Web Tools online: Vínculos
Revisar los vínculos o enlaces web

Los vínculos o enlaces son elementos clave en una página web. Hay que asegurarse que funcionan correctamente cuando publicamos una página e incluso en momentos posteriores, pues en algún caso el destino del vínculo pudiera modificarse o eliminarse. Esta herramienta se dedica a comprobar la corrección de los vínculos al propio sitio. No revisa vínculos externos a otros sitios.
En síntesis se trata de usar el parseador XML para construir el Array de Nodos del documento a chequear, rastreando atributos de elementos que puedan contener un vínculo, como href, src o action entre otros. Revisa también los vínculos internos a un documento, es decir, los que apuntan con "#" a un elemento identificado con el atributo id o name. En CSS también se chequean los vínculos contenidos en los valores url(...).
Recordemos que podemos expresar dos tipos de vínculos en el propio sitio: con rutas absolutas y con rutas relativas. Cuando iniciamos un sitio hay que decidirse por una de las dos formas y mantenerlas en todo el sitio con el objetivo de ser coherentes. Una ruta absoluta sería como la siguiente, suponiendo que nuestro sitio es
<a href="http:⁄⁄example.com⁄folder⁄index.html">INDEX</a>
La relativa sería la siguiente:
<a href="⁄folder⁄index.html">INDEX</a>
Cuando estamos en una página web de ese sitio http:⁄⁄example.com, el navegador ya habrá reconocido previamente el dominio de esa página. Cuando encuentra una ruta relativa en un vínculo procede de la siguiente forma:
- Si empieza con una barra como
⁄folder⁄index.htmlentiende que es referenciada a la carpeta de inicio, por lo que anteponehttp:⁄⁄example.coma esa ruta quedandohttp:⁄⁄example.com⁄folder⁄index.html, ruta que enviará en la petición al servidor. - Si empieza como
subfolder⁄entiende que es referenciada a la carpeta actual de la página donde está contenido ese vínculo. Si por ejemplo estamos en la página⁄folder⁄index.htmlque contiene el vínculosubfolder/sample.html, antepone la carpeta de la página actual para formar el vínculo finalhttp:⁄⁄example.com⁄folder⁄subfolder⁄sample.html.
La principal ventaja de usar rutas relativas es que si en un momento posterior queremos cambiar el dominio del sitio lo podemos hacer sin tener que estar modificando todos los vínculos. De hecho esto me sucedió cuando tuve que actualizar de HTTP a HTTPS, no suponiendo mas esfuerzo que modificar sólo los vínculos de algunos elementos especiales que requieren la ruta absoluta, como el siguiente:
<link rel="canonical" href="https:⁄⁄www.wextensible.com⁄herramientas⁄web-tools-online⁄vinculos.html" />
Ese vínculo se agrega en todas las páginas e informa a los buscadores de la ruta canónica que preferimos que se use para indexar cada página. En la herramienta que comprueba vínculos podemos chequear que se cumple la ruta canónica, de tal forma que si establecemos que debe ser https:⁄⁄example.com resultarán erróneas si encuentra algo diferente como https:⁄⁄www.example.com, http:⁄⁄www.example.com o http:⁄⁄example.com.
Hay que tener en cuenta que el navegador enviará la ruta al servidor quien se encarga de resolverla dentro del sitio. Cabe la posibilidad de configurar el servidor para definir los páginas índice denominándolas generalmente como index.html. Así que una petición como <a href="⁄folder⁄">INDEX</a> cuando llega al servidor le agregará index.html recuperando ⁄folder⁄index.html. En la herramienta podemos configurar que revise archivos index, de tal forma que una ruta que termine en ⁄index.html será advertida de que debe finalizar en barra. Esto puede ser una facilidad si tenemos varios tipos de archivos index configurados en el servidor, como index.html e index.php. Así una ruta como ⁄folder⁄ nos llevará a la página índice que se encuentre en esa carpeta sin tener que saber exactamente como se denomina. En la herramienta podemos configurar este aspecto.
