Web Tools online: XML DOM
Parseador XML y gestor DOM
En el tema anterior presentamos el Parseador XML. La herramienta permite parsear un documento con marcas SGML verificando su corrección. Con la opción de analizar nodos texto obteníamos al mismo tiempo un Array de nodos que representaba completamente el documento.
Una vez que tenemos todos los nodos del documento en un Array no es díficil dotar a los nodos de métodos para gestionarlos. El objetivo es lograr algo similar al DOM (Document Object Model) para documentos HTML y XHTML. Así tendríamos métodos como appendChild(), insertBefore() y otros que se comportan como las propiedades de sólo lectura childNodes o previousSibling por ejemplo.
La necesidad de tener un módulo DOM para gestionar los nodos se fundamenta en que algunos procesos necesitan realizar acciones sobre el array de nodos. Tal como comentamos en el tema anterior, el array de nodos obtenido es el que tenemos sobre el documento en desarrollo. Así podemos parsear el documento fuente y no el que llega al navegador. Por ejemplo, los nodos PHP no llegan al navegador y sólo existen antes de que PHP entre en juego en el servidor. Un proceso donde se hace un uso del gestor DOM es en el minimizador de documentos.
Veámos ahora un ejemplo en una página aparte usando copias locales de los módulos xml-parser.js y xml-dom.js. Intentaremos explicar como incorporamos esos módulos en una página, parseando un ejemplo para obtener el Array de nodos y finalmente usaremos un método DOM para modificar el documento. Los trozos de código de los siguientes apartados se encuentran en esa página de ejemplo.
Empecemos por cargar los módulos que podría ser algo como esto en el pie de una página HTML:
<script>
const MySpace = {};
window.addEventListener("load", () => {
//Inicia módulos XML Parser y XML DOM
MySpace.parser = MySpace.iniciarXmlParser();
MySpace.dom = MySpace.iniciarXmlDom();
});
</script>
<script src="xml-parser.js" async></script>
<script src="xml-dom.js" async></script>
En MySpace a modo de espacio de nombres guardaríamos las referencias al parseador en MySpace.parser y al objeto que contiene el gestor del DOM en MySpace.dom.
Verificando y obteniendo el array de nodos
Tras iniciar los módulos del Parseador y gestor DOM que vimos antes, a continuación podríamos tener una función para modificar el código como la siguiente, obteniendo el código inicial desde un elemento del documento como un <textarea id="codigo-inicial">:
MySpace.modificarCodigo = function(){
let mensajes = document.getElementById("mensajes");
let codigo = document.getElementById("codigo-inicial").value;
//Configuramos para que analice nodos texto y Array de Nodos
MySpace.parser.configurar({testTextNodes: true});
//Verificamos el código
let resultado = MySpace.parser.verificar(codigo);
//Devuelve {error, mensaje, xmlModif, xmlDemodif, nodos}
if (resultado.error){
//Si hay error, en mensaje obtenemos que sucedió
mensajes.innerHTML = resultado.mensaje.trim().
replace(/\n/g, '<br>');
} else {
//En otros caso obtenemos el Array de nodos obtenido
let nodos = resultado.nodos;
//A partir de aquí podríamos hacer algo con el array de nodos
//...........................
}
};
Para obtener el array de nodos es necesario modificar antes la configuración del parseador con parser.configurar({testTextNodes: true}). La opción de configuración testTextNodes establece si se analizan los nodos texto. Para verificar un documento no es necesario analizar esos nodos texto, pero para obtener el array de nodos si lo es. Por defecto se inicia el parseador con esa opción con valor falso.
A continuación pasamos a verificar el código con MySpace.parser.verificar (codigo). Esta función devuelve el objeto {error, mensaje, xmlModif, xmlDemodif, nodos}. Si hubo error en la verificación aparecería como una cadena de texto en la propiedad mensaje. Ese texto es realmente una lista de errores separados por salto de línea. Cada línea se inicia con un número entre corchetes seguido de una descripción del error. El número se refiere a la posición del caracter en el texto donde se detectó el error.
La propiedad xmlModif devuelve el XML modificado. Con el código <div>ABC</div> antes de verificar se modifica a <div><w_text_>ABC</w_text_></div>. Se trata de envolver los trozos de texto entre elementos en un nodo texto con el tag w_text_. Estos tags de escape se eligen previamente comprobando que no existen cadenas de texto iguales en el documento. Si ya existiera el texto "w_text_" se usaría w_1text_. El número entero se itera hasta conseguir una secuencia "w_Ntext_" que no exista inicialmente en el documento.
