Particiones y rimas
Particiones y rimas

Las particiones también cuentan el número de esquemas de rimas de un poema. Entonces podemos generar B(n) particiones y por tanto rimas distintas. Si el conjunto de partida son n líneas de poemas (o versos) numeradas 1..n, podemos generar B(n) posibles formas de disponer las rimas en esas líneas.
Por ejemplo, con n=3 disponemos del conjunto de partida de líneas numeradas {1, 2, 3}, generándose las particiones 123, 12.3, 13.2, 1.23, 1.2.3 expresadas de forma compacta. Cada dígito representa la línea donde hemos de incluir una rima entre [A, B, C], que se van seleccionando en orden. Así una partición como 12.3 se traduce como AAB indicando que las 2 primeras líneas riman, pues están en el mismo subconjunto. Y la tercera no rima con ninguna al ser única en su subconjunto. Veamos todas las rimas para n=3 usando la notación de Arrays que es como se maneja en la aplicación:
- [[1, 2, 3]] ≡ AAA
- [[1, 2], [3]] ≡ AAB
- [[1, 3], [2]] ≡ ABA
- [[1], [2, 3]] ≡ ABB
- [[1], [2], [3]] ≡ ABC
Por ejemplo, los siguientes versos se encuentran al final de la obra Don Quijote de la Mancha, como epitafio que el autor dice que le dedicó el personaje Sansón Carrasco a la muerte de Don Quijote:
Yace aquí el Hidalgo fuerte [A]
que a tanto extremo llegó [B]
de valiente, que se advierte [A]
que la muerte no triunfó [B]
su vida con su muerte. [A]
Tuvo a todo el mundo en poco; [C]
fue el espantajo y el coco [C]
del mundo en coyuntura, [D]
que acreditó su ventura [D]
morir cuerdo y vivir loco. [C]
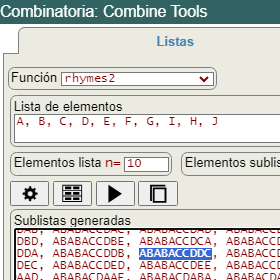
Son dos quintetos donde se observa las rimas ABABA CCDDC, correspondiendo a un conjunto con 10 elementos que se corresponden con las letras A, B, C, D, E, F, G, H, I, J, con los cuales pueden obtenerse B(10) = 115975 particiones y por tanto también rimas. Una de ellas es esa que vemos en la Figura obtenida en la aplicación.
Podríamos considerar cada estrofa de cinco líneas de forma separada, teniendo entonces que la primera estrofa tiene por rima ABABA y la segunda AABBA, pero es usual considerar todas las rimas del poema en un mismo grupo.
Otro ejemplo es el Soneto con 2 cuartetos y 2 tercetos con rima como ABBA ABBA CDC DCD , como este famoso soneto de Lope de Vega que trata de como se escribe un soneto:
Un soneto me manda hacer Violante, [A]
que en mi vida me he visto en tal aprieto: [B]
Catorce versos dicen que es soneto: [B]
Burla burlando van los tres delante. [A]
Yo pensé que no hallara consonante [A]
y estoy a la mitad de otro cuarteto: [B]
Mas si me veo en el primer terceto [B]
no hay cosa en los cuartetos que me espante. [A]
Por el primer terceto voy entrando [C]
y parece que entré con pie derecho, [D]
pues fin con este verso le voy dando. [C]
Ya estoy en el segundo, y aun sospecho [D]
que estoy los trece versos acabando: [C]
contad si son catorce, y está hecho. [D]
Primer algoritmo para implementar rimas
Es importante entender que hemos de generar las particiones de las líneas o versos, no de las rimas. Si tenemos un poema con n líneas podrá haber también hasta n rimas distintas, que es cuando ningún verso rima. Por lo tanto en lugar de partir del conjunto, por ejemplo, {A, B, C} partiremos del conjunto de numeraciones de líneas {0, 1, 2}, que empezamos con cero como es usual en programación. Al devolver cada partición convertiremos las numeraciones de líneas en rimas usando las letras {A, B, C}.
Para implementar el primer algoritmo para generar rimas usaremos el algoritmo partition4(listn), donde listn es la lista de números de línea, algo como el Array de números [0, 1, 2].