Los servidores pueden permitir que las rutas pueden ser combinadas con uno o dos puntos. Así algo como ..⁄ retrocederá una carpeta. Particularmente prefiero evitar las rutas que retroceden y me planteo que si una ruta es previa a la página actual la referencio desde la carpeta de inicio y si es posterior la referencio con respecto a la carpeta actual. Supongamos que tenemos esta estructura de carpetas y páginas:
[http:⁄⁄example.com]
index.html
[folder]
index.html
[subfolder1]
index.html
[subfolder2]
index.html
Si estamos en ⁄folder⁄index.html y queremos vincular con una ruta en la primera subcarpeta pondremos subfolder1⁄index.html. Si estamos en ⁄folder⁄subfolder1⁄index.html y queremos ir a ⁄folder⁄subfolder2⁄index.html podríamos usar los "..⁄" que retroceden ..⁄subfolder2⁄index.html, pues con ".." retrocedemos una carpeta y luego formamos la ruta desde ahí. Como dije antes, yo prefiero no usar rutas que retroceden pues una cadena de secuencias ".." no nos dice nada acerca de adónde apunta y es díficil de escribir. Sin embargo si que utilizo la referencia a la propia carpeta usando un sólo punto ".⁄" como veremos más abajo.
Una ruta relativa también podría estar vacía. En general es preferible evitar un valor vacío, pues pudiera estar vacío por omisión y no lo detectaríamos. Con algo como <a href="">abc</a> donde el vínculo es una ruta vacía, esa URL apuntará al propio documento. Un vínculo al propio documento no es de mucha utilidad a no ser que sea a un vínculo interno, en cuyo caso pondríamos algo como <a href="#xyz">abc</a>. Si quisiéramos apuntar a la misma página con el objetivo de recargarla podríamos poner <a href="doc.html">abc</a>, siendo "doc.html" el nombre de esa página.
Si lo que pretendemos es vincular con el archivo index en la misma carpeta y el propósito es no especificar los "index", deberíamos usar <a href=".⁄">abc</a>. Y si el objetivo fuese vincular con el index del sitio usaríamos <a href="⁄">abc</a>.
En estos vínculos reales puede ver como enlazan. Pasando el cursor sobre el enlace se puede observar la URL en la barra de estado que los navegadores suelen tener en el margen inferior y así no necesitará actuar sobre el enlace.
- href="/" enlaza con la página de inicio del sitio https://www.wextensible.com
- href="" enlaza con la página actual https://www.wextensible.com/herramientas/web-tools-online/vinculos.html
- href="vinculos.html" enlaza con la página actual https://www.wextensible.com/herramientas/web-tools-online/vinculos.html
- href="sitemap.html" enlaza con otra página en la misma carpeta que la de la página actual https://www.wextensible.com/herramientas/web-tools-online/sitemap.html
- href="./sitemap.html" usando "./" desde una carpeta referenciará a la misma carpeta, en este caso la carpeta actual /herramientas/web-tools-online/ y luego a otra página en esa carpeta sitemap.html
- href="././././sitemap.html" como referencia la misma carpeta se puede repetir "./" oteniéndose la misma referencia a esa página sitemap.html como en el caso anterior. Parece que "./" no es muy útil, a excepción del uso en el siguiente caso.
- href="./" enlaza con la página índice de la carpeta donde está ubicada la página actual https://www.wextensible.com/herramientas/web-tools-online/index.html. Equivale a href="index.html", pero así evitamos escribir archivos index.
- href="../resaltador/" retrocede una carpeta desde la de la página actual y va al index de otra https://www.wextensible.com/herramientas/resaltador/index.html
Aunque active "..⁄" no tendrá efecto en la carpeta raíz. Así https:⁄⁄example.com⁄..⁄privado⁄modulo.php será solicitado por el navegador como https:⁄⁄example.com⁄privado⁄modulo.php, eliminando las retrocesiones. Si no existe tal documento en la carpeta pública el servidor devolverá un error de no encontrado.
