Web Tools online: Parseador XML
Parseador XML con JavaScript
El Parseador XML permite verificar la sintaxis de documentos HTML, XML y XHTML. En el año 2010 llevé a cabo un parseador XML con PHP integrado en un marco de herramientas para usar en localhost. Lo he venido usando para verificar la corrección de los documentos HTML durante el desarrollo de este sitio, además de otras ventajas como facilitar el minimizado para lo cual es imprescindible parsear el documento.
Desde hace un tiempo estoy migrando esas herramientas PHP al nuevo marco Web Tools online basado en JavaScript. Y este es el momento de migrar el parseador XML y de paso mejorarlo en muchos aspectos.
Los documentos se parsean y se verifican. Al menos en lo que se refiere a la corrección de los tags y atributos. Por ejemplo, el código <div><span></div></span> está incorrectamente anidado, error que esta herramienta detecta. Pero no revisa si la estructura del documento es conforme a las especificaciones. Por ejemplo, HTML no admite que un elemento DIV sea hijo de un SPAN como en el código <span><div></div></span>. O que un documento no tenga un primer elemento <!DOCTYPE html> para detectar HTML5. O que un XHTML debe empezar con algo como <?xml version="1.0" encoding="UTF-8" ?>.
Para esas verificaciones hay que usar algo más complejo, como W3C Validation Service. Pero en esos verificadores no podemos revisar nodos PHP dentro del HTML, lo que es muy importante porque yo uso HTML+PHP para el desarrollo de este sitio. La herramienta nos permite parsear y verificar un código como el siguiente:
<div class="<?php echo $prop; ?>">
abc <?php echo $text."abc"; ?> def
</div>
Podríamos usar el parseador del navegador para descubrir los errores, pero ese es el código cuando llega al navegador y no el que existe antes de que PHP lo modifique. Por lo tanto es importante revisar los documentos en el estado de desarrollo. Los entornos de desarrollo nos facilitan esas tareas. Pero hubo un momento en que me decidí a montar mi propio entorno de desarrollo. Y el parseador es una pieza básica de ese marco de trabajo.
FileReader. Sin embargo a partir de esta nueva pieza de herramienta usaré muchas cosas de lo nuevo de ES6 y siguientes en los módulos de JavaScript. Incluso declarándolos en modo estricto. Es por eso que estas nuevas piezas no funcionarán en navegadores que no soporten todo lo de ES6.Detalles de funcionamiento
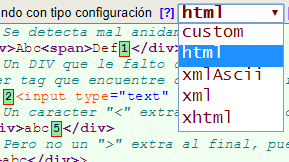
Esta herramienta nos permite verificar varios tipos de documentos, tal como se observa en la Figura del apartado anterior. Se presentan los tipos html, xml y xhtml. El tipo xmlAscii es una versión reducida de xml para un patrón de nombres de tags y atributos limitado a caracteres ASCII. He tratado de que esos tipos respondan a las especificaciones HTML 5, XML 1.0 y XHTML 1.0. El tipo custom se destina a configuraciones personalizadas. Todas los tipos de configuración pueden modificarse, crear nuevos tipos y, a excepción de custom, eliminarse.
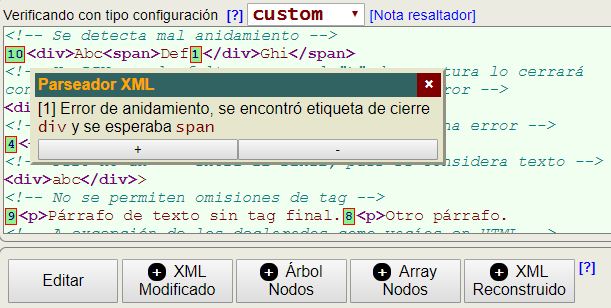
La herramienta verifica un documento interponiendo marcas de error en los puntos donde se producen. Como se observa en la Figura, aparecen insertados recuadros de color que al pulsarlos nos presenta un mensaje emergente con la descripción del error. También es posible descargar un archivo con muestras de ejemplo para observar el comportamiento con distintos tipos de error. El código que aparece en esa imagen es de la muestra de errores de anidamiento.
La verificación se basa en comprobar que los tags están correctamente ubicados y sus nombres responden a lo especificado. Se revisa que los elementos están bien anidados. Se comprueban los nombres de los atributos y el correcto entrecomillado de sus valores. O bien la ausencia de comillas para aquellos valores de atributos donde pueda omitirse. Se verifican los elementos definidos como vacíos o sin contenido. Se identifican los elementos raw text como <style> o <script> y los escapable raw text como <textarea> y <title>. Se verifican las referencias a caracteres y el contenido de los comentarios. En resumen, creo que todo lo que se necesita para verificar la corrección del documento.