// B(n) = sum_(j=0)^(n) S2(n, j)
function rhymes1(list=[]){
let result = [];
let n = list.length;
//iter += n;
let listn = Array.from({length: n}, (v,i) => i);
let partitions = partition4(listn);
for (let i=0; i<partitions.length; i++) {
//iter += 1;
let lines = [];
for (let j=0; j<partitions[i].length; j++) {
//iter += 1;
for (let k=0; k<partitions[i][j].length; k++) {
//iter += 1;
let pos = partitions[i][j][k];
lines[pos] = list[j];
}
}
result.push(lines);
}
return result;
}Observando el coste del bucle exterior hay B(n) particiones. De forma experimental el coste de los dos bucles interiores, que convierten una partición como como [[1, 2], [3]] en la rima AAB, es:
Por encima de los bucles hay un coste n para montar listn más el coste de Tp de partition4(list), por lo que el coste total es:
con lo que el coste final es:
Donde Tp(n) es el coste del algoritmo partition4(list):
Y B(n) es el número de Bell con esta recurrencia:
B(n) = ∑j=0..n-1 C(n-1, j) B(j)
Y B(n, k) es el Triángulo de Bell con la siguiente fórmula recursiva:
B(n, 0) = B(n-1, n-1),
B(n, k) = B(n, k-1) + B(n-1, k-1)
Segundo algoritmo para implementar rimas
El algoritmo para generar las particiones con rimas lo haremos usando el propio código del algoritmo partition4(list) que era el más eficiente que vimos para generar todas las particiones, que usaba los números de Stirling de segunda clase:
// B(n) = sum_(j=0)^(n) S2(n, j)
function rhymes2(list=[], n=list.length, res=[], result=[]){
if (n===0) {
//iter += 1;
let lines = [];
for (let j=0; j<res.length; j++) {
//iter += 1;
let item = list[j];
for (let k=0; k<res[j].length; k++) {
//iter += 1;
let pos = res[j][k];
lines[pos] = item;
}
}
result.push(lines);
} else {
//iter += 1;
let pivot = list.length-n;
for (let j=0; j<res.length; j++) {
//iter += 1;
res[j].push(pivot);
rhymes2(list, n-1, res, result);
res[j].pop();
}
res.push([pivot]);
rhymes2(list, n-1, res, result);
res.pop();
}
return result;
}Cuando lleguemos al caso base convertimos un partición como [[1, 2], [3]] en la rima AAB. El coste exacto es el del algoritmo partition4(list), la segunda fórmula:
A lo que hay que sumar el coste de la conversión de partición en rimas, que son los bucles que encontramos en el caso base, que podemos llamar Tc(n), tal como obtuvimos en el apartado anterior de forma experimental:
Sumando Tc(n) y Tp(n)
= 2 B(n, n-1) + (n+1) B(n) - B(n+1) + B(n) + ∑i=0..n C(n+1, i+1) B(i)
Con lo que el coste final es:
Donde B(n) es el número de Bell con esta recurrencia:
B(n) = ∑j=0..n-1 C(n-1, j) B(j)
Y B(n, k) es el Triángulo de Bell con la siguiente fórmula recursiva:
B(n, 0) = B(n-1, n-1),
B(n, k) = B(n, k-1) + B(n-1, k-1)
Rimas con coincidencias
Las rimas coincidentes se refiere a evitar aquellos poemas donde no haya ningún verso que no rime con otros. Esto equivale a evitar particiones con bloques unitarios.
Hay B(n) particiones para un conjunto con n elementos. Si quitamos las particiones que contengan subconjuntos o bloques unitarios, denominaremos rB(n) al resto de las particiones sin bloques unitarios. Se calcula con rB(n) = pB(n-1, 1) particiones, siendo
rB(n) = pB(n-1, 1)
Donde pB(n, k) son las particiones con bloques parciales que vimos en el tema anterior, cuyo valor numérico se resuelve con esta recurrencia:
k>0 ⇒ pB(n, k) = sB(n, 0) - sB(n, k)
donde se hace uso de la recurrencia sB(n, k) que calcula las particiones con semi bloques:
n>0 ⇒ sB(n, k) = ∑j=1..n (1 - δj,k) C(n-1, j-1) sB(n-j, k)
En la siguiente tabla ponemos las diferencias entre B(n) y rB(n), observando, por ejemplo, que B(10) = 115975 mientras que rB(10) = 17722, que, tal como vimos más arriba, son la cantidad de rimas de un poema con dos quintetos de tal forma que ningún verso quede sin rimar:
| n | B(n) | rB(n) |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 1 | 0 |
| 2 | 2 | 1 |
| 3 | 5 | 1 |
| 4 | 15 | 4 |
| 5 | 52 | 11 |
| 6 | 203 | 41 |
| 7 | 877 | 162 |
| 8 | 4140 | 715 |
| 9 | 21147 | 3425 |
| 10 | 115975 | 17722 |
| 11 | 678570 | 98253 |
| 12 | 4213597 | 580317 |
Las rimas para el conjunto {A, B, C} vimos que son AAA, AAB, ABA, ABB, ABC. De ellas las rimas coincidentes es únicamente AAA, pues en las otras hay uno o más versos que no riman.
