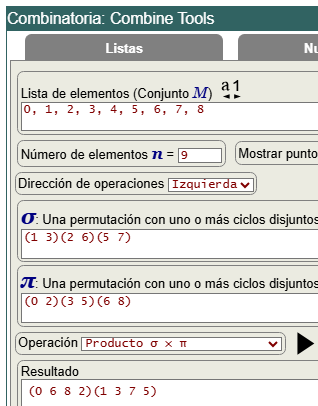
Para ver como las podas son isomorfismos que no es necesario ejecutar, vamos a usar la herramienta Combine Tools, usando el producto permutaciones cíclicas.
Ya hablamos del grupo de permutaciones, pues los automorfismos forman un grupo tal que el producto de ellos también es un automorfismo del grupo. Vamos a probar que cualquier hoja podada es una permutación de la primera hoja canónica.
Las dos primera hojas del primer subárbol son (1)(3)(5)(7)(0)(2)(6)(8)(4) y (1)(5)(3)(7)(2)(0)(8)(6)(4). En la tercera hoja ya hemos encontrado dos automorfismos (0 2)(3 5)(6 8) y (1 3)(2 6)(5 7). Primero hacemos el producto (1 3)(2 6)(5 7)x(0 2)(3 5)(6 8) obteniéndose (0 6 8 2)(1 3 7 5), que vemos en la tabla anterior que también es un automorfismo encontrado, precisamente el de la hoja 4 que se poda. Ese automorfismo en notación 1 línea corresponde a la permutación 6 3 0 7 4 1 8 5 2 (operación que puede calcularse en Combine Tools). Aplicando esta permutación a la hoja 4 vemos que llegamos a la primera:
(1 3)(2 6)(5 7) × (0 2)(3 5)(6 8) = (0 6 8 2)(1 3 7 5) ≡ 6 3 0 7 4 1 8 5 2 0 1 2 3 4 5 6 7 8 6 3 0 7 4 1 8 5 2 (3)(7)(1)(5)(6)(0)(8)(2)(4) hoja 4 1 3 5 7 0 2 6 8 4 = hoja 1
Para aplicar la permutación buscamos por ejemplo el primer "3" en la hoja 4 en los índices de la permutación en color verde y obtenemos el índice "1" en la lista en color azul. A continuación hacemos los mismo para la hoja 5:
(0 2)(3 5)(6 8) × (1 3)(2 6)(5 7) = (0 2 8 6)(1 5 7 3) ≡ 2 5 8 1 4 7 0 3 6 0 1 2 3 4 5 6 7 8 2 5 8 1 4 7 0 3 6 (5)(1)(7)(3)(2)(8)(0)(6)(4) hoja 5 1 3 5 7 0 2 6 8 4 = hoja 1
para la hoja 6:
(0 2 8 6)(1 5 7 3) × (0 2)(3 5)(6 8) = (0 8)(1 5)(3 7) ≡ 8 5 2 7 4 1 6 3 0 0 1 2 3 4 5 6 7 8 8 5 2 7 4 1 6 3 0 (5)(7)(1)(3)(8)(2)(6)(0)(4) hoja 6 1 3 5 7 0 2 6 8 4 = hoja 1
para la hoja 7:
(0 6 8 2)(1 3 7 5) × (1 3)(2 6)(5 7) = (0 6)(1 7)(2 8) ≡ 6 7 8 3 4 5 0 1 2 0 1 2 3 4 5 6 7 8 6 7 8 3 4 5 0 1 2 (7)(3)(5)(1)(6)(8)(0)(2)(4) hoja 7 1 3 5 7 0 2 6 8 4 = hoja 1
y para la hoja 8:
(0 6 8 2)(1 3 7 5) × (0 6 8 2)(1 3 7 5) = (0 8)(1 7)(2 6)(3 5) ≡ 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 8 7 6 5 4 3 2 1 0 (7)(5)(3)(1)(8)(6)(2)(0)(4) hoja 8 1 3 5 7 0 2 6 8 4 = hoja 1
Todos los automorfismos del grafo: "automorphisms": [[[0,2],[1],[3,5],[4],[6,8],[7]], [[0],[1,3],[2,6],[4],[5,7],[8]], [[0,6,8,2],[1,3,7,5],[4]], [[0,2,8,6],[1,5,7,3],[4]], [[0,8],[1,5],[2],[3,7],[4],[6]], [[0,6],[1,7],[2,8],[3],[4],[5]], [[0,8],[1,7],[2,6],[3,5],[4]]]
Los dos automorfismos (0 2)(3 5)(6 8) y (1 3)(2 6)(5 7) obtenidos en la traza al generar el árbol de particiones con la opción "useMcr" con poda de automorfismos, forman un conjunto fuerte de generación que representa a todo el grupo de automorfismos del grafo, que reproducimos al lado de este párrafo, al que falta agregar la identidad (), y que vemos en la traza obtenida al generar el árbol de particiones con sólo refinamiento, sin poda automorfismos. Los automorfismos (0 2)(3 5)(6 8) y (1 3)(2 6)(5 7) permiten mediante el producto generar todos los del grafo, como se observa en los cálculos anteriores.