Hay otras modificaciones que puede consultar en la herramienta Web Tools online. A modo de ejemplo resaltamos la que tiene que ver con elementos vacíos como <br>, que también podríamos escribir como <br/> e incluso <br />. En el XML modificado a todos los elementos vacíos se les quita el autocierre y se agrega el tag de cierre </br> de la siguiente forma:
CÓDIGO MODIFICADO
----------------------------------
<br /> <br w_empty_="0"></br>
<br/> <br w_empty_="1"></br>
<br> <br w_empty_="2"></br>
Agregamos temporalmente el atributo w_empty_="N" donde "N" puede ser números cero, uno o dos según el tipo de tag de autocierre. Con estas modificaciones logramos que todos los elementos tengan un tag de apertura y otro tag de cierre, con lo que la verificación resulta más sencilla de llevar a cabo.
Al finalizar la verificación sin error se realiza una demodificación de xmlModif dehaciendo esas modificaciones temporales y recuperándose el código original en xmlDemodif. Si ese XML demodificado no coincidiera con el original nos daría el correspondiente error. Con eso aseguramos que la modificación del código previa a la verificación no introduce modificaciones indeseadas.
Y por último el resultado de la verificación también devuelve el Array de Nodos. Para un código simple como <div>ABC</div> obtendríamos este array:
[
0: {
tag: `div`,
tagStart: `<div`,
tagEnd: `</div>`,
text: ``,
attr: {},
attrText: `>`,
level: 0,
parent: -1
},
1: {
tag: `w_text_`,
tagStart: ``,
tagEnd: ``,
text: `ABC`,
attr: {},
attrText: ``,
level: 1,
parent: 0
},
php: []
]
Es la representación del XML modificado que vimos antes y que contiene un DIV con un nodo texto en su interior: <div><w_text_>ABC</w_text_></div>. Cada nodo es un objeto con unas propiedades. Con tagStart, tagEnd y attrText podemos reconstruir el XML en cualquier momento. Se estructura el árbol de nodos pues cada nodo apunta a un padre con parent. Un padre "-1" significa que está en el nodo raíz. El nivel de profundidad de un nodo en el árbol se almacena en level. La propiedad php será un array para almacenar el contenido de los nodos PHP.
El objeto attr almacena los atributos del elemento, parseando la cadena attrText. Si el elemento fuera <div id="xyz">ABC</div> obtendríamos attrText: ` id="xyz">` y attr: {id: `xyz`}. Ese objeto de atributos nos permite acceder rápidamente a ellos. Por último la propiedad text sólo se usa en los nodos texto conteniendo el texto final.
Agregando métodos XML DOM a los nodos del Array de Nodos
Hasta lo visto en el apartado anterior sólo hemos hecho uso del módulo Parseador XML (xml-parser.js). Es suficiente para verificar un documento y, si se activa el análisis de nodos texto, obtener el array de nodos. Ahora si además necesitamos gestionar esos nodos podemos usar el segundo módulo XML DOM (xml-dom.js):
//Partimos de un Array de nodos obtenido al verificar un XML
//(ver código anterior)
let nodos = resultado.nodos;
//Agregamos métodos al prototipo de los nodos
MySpace.dom.agregarPrototipo(nodos);
//A partir de aquí podemos usar métodos DOM
//..............................
Con MySpace.dom.agregarPrototipo(nodos) modificamos el array de nodos. Para el ejemplo visto antes <div>ABC</div> el array de nodos quedaría como sigue:
[
0: { //Lo mismo + index, nodos y métodos DOM
tag: `div`,
tagStart: `<div`,
tagEnd: `</div>`,
text: ``,
attr: {},
attrText: `>`,
level: 0,
parent: -1,
index: 0,
nodos: [...] //autoreferencia al propio array
__proto__: {appendChild(), childNodes(), ...} //métodos DOM
},
1: {...}, //Lo mismo + index, nodos y métodos DOM
"-1": { //Nuevo nodo document
tag: `document`,
tagStart: `<document`,
tagEnd: `</document>`,
text: ``,
attr: {},
attrText: `>`,
level: -1,
parent: null,
index: -1,
nodos: [...] //autoreferencia al propio array
__proto__: {appendChild(), childNodes(), ...} //métodos DOM
},
document: {...}, //apunta a nodos["-1"]
php: [], //nodos PHP
]
Por un lado agregamos al array de nodos un nuevo nodo con índice "-1". Es el nodo raíz con tag document. También agregamos una referencia a ese nodo de tal forma que con nodos["-1"] y nodos.document podremos acceder indistintamente al nodo raíz.