Como habíamos dicho en el primer apartado, lo que no hace esta herramienta es comprobar si la estructura del documento es acorde con la especificación o, para los XML, con su DTD. Por ejemplo, no se comprueban los nombres de los tags con los elementos permitidos, así que algo como <NoSoyEstandar> pasaría como correcto en el tipo HTML aunque ese elemento no existe en la especificación HTML. O que la especificación dice que para ciertos elementos como <p> podemos omitir el tag de cierre, algo que esta herramienta no contempla. O que no podemos anidar un <div> dentro de un <span>. Para detectar cosas como esas habría que dotar a la herramienta de un gran cantidad de información proveniente de las especificaciones, algo que la haría mucho más lenta y compleja.
Utilidades adicionales
Pero además de la verificación se ofrecen utilidades adicionales como se observa en los botones de la Figura del apartado anterior: XML Modificado, Árbol Nodos, Array Nodos y XML Reconstruido.

Una utilidad es que mientras parsea el documento para buscar errores puede construir un array de nodos. Ese array lo volcamos en un árbol de nodos, estructura a modo de DOM que nos pemitirá navegar por ella para visualizar el documento. En la Figura puede ver el árbol de nodos de la página principal de este sitio, con los nodos <head> y <body> plegados. Pulsando sobre esos nodos se irán desplegando por ramas hasta llegar a un último nodo texto en cada rama.
Volviendo al array de nodos hay que decir que representa exactamente el documento, donde cada posición del array es un nodo. Hablamos de nodos en lugar de elementos porque además incluye los trozos de texto. Podemos reconstruir el documento original a partir de ese array. El último botón XML reconstruido ejecuta precisamente eso: recupera el documento original a partir del array de nodos, verificando que ambos son iguales.
Y esa capacidad de recuperación es muy importante porque podríamos conseguir una utilidad derivada. Podríamos añadir, eliminar y modificar nodos en ese array y volver a recuperar el documento modificado. Supongamos por ejemplo que tengo una cantidad grande de documentos HTML donde quiero agregar un atributo a un elemento conocido que aparece en todos ellos, como el primer <h1> que contiene el título. Verificaríamos todos los documentos construyendo el array de nodos de cada uno, insertaríamos un atributo en el nodo del array que fuera un primer <h1> y recuperaríamos el documento resultante. Esa utilidad derivada no se contempla en esta herramienta, pero si que ya la tengo implementada en la herramienta PHP desde la que estoy migrando sus piezas. Y es posible que el futuro lo implemente en Web tools online.
Veámos ahora un breve ejemplo para ver cómo es el array de nodos. Supongamos que partimos del siguiente código HTML:
<div><span id="abc">123</span></div>
La herramienta realiza unas transformaciones previas obteniendo un XML modificado. Se trata de modificar el XML para que el parseado y verificación resulten más simples. Una de las transformaciones es envolver los textos finales en un nodo texto que aparece con el tag w_text_:
<div><span id="abc"><w_text_>123</w_text_></span></div>
Ese tag w_text_ se agrega a una copia del XML original, el cual no se modifica, tras lo cual parseamos y verificamos la copia en el XML modificado. De ahí también obtenemos el array de nodos, array que podemos extraer como texto con el botón "Descargar" que se dispone en la herramienta:
[
0: {
tag: `div`,
tagStart: `<div`,
tagEnd: `</div>`,
text: ``,
attr: {
},
attrText: `>`,
level: 0,
parent: -1
},
1: {
tag: `span`,
tagStart: `<span`,
tagEnd: `</span>`,
text: ``,
attr: {
id: `abc`
},
attrText: ` id="abc">`,
level: 1,
parent: 0
},
2: {
tag: `w_text_`,
tagStart: ``,
tagEnd: ``,
text: `123`,
attr: {
},
attrText: ``,
level: 2,
parent: 1
}
]
Los nodos se agregan al array en el orden en que se van encontrando. El nivel (level) nos indica la profundidad a la que se encuentra. El padre (parent) nos dice en que nodo está contenido. Un padre -1 indicará que está en el raíz. Los atributos se almacenan en un objeto con el nombre de atributo y el valor como entradas en ese objeto. Con toda esa información podemos reconstruir exactamente el código original.