En Wolfram Cloud con
GraphAutomorphismGroup[g]
PermutationGroup[{
Cycles[{{1,3},{4,6},{7,9}}],
Cycles[{{2,4},{3,7},{6,8}}]
}]
Con poda automorfismos obtenemos
"automorphisms":
[[[0,2],[1],[3,5],[4],[6,8],[7]],
[[0],[1,3],[2,6],[4],[5,7],[8]]]En la ejecución en Wolfram Cloud que vimos en la Figura, devolvía ese conjunto GraphAutomorphismGroup[g], que devuelve un PermutationGroup, con exactamente los mismos automorfismos que obtuvimos nosotros al usar la poda con autormofismos, aunque sin olvidar que Wolfram inicia los índices en 1 y nosotros en 0.
Tests isomorfismos testIsomorphisms()
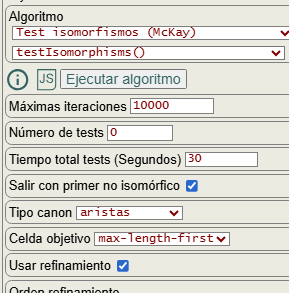
El algoritmo testIsomorphisms(), cuyo código veremos al final de este apartado, nos permite verificar que la obtención del etiquetado canónico es correcta. Se trata de obtener el etiquetado canónico del grafo y luego permutarlo tantas veces como especifique el campo número de tests que vemos en la Figura, aunque limitado con el campo tiempo total tests (segundos), pues cuando se supere ese tiempo finalizará devolviendo los resultados alcanzados. Con cada permutación del grafo se obtiene su etiquetado canónico y se comprueba que sea igual que el del grafo original.
Se pasan las mismas opciones que las usadas para ejecutar el algoritmo getPartitionTree() para obtener el etiquetado canónico (canonicalLabel) del grafo inicial y de las permutaciones a comprobar.
En caso de que indiquemos 0 tests, como es este caso, se realizarán n! permutaciones en orden siendo n el número de nodos del grafo, aunque se limita a las 9! = 362880 primeras permutaciones para grafos con más de 9 nodos. En otro caso si se pasan un número de tests se obtendrán permutaciones aleatorias del grafo inicial para la verificación.
El grafo de ejemplo tiene precisamente 9 nodos así que se comprueban todas las 362880 permutaciones del grafo, obteniéndose en el resultado que vemos a continuación "isomorphic":362880,"nonIsomorphic":0, resultando que con todas las permutaciones de ese grafo se obtiene el mismo etiquetado canónico y, por tanto, todas son isomórficas. En la Figura vemos que podamos cortar el test con la opción salir con el primer no isomórfico por si sucediera el caso de que encontrara alguna no isomórfica, algo que no he visto en todos los ejemplos que he comprobado, pero que me ha venido sirviendo para verificar la corrección del algoritmo mientras lo iba implementando.
Time: 27102 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","typeCanon":"edges","targetCell":"max-length-first","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"isomorphic":362880,"nonIsomorphic":0,
"firstTime":0,"minTime":0,"averageTime":0,"maxTime":12,
"iter1":11,"iter2":11,
"indexTree1":5,"indexTree2":5,
"minIndexTree":5,"maxIndexTree":7,
"refine1":6,"refine2":6,
"numAut1":2,"numAut2":2,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":3,"prunningMcr2":3,"prunningMcrBreak1":0,"prunningMcrBreak2":0,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":0,"prunningIndicators2b":0,Este es el JavaScript de testIsomorphisms(), que usa getPartitionTree() para obtener el etiquetado canónico. Se trata de obtenerlo para el grafo inicial y a continuación hacer un número de tests permutando ese grafo con la operación operatePermuteGraph() para obtener su etiquetado canónico y comprobar que coincide con el del grafo inicial. Esa comparación se realiza con la función compareCanon(). Usa también convertToAdjacencyMatrix() para convertir una lista de aristas a una matriz de adyacencia.