Por otro lado a cada nodo se le agrega la propiedad index que es el índice en el array de nodos. También se incluye nodos que es una auto-referencia al propio array de nodos. Estas dos referencias son de ayuda para el código de los métodos DOM. Estos métodos se agregan al prototipo de cada nodo con Object.setPrototypeOf(nodo, protoNodo). El protoNodo es el objeto que contiene los métodos DOM:
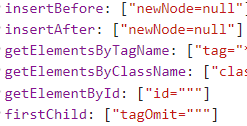
- appendChild(newNode=null)
- childNodes()
- convert(newNode=null)
- firstChild(tagOmit="")
- getElementById(id="")
- getElementsByClassName(className="")
- getElementsByTagName(tag="*")
- insertAfter(newNode=null)
- insertBefore(newNode=null)
- isFirstChild(tagOmit="")
- isLastChild(tagOmit="")
- lastChild(tagOmit="")
- nextSibling(tagOmit="")
- parentNode()
- previousSibling(tagOmit="")
- remove()
- removeChild(child=null)
- treeNodes(copy=true)
Estos son los métodos que actualmente existen, aunque es posible que agregue nuevos métodos. En todo caso en la herramienta Web Tools Online siempre encontrará los métodos actualizados. En la mayoría de los casos son métodos con nombres iguales que los usados en el DOM HTML. Su comportamiento también es similar. Como son métodos se aplicaran a un objeto nodo, por ejemplo nodo.childNodes(), donde nodo es un elemento del array de nodos.
Usando el gestor XML DOM
Algunos métodos devuelven un objeto nodo como nodo.firstChild(). Otros un array de nodos como nodo.childNodes(). Algunos un booleano como nodo.isFirstChild(). Los nodos que insertan nuevos nodos devuelven el nodo insertado. Si hay un error en el método devolverá null.
Un argumento tagOmit nos permitirá excluir un tipo de tag. Por ejemplo, nodo.nextSibling("w_text_") nos permite extraer un elemento hermano excluyendo nodos texto. El argumento child es una referencia a un nodo que debe ser hijo de otro, por ejemplo, nodo.removeChild(nodo.firstChild()) eliminará el primer hijo del nodo.
Veámos ahora la última parte del ejemplo donde usaremos los métodos getElementById(), insertBefore() y appendChild para buscar un elemento con ID="xyz" y crear e insertar antes un nuevo nodo STRONG:
//Buscamos el elemento con id="xyz"
let nodoXyz = nodos.document.getElementById("xyz");
if (nodoXyz){
//Creamos un nuevo nodo STRONG
let strong = MySpace.dom.crearNodo("strong", `id="pqr"`);
if (nodoXyz.insertBefore(strong)) {
//Y luego le agregamos un texto en su interior
let texto = MySpace.dom.crearNodo("w_text_", "456");
if (strong.appendChild(texto)){
//Por último reconstruimos el documento
let res = MySpace.parser.reconstruirXml(nodos);
let codigoFinal = document.getElementById("codigo-final");
if (res.error){
codigoFinal.value = res.mensaje;
} else {
//y lo metemos en el textarea
codigoFinal.value = res.xml;
}
}
}
} else {
mensajes.textContent = `No se encontró el elemento con ID="xyz"`;
}
La función MySpace.dom.crearNodo(tag, attrText) devolverá un nuevo nodo con ese Tag y con ese contenido de texto si el Tag es el de nodo texto ("w_text_"). En otro caso attrText se considera una cadena de texto con atributos tal como aparecería en el tag de apertura en el documento.
En cualquier momento podemos reconstruir el documento con las modificaciones usando MySpace.parser.reconstruirXml(nodos). Devolverá un objeto {error, mensaje, xml}. Si no se produce error tendremos en res.xml el nuevo código.