Para el conjunto {A, B, C, D} las rimas son 15: AAAA, AAAB, AABA, AABB, AABC, ABAA, ABAB, ABAC, ABBA, ABBB, ABBC, ABCA, ABCB, ABCC, ABCD. De ellas las rimas coincidentes son sólo 4: AAAA, AABB, ABAB, ABBA.
Para entender esto analizamos las particiones con bloques parciales pB(n, k) en la siguiente tabla para k=0, 1:
| n↓k→ | 0 | 1 |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 5 | 4 |
| 4 | 15 | 11 |
| 5 | 52 | 41 |
| 6 | 203 | 162 |
| 7 | 877 | 715 |
| 8 | 4140 | 3425 |
| 9 | 21147 | 17722 |
| 10 | 115975 | 98253 |
| 11 | 678570 | 580317 |
| 12 | 4213597 | 3633280 |
Siguiendo con el ejemplo n=10 vemos que B(10) = pB(10, 0) = 115975 que son todas las particiones del conjunto con 10 elementos. Mientras que contando las particiones con bloques unitarios tenemos pB(10, 1) = 98253. Por lo tanto la diferencia pB(10, 0) - pB(10, 1) = 115975 - 98253 = 17722 = pB(9, 1), con lo que el valor numérico de las rimas coincidentes obedece a la expresión rB(n) = pB(n-1, 1). El algoritmo para implementar esto es simple usando partialBell(n-1, 1):
// rB(n) = pB(n, 1)
function rhymeBell(n=0) {
if (n===0) {
return 0;
} else {
return partialBell(n-1, 1);
}
}Algoritmo para implementar rimas coincidentes
El algoritmo para generar las particiones con rimas coincidentes lo haremos usando el propio código del algoritmo partition4(list) que era el más eficiente que vimos para generar todas las particiones, que usaba los números de Stirling de segunda clase:
// B(n) = sum_(j=0)^(n) S2(n, j)
function matchingRhymes(list=[], n=list.length, res=[], result=[]){
if (n===0) {
//iter += 1;
let lines = [];
let ok = true;
/* res.length = bloques en una partición */
for (let i=0; i<res.length; i++) {
//iter += 1;
/* si el bloque es unitario salimos del bucle */
if (res[i].length===1) {
ok = false;
break;
}
let item = list[i];
/* res[i].length = elementos en un bloque */
for (let j=0; j<res[i].length; j++) {
//iter += 1;
let pos = res[i][j];
lines[pos] = item;
}
}
if (ok) result.push(lines);
} else {
//iter += 1;
let pivot = list.length-n;
for (let j=0; j<res.length; j++) {
//iter += 1;
res[j].push(pivot);
matchingRhymes(list, n-1, res, result);
res[j].pop();
}
res.push([pivot]);
matchingRhymes(list, n-1, res, result);
res.pop();
}
return result;
}Cuando llegamos al caso base realizamos el filtrado quitando aquellas particiones con bloques unitarios. Con el resto convertimos un partición como [[1, 2], [3]] en la rima AAB.
Para analizar el coste hacemos algo parecido a lo que vimos con el algoritmo partialPartition1(list, k) del tema anterior. Pues aquí, en el caso base donde realizamos el filtrado para obtener las rimas, también tenemos una sentencia break que dificulta obtener el coste exacto, por lo que provisionalmente vamos a ignorarlo.
El algoritmo anterior tiene la misma estructura que el usado en partition4(list) que nos permitía obtener las particiones usando la identidad B(n) = ∑j=0..n S2(n, j) que se basa en los números de Stirling de segunda clase con recurrencia S2(n, k) = k × S2(n-1, k) + S2(n-1, k-1). Sólo cambia la parte del filtrado en el caso base, por lo que el coste de partition4(list) que era así
también formará parte de nuestro coste de esta forma
siendo M(n) el coste de los dos bucles anidados en el caso base que filtran las rimas coincidentes, coste que es un promedio para una partición. Vea que si M(n) = 0 entonces T(n) = Tp(n) del algoritmo partition4(list). Por lo tanto con T(n) ≥ Tp como es de esperar pues estamos filtrando particiones que no tengan bloques unitarios.