function testIsomorphisms({matrix=[], numberTest=100, timeTest=30, breakTest=false, permutation1=[],
useRefine=true, orderRefine="neighbors-desc-lengths-desc", typeCanon="edges", targetCell="max-length-first", useMcr=true, useMcrPlus=false, useMcrBreak=false, typeIndicator="none",
checkEquitables=false}) {
let result = {useRefine, orderRefine, typeCanon, targetCell, useMcr, useMcrPlus, useMcrBreak, typeIndicator,
isomorphic: 0, nonIsomorphic: 0,
firstTime:0, minTime:0, averageTime:0, maxTime:0,
iter1:0, iter2:0,
indexTree1:0, indexTree2:0, minIndexTree:0, maxIndexTree:0,
refine1:0, refine2:0,
numAut1: 0, numAut2: 0,
numAutPlus1: 0, numAutPlus2: 0,
prunningMcr1:0, prunningMcr2:0,
prunningMcrBreak1:0, prunningMcrBreak2:0,
rebuiltMcr1:0, rebuiltMcr2:0,
prunningIndicators1:0, prunningIndicators2:0,
prunningIndicators1b:0, prunningIndicators2b:0,
canonical: null};
try {
if (!verifyMode01(matrix)) throw new Error(`(testIsomorphisms) Matrix must come in mode 0/1`);
let n = matrix.length;
let indexes = Array.from({length: n}, (v,i) => i);
let time1 = new Date();
let temp = getPartitionTree({matrix, useRefine, orderRefine, typeCanon, targetCell, useMcr, useMcrPlus, useMcrBreak, typeIndicator, checkEquitables});
if (typeof temp==="string") throw new Error(temp);
let indexTrees = [];
let time2 = new Date();
let totalTime = time2 - time1;
result.firstTime = totalTime;
result.minTime = totalTime;
result.maxTime = totalTime;
result.iter1 = temp.iter;
result.indexTree1 = temp.indexTree;
indexTrees.push(temp.indexTree);
result.refine1 = temp.refine;
result.canonical = temp.canonicalLabel;
if (result.canonical===null) throw new Error(`Canonical is null`);
let canonical1 = result.canonical;
if (checkEquitables) {
result.initialEquitable1 = temp.initialEquitable;
result.initialEquitableForced1 = temp.initialEquitableForced;
result.nonEquitables1 = temp.nonEquitables;
}
result.numAut1 = temp.automorphisms;
result.numAutPlus1 = temp.automorphismsPlus;
result.prunningMcr1 = temp.prunningMcr;
result.prunningMcrBreak1 = temp.prunningMcrBreak;
result.rebuiltMcr1 = temp.rebuiltMcr;
result.prunningIndicators1 = temp.prunningIndicators;
result.prunningIndicators1b = temp.prunningIndicators2;
let allPerm = null;
if (permutation1.length>0) {
numberTest = 1;
} else if (numberTest===0) {
allPerm = permute(indexes);
numberTest = allPerm.length;
if (n>9) result.warnings = [`The graph has more than 9 nodes and only the first 9!=362880 permutations will be tested or less if the maximum time of ${timeTest} seconds is exceeded`];
} else if (timeTest>0) {
numberTest = Math.min(numberTest, Math.max(1, Math.ceil(timeTest*1000/totalTime)));
}
let ntest = 1;
for (ntest=1; ntest<=numberTest; ntest++) {
iter = 0;
let permutation = permutation1.length>0 ? permutation1 : allPerm===null ? permuteRandom(indexes) : allPerm[ntest-1];
temp = operatePermuteGraph({matrix, fromEdges:true, indexes: permutation, verify:false});
if (typeof temp==="string") throw new Error(temp);
let edges = temp.edges;
temp = convertToAdjacencyMatrix({array:edges, mode:"edgeList", compactUndirected:true});
if (typeof temp==="string") throw new Error(temp);
let matrix2 = temp;
matrix2.edges = edges;
iter = 0;
time1 = new Date();
temp = getPartitionTree({matrix:matrix2, useRefine, orderRefine, typeCanon, targetCell, useMcr, useMcrPlus, useMcrBreak, typeIndicator, checkEquitables});
if (typeof temp==="string") throw new Error(temp);
time2 = new Date();
let thisTime = time2-time1;
if (thisTime<result.minTime) result.minTime = thisTime;
if (thisTime>result.maxTime) result.maxTime = thisTime;
totalTime += thisTime;
result.iter2 = temp.iter;
result.indexTree2 = temp.indexTree;
indexTrees.push(temp.indexTree);
result.refine2 = temp.refine;
let canonical2 = temp.canonicalLabel;
if (canonical2===null) throw new Error(`Canonical2 is null`);
if (checkEquitables) {
result.initialEquitable2 = temp.initialEquitable;
result.initialEquitableForced2 = temp.initialEquitableForced;
result.nonEquitables2 = temp.nonEquitables;
}
result.numAut2 = temp.automorphisms;
result.numAutPlus2 = temp.automorphismsPlus;
result.prunningMcr2 = temp.prunningMcr;
result.prunningMcrBreak2 = temp.prunningMcrBreak;
result.rebuiltMcr2 = temp.rebuiltMcr;
result.prunningIndicators2 = temp.prunningIndicators;
result.prunningIndicators2b = temp.prunningIndicators2;
if (compareCanon(canonical1, canonical2, typeCanon)===0) {
result.isomorphic++;
} else {
result.nonIsomorphic++;
result.noCanonical = canonical2;
if (breakTest) break;
}
if (timeTest>0 && totalTime > timeTest*1000) break;
}
result.averageTime = Math.round(totalTime/(ntest+1));
indexTrees.sort((u,v) => u-v);
result.minIndexTree = indexTrees[0];
result.maxIndexTree = indexTrees[indexTrees.length-1];
} catch(e){result = e.message}
return result;
}Otros ejemplos donde sólo se usa "mcr"
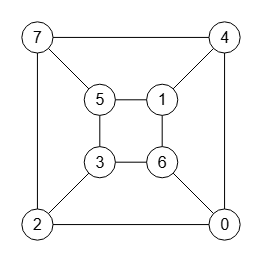
En la Figura vemos un grafo que se presenta en el documento [D3] y cuyo JSON puede importar en la aplicación con el archivo graph-sample-5.txt.