Cargando un Sistema de Archivos Locales
El chequeo de vínculos se limita a los vínculos del sitio comprobando que existe el documento en el Sistema de Archivos Locales. Si no se cargan el total de archivos locales que pudieran ser destino de los vínculos nos dará error de que no encontró el archivo. Recordemos como cargar ese conjunto de archivos en la pestaña de configuración del marco principal. Si tenemos nuestro documentos de desarrollo en una carpeta del ordenador que se llame "devweb" podemos seleccionar o arrastrar esa carpeta hasta el botón de elegir archivos:
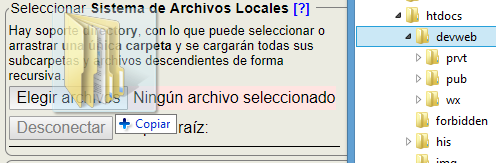
Una vez cargados los archivos aparecerán el número de documentos y la carpeta raíz enlazada junto a un botón para tener la posibilidad de desconectar ese sistema de archivos.
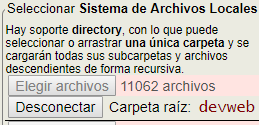
Realmente no se cargan los archivos sino un conjunto de punteros a los archivos, así que la desconexión lo que hace es vaciar ese conjunto. El hecho de que no se cargue el contenido del archivo nos permite modificar ese contenido y el puntero al archivo seguirá siendo válido. Esto es muy útil cuando estamos pasando test a un archivo, arreglando lo que hay incorrecto y chequeando de nuevo, todo ello sin tener que volver a cargar el Sistema de Archivos. Por supuesto que el puntero ya no será válido si eliminamos, movemos o renombramos el archivo.
No olvide que esta herramienta puede acceder a los archivos que seleccione, pero en ningún caso puede crear, modificar o eliminar carpetas y/o archivos en su ordenador. Esto es una limitación de los navegadores para evitar un uso indebido. El marco de herramientas contempla sólo la posibilidad de realizar una falsa descarga en la carpeta de descargas del navegador. Desde ahí usted puede, si lo desea, trasladar manualmente ese archivo a donde proceda.
Recuerde que al cargar un Sistema de Archivos Locales buscará una archivo wt.txt con la configuración del marco de herramientas. El primer archivo con la configuración que encuentre hará que el marco entre en modo local, así que podemos salvar las configuraciones para una ejecución en otro momento.
Iniciando herramienta chequeadora de vinculos
El siguiente paso después de cargar el Sistema de Archivos Locales es volver a la herramienta chequeadora de vínculos y seleccionar la carpeta raíz cuyos documentos vamos a chequear:

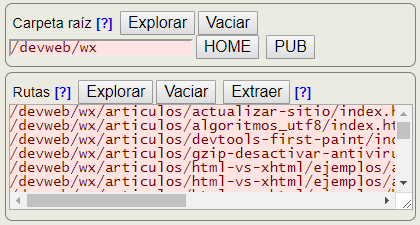
La carpeta raíz es tal que si tenemos un vínculo href="⁄articulos⁄actualizar-sitio⁄index.html" hemos de localizar ese documento en la ruta ⁄devweb⁄wx⁄articulos⁄actualizar-sitio⁄index.html.