Para calcular el coste promedio M(n) de una partición observamos que el bucle externo itera por lo bloques de una partición. Y ya vimos en partialPartition1(list, k) que en todas las particiones hay N(n) bloques en total:
En cuanto al bucle interno, vemos que itera por los elementos en cada bloque. Como en una partición hay n elementos aunque estén distribuidos en uno o más bloques, es obvio que en B(n) particiones habrán n × B(n) elementos a recorrer. Por lo tanto podemos decir que el coste promedio de los dos bucles para una partición M(n) es:
| M(n) = | n B(n) + N(n) | = | n B(n) + ∑j=0..n j S2(n, j) |
| B(n) | B(n) |
Sustituyendo en [1]
Si eliminamos la sentencia break del algoritmo, ejecutando en la aplicación obtenemos este comparativo de iteraciones y coste calculado con esta fórmula, observando que coinciden:
| n | Iter # Formula |
|---|---|
| 0 | 1 # 1 |
| 1 | 4 # 4 |
| 2 | 12 # 12 |
| 3 | 38 # 38 |
| 4 | 135 # 135 |
| 5 | 538 # 538 |
| 6 | 2373 # 2373 |
| 7 | 11434 # 11434 |
| 8 | 59562 # 59562 |
| 9 | 332740 # 332740 |
| 10 | 1980737 # 1980737 |
| 11 | 12498854 # 12498854 |
| 12 | 83242185 # 83242185 |
Sin embargo no es realista esto, pues break nos evita recorrer bucles innecesarios, por lo que debemos considerar una función desconocida 0 < f(n) < 1 que es una fracción en el rango (0, 1) que reduce el coste total:
Poniendo f(n) = 1, que equivale a no utilizar break, obtenemos estos valores en la aplicación:
| n | Iter # Formula |
|---|---|
| 0 | 1 # 1 |
| 1 | 3 # 4 |
| 2 | 9 # 12 |
| 3 | 27 # 38 |
| 4 | 93 # 135 |
| 5 | 360 # 538 |
| 6 | 1555 # 2373 |
| 7 | 7370 # 11434 |
| 8 | 37894 # 59562 |
| 9 | 209441 # 332740 |
| 10 | 1235650 # 1980737 |
| 11 | 7737883 # 12498854 |
| 12 | 51194573 # 83242185 |
Se observa que incluyendo break se reducen drásticamente las iteraciones. Intentemos aproximar más el coste, quitando en el algoritmo las sentencias iter += 1 inicial y las que están en la parte del else, obteniéndose las iteraciones sólo para los bucles de filtrado, que enfrentamos al coste T(n) = n B(n) + ∑j=0..n j S2(n, j) que hemos deducido para esos bucles, resultando:
| n | Iter # Formula |
|---|---|
| 0 | 0 # 0 |
| 1 | 1 # 2 |
| 2 | 4 # 7 |
| 3 | 14 # 25 |
| 4 | 55 # 97 |
| 5 | 233 # 411 |
| 6 | 1074 # 1892 |
| 7 | 5338 # 9402 |
| 8 | 28459 # 50127 |
| 9 | 161852 # 285151 |
| 10 | 977258 # 1722345 |
| 11 | 6238326 # 10999297 |
| 12 | 41946392 # 73994004 |
Dividiendo valores obtenemos estas fracciones para n=0..12:
5338/9402, 28459/50127, 161852/285151, 977258/1722345,
6238326/10999297, 41946392/73994004}
Esa secuencia de fracciones con aproximación a 6 digitos decimales son así, observando que es f(n) ≥ 0.5 para n>0, pues con n=0 el algoritmo no ejecuta los bucles de filtrado:
0.567752, 0.567738, 0.567601, 0.5674, 0.567157, 0.566889}
No he podido determinar ninguna expresión que devuelva esta secuencia de racionales, pero si vemos que el máximo es 4/7 = 0.571429, al menos para los valores n=1..12, así que podemos establecer esta cota superior al coste:
con un valor muy cercano al que devuelven las iteraciones:
| n | Iter # Formula |
|---|---|
| 0 | 1 # 1 |
| 1 | 3 # 3 |
| 2 | 9 # 9 |
| 3 | 27 # 27 |
| 4 | 93 # 93 |
| 5 | 360 # 362 |
| 6 | 1555 # 1562 |
| 7 | 7370 # 7405 |
| 8 | 37894 # 38079 |
| 9 | 209441 # 210532 |
| 10 | 1235650 # 1242589 |
| 11 | 7737883 # 7784870 |
| 12 | 51194573 # 51530469 |
El coste con copia es el mismo, pues no guardamos las iteraciones, sino que las convertimos en rimas cuyo coste es el que hemos estimado.