[[0,[0,1,3],[],"f*"], [0,[0,1,7],[],"=(3 7)(4 6)"], [1,[0,3,1],[],"=(1 3)(2 4)"], [2,[1,0,3],[],"=(0 1)(2 5)"], [3,[2,4,5],[],"=(0 2 3 5 1 4)(6 7)"]]]
El árbol de particiones tiene el mismo número de nodos y prácticamente es igual que el que vemos en el documento de referencia. Extrayendo el último nivel de nodos con las hojas, se observa que la primera hoja es la canónica "f*" y todas las demás son iguales "=", así que sólo usaremos la poda con "mcr".
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":33,"refine":13,"indexTree":12,
"leaves":5,
"prunningMcr":13,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[1],[3],[7],[5],[6],[4],[2]],
"firstCanon":true,
"canonicalPartition":[[0],[1],[3],[7],[5],[6],[4],[2]],
"firstCanonicalLabel":[[0,5],[0,6],[0,7],[1,4],[1,5],[1,6],[2,4],[2,5],[2,7],[3,4],[3,6],[3,7]],
"canonicalLabel":[[0,5],[0,6],[0,7],[1,4],[1,5],[1,6],[2,4],[2,5],[2,7],[3,4],[3,6],[3,7]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[],"PA","PA","PA","PA","PA"]],
[[0,[0],[],"PA"],[0,[1],[],"PA","PA"],[0,[2],[],"PA","PA"]],
[[0,[0,1],[]],[0,[0,3],[],"PA"],[1,[1,0],[],"PA"],[2,[2,4],[],"PA"]],
[[0,[0,1,3],[],"f*"],[0,[0,1,7],[],"=(3 7)(4 6)"],[1,[0,3,1],[],"=(1 3)(2 4)"],[2,[1,0,3],[],"=(0 1)(2 5)"],[3,[2,4,5],[],"=(0 2 3 5 1 4)(6 7)"]]],
"nodeBest":[3,0],
"mcr":[0],
"fixMcr":
[[[0,1,2,5],[0,1,2,3,4,5]],
[[0,5,6,7],[0,1,2,5,6,7]],
[[3,4,6,7],[0,2,3,4,6,7]],
[[],[0,6]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":16,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7)","parent":-1},
{"index":1,"value":"(0)(1 3 7)(5)(2 4 6)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(3 7)(5)(4 6)(2)","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(1)(3)(7)(5)(6)(4)(2)","parent":[{"index":2,"value":"3"}]},
{"index":4,"value":"(0)(1)(7)(3)(5)(4)(6)(2)","parent":[{"index":2,"value":"7"}]},
{"index":5,"value":"(0)(3)(1 7)(5)(2 6)(4)","parent":[{"index":1,"value":"3"}]},
{"index":6,"value":"(0)(3)(1)(7)(5)(6)(2)(4)","parent":[{"index":5,"value":"1"}]},
{"index":7,"value":"(1)(0 3 7)(2)(4 5 6)","parent":[{"index":0,"value":"1"}]},
{"index":8,"value":"(1)(0)(3 7)(2)(4 6)(5)","parent":[{"index":7,"value":"0"}]},
{"index":9,"value":"(1)(0)(3)(7)(2)(6)(4)(5)","parent":[{"index":8,"value":"3"}]},
{"index":10,"value":"(2)(4 5 6)(1)(0 3 7)","parent":[{"index":0,"value":"2"}]},
{"index":11,"value":"(2)(4)(5 6)(1)(0 7)(3)","parent":[{"index":10,"value":"4"}]},
{"index":12,"value":"(2)(4)(5)(6)(1)(7)(0)(3)","parent":[{"index":11,"value":"5"}]}],
"automorphisms":
[[[0],[1],[2],[3,7],[4,6],[5]],
[[0],[1,3],[2,4],[5],[6],[7]],
[[0,1],[2,5],[3],[4],[6],[7]],
[[0,2,3,5,1,4],[6,7]]],
"automorphismsPlus":0}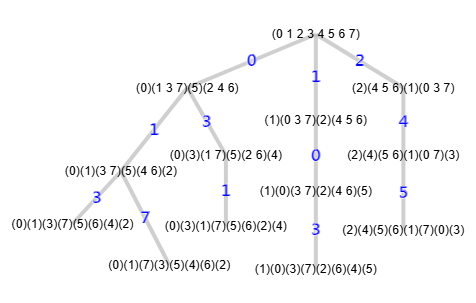
En la Figura vemos el árbol de particiones y a continuación el test de isormofismos, observando que todas las 8! = 40320 permutaciones del grafo resultaron isomórficas.