En mi caso la carpeta raíz equivale a la de desarrollo y es ⁄devweb⁄wx, aunque por supuesto puede usar otras estructuras y nombres. También hay otra carpeta ⁄devweb⁄pub⁄wx que contiene los mismos documentos pero preparados para subir al sitio. Son documentos ya minimizados y refactorizados para que ocupen un tamaño menor, aparte de otros añadidos que se incorporan al publicar. Por lo tanto hemos de chequear ambos sitios en desarrollo, acciones que no pueden ejecutarse en un mismo proceso. Para facilitar el cambio entre ambas carpetas se acompañan los botones "HOME" y "PUB" que extraen las sendas carpetas desde la pestaña de configuración del marco principal:
Tras seleccionar la carpeta raíz podemos extraer todas las rutas para chequear:
Chequeando vínculos de un archivo
La herramienta permite chequear los vínculos de un único archivo o de un lote de archivos. Veámos ahora el caso de un único archivo. He modificado a propósito el documento ⁄devweb⁄wx⁄index.html con el vínculo que apuntaba a ⁄temas⁄ por ⁄Temas⁄. Algunos servidores no diferencian mayúsculas de minúsculas, pero en esta herramienta si se diferencian. Chequeamos el documento y obtenemos lo siguiente, el documento resaltado y una tabla con los resultados de todos los vínculos de ese documento:
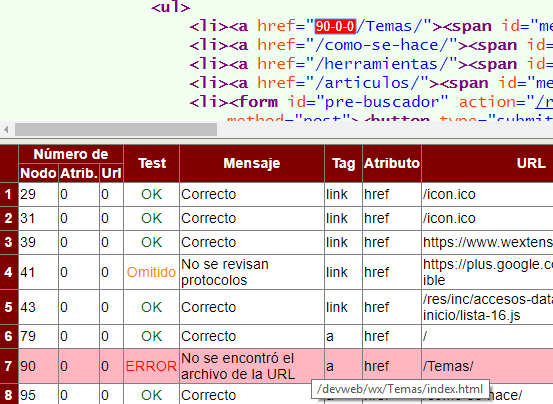
Se observa que localizó ese error pues no existe un documento en el Sistema de Archivos Locales en la ruta ⁄devweb⁄wx⁄Temas⁄index.html. Al pulsar sobre una fila nos localiza la URL en el documento agregando la marca "90-0-0". Además al situar el cursor sobre la fila se presenta la ruta que se está intentando buscar en el Sistema de Archivos Locales.
Las tres primeras columnas de la tabla sirven para marcar la posición de la URL en el documento. Se compone de número de nodo, número de atributo y número de URL. El número de nodo es el devuelto por el parseador incluyendo los nodos texto. En cuanto a los otros dos números serán distintos de cero si un elemento tiene más de un atributo que porte una URL y si un atributo tiene más de una URL. Vea como en este documento el elemento IMG (nodo 33) tiene los atributos SRC y SRCSET, donde el segundo tiene a su vez seis URL.
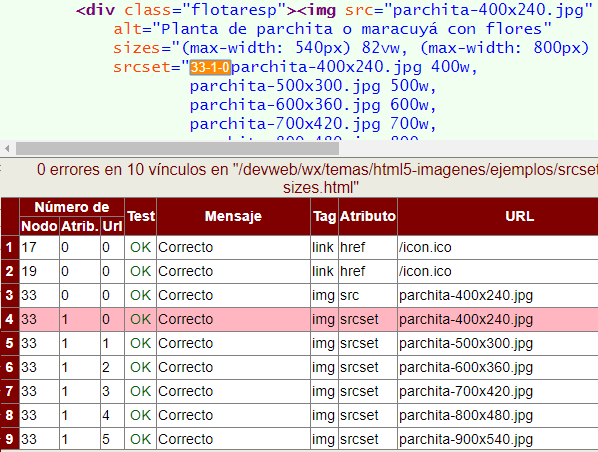
Los mensajes que podemos obtener tras el chequeo pueden ser alguno de los que se se observan en la imagen siguiente:
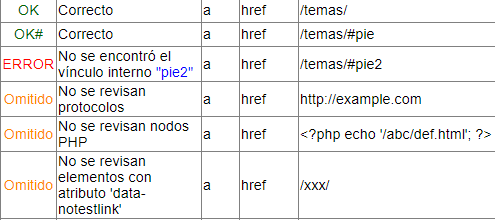
Los mensajes de corrección a vínculos internos al documento tienen al final el signo "#". Se omite chequeado para rutas con protocolos como explicamos antes. Tampoco se revisan URL que contengan nodos PHP y elementos que porten un atributo data-notestlink.