Time: 3895 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","typeCanon":"edges","targetCell":"first","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"isomorphic":40320,"nonIsomorphic":0,
"firstTime":2,"minTime":0,"averageTime":0,"maxTime":2,
"iter1":33,"iter2":36,
"indexTree1":12,"indexTree2":14,
"minIndexTree":9,"maxIndexTree":14,
"refine1":13,"refine2":15,
"numAut1":4,"numAut2":5,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":13,"prunningMcr2":13,"prunningMcrBreak1":0,"prunningMcrBreak2":0,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":0,"prunningIndicators2b":0,
"canonical":[[0,5],[0,6],[0,7],[1,4],[1,5],[1,6],[2,4],[2,5],[2,7],[3,4],[3,6],[3,7]]}Lo exportamos a Wolfram Cloud con este código:
g = AdjacencyGraph[{{0,0,1,0,1,0,1,0},{0,0,0,0,1,1,1,0},{1,0,0,1,0,0,0,1},{0,0,1,0,0,1,1,0},{1,1,0,0,0,0,0,1},{0,1,0,1,0,0,0,1},{1,1,0,1,0,0,0,0},{0,0,1,0,1,1,0,0}},
ImageSize -> 263, VertexSize -> {"Scaled", 0.12}, VertexLabels -> {1 -> Placed[0,Center], 2 -> Placed[1,Center], 3 -> Placed[2,Center], 4 -> Placed[3,Center], 5 -> Placed[4,Center],
6 -> Placed[5,Center], 7 -> Placed[6,Center], 8 -> Placed[7,Center]}, VertexLabelStyle -> Directive[Black,17.5], EdgeLabelStyle -> Directive[Black,17.5,Bold],
VertexStyle -> White, EdgeStyle -> {{Black,Thickness[0.005]}}];
h = CanonicalGraph[g,Method->"Nauty"]
Normal[AdjacencyMatrix[h]]
EdgeList[h]
GraphAutomorphismGroup[g]
GroupElements[%]
PermutationGroup[{
Cycles[{{4,8},{5,7}}],
Cycles[{{2,4},{3,5}}],
Cycles[{{1,2},{3,6}}],
Cycles[{{1,3,4,6,2,5},{7,8}}]}]
"automorphisms":
[[[0],[1],[2],[3,7],[4,6],[5]],
[[0],[1,3],[2,4],[5],[6],[7]],
[[0,1],[2,5],[3],[4],[6],[7]],
[[0,2,3,5,1,4],[6,7]]]Comprobamos que con GraphAutomorphismGroup[g] se obtienen los mismos automorfismos, que es el conjunto fuerte de generación cuando aplicamos poda automorfismos, pus son el mínimo número de automorfismos sobre los que, aplicando producto de permutaciones, permiten generar todo el grupo de automorfismos del grafo que se obtienen con GroupElements[%] y que nosotros podíamos obtener aplicando sólo refinamiento sin poda automorfismos. Recuerde que Wolfram inicia los índices en 1 y nosotros en 0, además omite las particiones triviales. Si ejecutamos el algoritmo sólo con refinamiento y sin poda automorfismos obtendremos todo el grupo de automorfismos del grafo, que son los mismos que Wolfram encuentra con GroupElements[%], a excepción del automorfismo identidad que es implícito:
GroupElements[%] in Wolfram "automorphisms" with only refinement
--------------------------------------------------------------------
{Cycles[{}],
Cycles[{{4,8},{5,7}}], [[[0],[1],[2],[3,7],[4,6],[5]],
Cycles[{{2,4},{3,5}}], [[0],[1,3],[2,4],[5],[6],[7]],
Cycles[{{2,4,8},{3,5,7}}], [[0],[1,3,7],[2,4,6],[5]],
Cycles[{{2,8,4},{3,7,5}}], [[0],[1,7,3],[2,6,4],[5]],
Cycles[{{2,8},{3,7}}], [[0],[1,7],[2,6],[3],[4],[5]],
Cycles[{{1,2},{3,6}}], [[0,1],[2,5],[3],[4],[6],[7]],
Cycles[{{1,2},{3,6},{4,8},{5,7}}], [[0,1],[2,5],[3,7],[4,6]],
Cycles[{{1,2,4},{3,5,6}}], [[0,1,3],[2,4,5],[6],[7]],
Cycles[{{1,2,4,8},{3,5,7,6}}], [[0,1,3,7],[2,4,6,5]],
Cycles[{{1,2,8,4},{3,7,5,6}}], [[0,1,7,3],[2,6,4,5]],
Cycles[{{1,2,8},{3,7,6}}], [[0,1,7],[2,6,5],[3],[4]],
Cycles[{{1,3,4,6,2,5},{7,8}}], [[0,2,3,5,1,4],[6,7]],
Cycles[{{1,3,4,7},{2,5,8,6}}], [[0,2,3,6],[1,4,7,5]],
Cycles[{{1,3},{2,6},{4,5},{7,8}}], [[0,2],[1,5],[3,4],[6,7]],
Cycles[{{1,3},{2,6},{4,7},{5,8}}], [[0,2],[1,5],[3,6],[4,7]],
Cycles[{{1,3,8,6,2,7},{4,5}}], [[0,2,7,5,1,6],[3,4]],
Cycles[{{1,3,8,5},{2,7,4,6}}], [[0,2,7,4],[1,6,3,5]],
Cycles[{{1,4,2},{3,6,5}}], [[0,3,1],[2,5,4],[6],[7]],
Cycles[{{1,4,8,2},{3,6,5,7}}], [[0,3,7,1],[2,5,4,6]],
Cycles[{{1,4},{5,6}}], [[0,3],[1],[2],[4,5],[6],[7]],
Cycles[{{1,4,8},{5,7,6}}], [[0,3,7],[1],[2],[4,6,5]],
Cycles[{{1,4},{2,8},{3,7},{5,6}}], [[0,3],[1,7],[2,6],[4,5]],
Cycles[{{1,4,2,8},{3,7,6,5}}], [[0,3,1,7],[2,6,5,4]],
Cycles[{{1,5},{2,3},{4,6},{7,8}}], [[0,4],[1,2],[3,5],[6,7]],
Cycles[{{1,5,8,6,4,7},{2,3}}], [[0,4,7,5,3,6],[1,2]],
Cycles[{{1,5,2,6,4,3},{7,8}}], [[0,4,1,5,3,2],[6,7]],
Cycles[{{1,5,8,3},{2,6,4,7}}], [[0,4,7,2],[1,5,3,6]],
Cycles[{{1,5,2,7},{3,8,6,4}}], [[0,4,1,6],[2,7,5,3]],
Cycles[{{1,5},{2,7},{3,8},{4,6}}], [[0,4],[1,6],[2,7],[3,5]],
Cycles[{{1,6},{2,3},{4,5},{7,8}}], [[0,5],[1,2],[3,4],[6,7]],
Cycles[{{1,6},{2,3},{4,7},{5,8}}], [[0,5],[1,2],[3,6],[4,7]],
Cycles[{{1,6},{2,5},{3,4},{7,8}}], [[0,5],[1,4],[2,3],[6,7]],
Cycles[{{1,6},{2,5,8,3,4,7}}], [[0,5],[1,4,7,2,3,6]],
Cycles[{{1,6},{2,7,4,3,8,5}}], [[0,5],[1,6,3,2,7,4]],
Cycles[{{1,6},{2,7},{3,8},{4,5}}], [[0,5],[1,6],[2,7],[3,4]],
Cycles[{{1,7},{2,3},{4,5},{6,8}}], [[0,6],[1,2],[3,4],[5,7]],
Cycles[{{1,7,4,6,8,5},{2,3}}], [[0,6,3,5,7,4],[1,2]],
Cycles[{{1,7},{2,5},{3,4},{6,8}}], [[0,6],[1,4],[2,3],[5,7]],
Cycles[{{1,7,2,5},{3,4,6,8}}], [[0,6,1,4],[2,3,5,7]],
Cycles[{{1,7,4,3},{2,6,8,5}}], [[0,6,3,2],[1,5,7,4]],
Cycles[{{1,7,2,6,8,3},{4,5}}], [[0,6,1,5,7,2],[3,4]],
Cycles[{{1,8,4,2},{3,6,7,5}}], [[0,7,1,3],[2,4,5,6]],
Cycles[{{1,8,2},{3,6,7}}], [[0,7,1],[2,5,6],[3],[4]],
Cycles[{{1,8,4},{5,6,7}}], [[0,7,3],[1],[2],[4,5,6]],
Cycles[{{1,8},{6,7}}], [[0,7],[1],[2],[3],[4],[5,6]],
Cycles[{{1,8,2,4},{3,5,6,7}}], [[0,7,3,1],[2,5,6,4]],
Cycles[{{1,8},{2,4},{3,5},{6,7}}] [[0,7],[1,3],[2,4],[5,6]]]
En la Figura vemos otro grafo de ejemplo del documento de referencia [D4] que puede importar en la aplicación con el JSON del archivo graph-sample-6.txt.
[[0,[0,2],[],"f*"], [0,[0,6],[],"=(1 3)(2 6)(5 7)"], [1,[2,0],[],"=(0 2)(3 5)(6 8)"]]]
Los nodos hojas tienen la primera partición canónica "f*" y las dos siguientes iguales "=", por lo que se aplica sólo poda "mcr" tal y como hemos venido haciendo en los ejemplos anteriores.
Time: 0 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-asc","targetCell":"first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":0,"timeIni":0,"timeRef":0,
"iter":11,"refine":6,"indexTree":5,
"leaves":3,
"prunningMcr":3,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[8],[2],[6],[7],[5],[3],[1],[4]],
"firstCanon":true,
"canonicalPartition":[[0],[8],[2],[6],[7],[5],[3],[1],[4]],
"firstCanonicalLabel":[[0,6],[0,7],[1,4],[1,5],[2,5],[2,7],[3,4],[3,6],[4,8],[5,8],[6,8],[7,8]],
"canonicalLabel":[[0,6],[0,7],[1,4],[1,5],[2,5],[2,7],[3,4],[3,6],[4,8],[5,8],[6,8],[7,8]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[],"PA","PA"]],
[[0,[0],[]],[0,[2],[],"PA"]],
[[0,[0,2],[],"f*"],[0,[0,6],[],"=(1 3)(2 6)(5 7)"],[1,[2,0],[],"=(0 2)(3 5)(6 8)"]]],
"nodeBest":[2,0],
"mcr":[0,1,4],
"fixMcr":
[[[0,4,8],[0,1,2,4,5,8]],
[[1,4,7],[0,1,3,4,6,7]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":4,
"tree":[{"index":0,"value":"(0 2 6 8)(1 3 5 7)(4)","parent":-1},
{"index":1,"value":"(0)(8)(2 6)(5 7)(1 3)(4)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(8)(2)(6)(7)(5)(3)(1)(4)","parent":[{"index":1,"value":"2"}]},
{"index":3,"value":"(0)(8)(6)(2)(5)(7)(1)(3)(4)","parent":[{"index":1,"value":"6"}]},
{"index":4,"value":"(2)(6)(0 8)(3 7)(1 5)(4)","parent":[{"index":0,"value":"2"}]},
{"index":5,"value":"(2)(6)(0)(8)(7)(3)(5)(1)(4)","parent":[{"index":4,"value":"0"}]}],
"automorphisms":
[[[0],[1,3],[2,6],[4],[5,7],[8]],
[[0,2],[1],[3,5],[4],[6,8],[7]]],
"automorphismsPlus":0}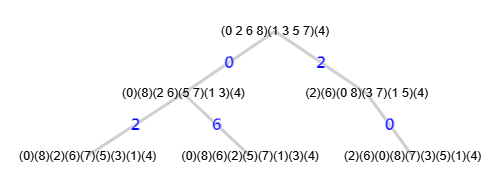
En la Figura vemos el árbol de particiones que es exactamente igual que el del documento de referencia.