Los atributos sobre los que chequear vínculos se configuran en la herramienta. Por defecto se establecen los siguientes:
- action, atributo del elemento
<form> - data, atributo del elemento
<object> - href, atributo de varios elementos como
<a>o<link> - src, atributo de varios elementos como
<img>o<script> - srcset, atributo del elemento
<img> - style, atributo de cualquier elemento, se chequea el valor
url(...)
En el CSS también podemos encontrar vínculos. Por ejemplo dentro del atributo style de un elemento. En la siguiente imagen se observa que el nodo 1276 contiene 3 URL en el atributo style:
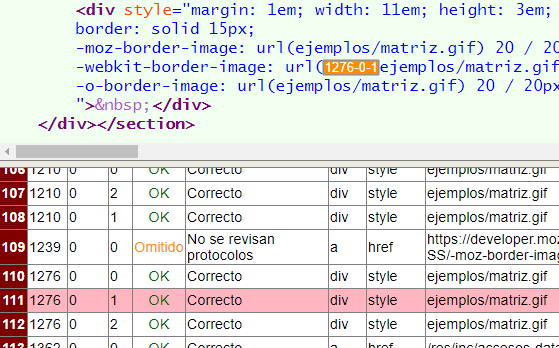
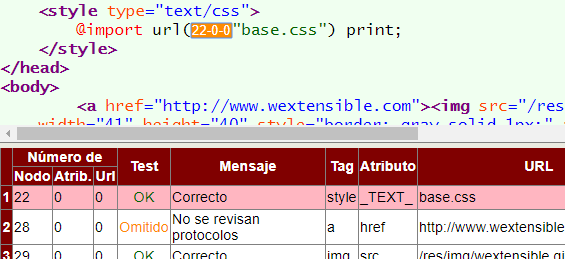
Todos los vínculos en CSS siempre los vamos a encontrar dentro de los paréntesis de la expresión "url(...)". El CSS puede estar en el atributo style, en un elemento <style> o en un archivo CSS. En el siguiente ejemplo verá que se chequea una URL en un elemento <style>, formando parte de una regla @import. En estos casos en la columna atributo se indica "_TEXT_" para aclarar que el chequeo se realiza sobre el texto del elemento <style> o del archivo CSS.
Chequeando vínculos de varios archivos
La otra posibilidad de la herramienta es chequear un conjunto de archivos. En la siguiente imagen observará que se incluyeron cuatro rutas para el chequeado, con error en una de ellas.
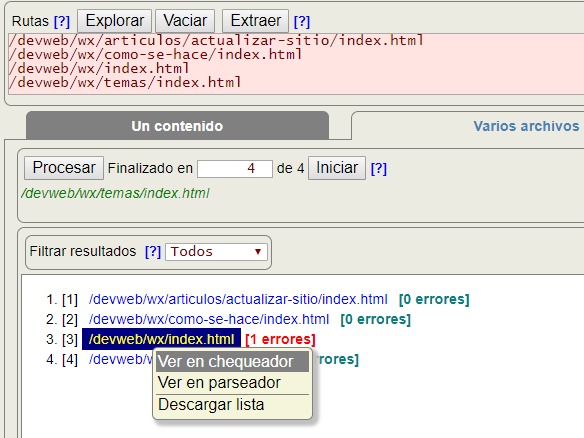
El menú contextual nos permite abrir esa ruta seleccionada en el chequeador para ver el detalle del error o errores descubiertos. También puede abrir el documento en el parseador XML para descubrir el detalle del error de parseado si fuera el caso.