Y a continuación vemos el resultado del test isomorfismos, donde se han verificado las 9! = 362880 permutaciones del grafo satisfactoriamente.
Time: 24074 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-asc","typeCanon":"edges","targetCell":"first","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"isomorphic":362880,"nonIsomorphic":0,
"firstTime":2,"minTime":0,"averageTime":0,"maxTime":2,
"iter1":11,"iter2":14,
"indexTree1":5,"indexTree2":7,
"minIndexTree":5,"maxIndexTree":7,
"refine1":6,"refine2":8,
"numAut1":2,"numAut2":3,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":3,"prunningMcr2":3,"prunningMcrBreak1":0,"prunningMcrBreak2":0,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":0,"prunningIndicators2b":0,
"canonical":[[0,6],[0,7],[1,4],[1,5],[2,5],[2,7],[3,4],[3,6],[4,8],[5,8],[6,8],[7,8]]}Lo exportamos a Wolfram Cloud con este código:
g = AdjacencyGraph[{{0,1,0,1,0,0,0,0,0},{1,0,1,0,1,0,0,0,0},{0,1,0,0,0,1,0,0,0},{1,0,0,0,1,0,1,0,0},{0,1,0,1,0,1,0,1,0},{0,0,1,0,1,0,0,0,1},{0,0,0,1,0,0,0,1,0},
{0,0,0,0,1,0,1,0,1},{0,0,0,0,0,1,0,1,0}}, ImageSize -> 250, VertexSize -> {"Scaled", 0.13}, VertexLabels -> {1 -> Placed[0,Center], 2 -> Placed[1,Center], 3 -> Placed[2,Center],
4 -> Placed[3,Center], 5 -> Placed[4,Center], 6 -> Placed[5,Center], 7 -> Placed[6,Center], 8 -> Placed[7,Center], 9 -> Placed[8,Center]}, VertexLabelStyle -> Directive[Black,17.5],
EdgeLabelStyle -> Directive[Black,17.5,Bold], VertexStyle -> White, EdgeStyle -> {{Black,Thickness[0.005]}}];
h = CanonicalGraph[g,Method->"Nauty"]
Normal[AdjacencyMatrix[h]]
EdgeList[h]
GraphAutomorphismGroup[g]
GroupElements[%]
PermutationGroup[{
Cycles[{{2,4},{3,7},{6,8}}],
Cycles[{{1,3},{4,6},{7,9}}]}]
"automorphisms":
[[[0],[1,3],[2,6],[4],[5,7],[8]],
[[0,2],[1],[3,5],[4],[6,8],[7]]]Vemos a la izquierda que se obtienen los mismos automorfismos como conjunto generador que los obtenidos en Wolfram con GraphAutomorphismGroup[g]. Y si ejecutamos el árbol sin MCR, sólo con refinamiento, se obtienen los mismos que GroupElements[%], teniendo en cuenta que la aplicación obvia la identidad y que los índices se inician en 0.
Automorfismos en Wolfram Y en la aplicación
--------------------------------------------------------------------
{Cycles[{}],
Cycles[{{2,4},{3,7},{6,8}}], [[0],[1,3],[2,6],[4],[5,7],[8]],
Cycles[{{1,3},{4,6},{7,9}}], [[0,2],[1],[3,5],[4],[6,8],[7]]
Cycles[{{1,3,9,7},{2,6,8,4}}], [[0,2,8,6],[1,5,7,3],[4]],
Cycles[{{1,7,9,3},{2,4,8,6}}], [[0,6,8,2],[1,3,7,5],[4]],
Cycles[{{1,7},{2,8},{3,9}}], [[0,6],[1,7],[2,8],[3],[4],[5]],
Cycles[{{1,9},{2,6},{4,8}}], [[0,8],[1,5],[2],[3,7],[4],[6]],
Cycles[{{1,9},{2,8},{3,7},{4,6}}]} [[0,8],[1,7],[2,6],[3,5],[4]]
En la Figura vemos otro ejemplo del documento de referencia [D7] que puede importar en la aplicación con el JSON en el archivo graph-sample-9.txt.
[[0,[0,3],[],"f*"], [0,[0,4],[],"=(2 5)(3 4)"], [1,[3,0],[],"=(0 3)(1 2)(4 7)(5 6)"]]]
Sólo hay 3 hojas en el árbol, siendo la primera la canónica "f*" y las otras iguales "=", con lo que se aplica poda con sólo "mcr" como hemos venido haciendo en los ejemplos anteriores.
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-asc","targetCell":"first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":11,"refine":6,"indexTree":5,
"leaves":3,
"prunningMcr":3,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[3],[4],[7],[5],[2],[6],[1]],
"firstCanon":true,
"canonicalPartition":[[0],[3],[4],[7],[5],[2],[6],[1]],
"firstCanonicalLabel":[[0,3],[0,7],[1,2],[1,5],[2,4],[3,6],[4,5],[4,6],[4,7],[5,6],[5,7],[6,7]],
"canonicalLabel":[[0,3],[0,7],[1,2],[1,5],[2,4],[3,6],[4,5],[4,6],[4,7],[5,6],[5,7],[6,7]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[],"PA","PA"]],
[[0,[0],[]],[0,[3],[],"PA"]],
[[0,[0,3],[],"f*"],[0,[0,4],[],"=(2 5)(3 4)"],[1,[3,0],[],"=(0 3)(1 2)(4 7)(5 6)"]]],
"nodeBest":[2,0],
"mcr":[0,1],
"fixMcr":
[[[0,1,6,7],[0,1,2,3,6,7]],
[[],[0,1,4,5]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":4,
"tree":[{"index":0,"value":"(0 3 4 7)(1 2 5 6)","parent":-1},
{"index":1,"value":"(0)(3 4)(7)(2 5)(6)(1)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(3)(4)(7)(5)(2)(6)(1)","parent":[{"index":1,"value":"3"}]},
{"index":3,"value":"(0)(4)(3)(7)(2)(5)(6)(1)","parent":[{"index":1,"value":"4"}]},
{"index":4,"value":"(3)(0 7)(4)(1 6)(5)(2)","parent":[{"index":0,"value":"3"}]},
{"index":5,"value":"(3)(0)(7)(4)(6)(1)(5)(2)","parent":[{"index":4,"value":"0"}]}],
"automorphisms":
[[[0],[1],[2,5],[3,4],[6],[7]],
[[0,3],[1,2],[4,7],[5,6]]],
"automorphismsPlus":0}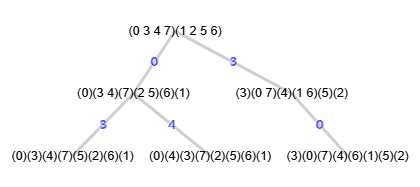
El árbol de particiciones obtenido que vemos en la Figura es exactamente el mismo que vemos en el documento de referencia, a excepción de los índices que aquí se inician en 0 y en el documento en 1.
Time: 2680 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-asc","typeCanon":"edges","targetCell":"first","useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"isomorphic":40320,"nonIsomorphic":0,
"firstTime":0,"minTime":0,"averageTime":0,"maxTime":3,
"iter1":11,"iter2":14,
"indexTree1":5,"indexTree2":7,
"minIndexTree":5,"maxIndexTree":7,
"refine1":6,"refine2":8,
"numAut1":2,"numAut2":3,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":3,"prunningMcr2":3,"prunningMcrBreak1":0,"prunningMcrBreak2":0,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":0,"prunningIndicators2b":0,
"canonical":[[0,3],[0,7],[1,2],[1,5],[2,4],[3,6],[4,5],[4,6],[4,7],[5,6],[5,7],[6,7]]}Lo exportamos a Wolfram Cloud con este código:
g = AdjacencyGraph[{{0,1,0,0,0,0,0,1},{1,0,1,0,0,1,1,0},{0,1,0,1,0,1,1,0},{0,0,1,0,1,0,0,0},{0,0,0,1,0,1,0,0},{0,1,1,0,1,0,1,0},{0,1,1,0,0,1,0,1},{1,0,0,0,0,0,1,0}},
ImageSize -> 141, VertexSize -> {"Scaled", 0.22}, VertexLabels -> {1 -> Placed[0,Center], 2 -> Placed[1,Center], 3 -> Placed[2,Center], 4 -> Placed[3,Center], 5 -> Placed[4,Center],
6 -> Placed[5,Center], 7 -> Placed[6,Center], 8 -> Placed[7,Center]}, VertexLabelStyle -> Directive[Black,17.5], EdgeLabelStyle -> Directive[Black,17.5,Bold],
VertexStyle -> White, EdgeStyle -> {{Black,Thickness[0.005]}}];
h = CanonicalGraph[g,Method->"Nauty"]
Normal[AdjacencyMatrix[h]]
EdgeList[h]
GraphAutomorphismGroup[g]
GroupElements[%]
PermutationGroup[{
Cycles[{{3,6},{4,5}}],
Cycles[{{1,4},{2,3},{5,8},{6,7}}]}]
"automorphisms":
[[[0],[1],[2,5],[3,4],[6],[7]],
[[0,3],[1,2],[4,7],[5,6]]]Obtenemos el mismo conjunto generador de automorfismos que en Wolfram y los mismos que vemos en el documento de referencia.