Aplicación para descargar ZIP
Usando ZIP para descargar múltiples archivos
El formato de archivo ZIP tiene por objetivo empaquetar varios archivos en un único archivo con objeto de facilitar su almacenamiento y transmisión, especialmente por Internet. Ese empaquetado puede hacerse con compresión sin pérdida y también con cifrado.
El formato ZIP fue creado por Phil Katz (PKWARE), quién liberó la documentación técnica en 1989 pasando a ser una tecnología de dominio público. La especificación técnica APPNOTE ZIP, versión 6.3.9 de julio 2020, expone lo necesario para implementar una aplicación para crear y/o leer un formato ZIP. Expone esa especificación que se permite el uso de la información contenida en ese documento para el propósito de crear programas y procesos que lean o escriban archivos en el formato ZIP. Hay algunas opciones que no pueden usarse sin obtener una licencia, como el cifrado fuerte (7.0 Strong Encryption Specification
) y el parcheado (4.5.8 -PATCH Descriptor Extra Field
). Algunos métodos de compresión y otras tecnologías pueden tener restricciones de uso. En estos temas y en las aplicaciones que desarrollo a partir de esa especificación se relacionan sólo con un propósito informativo.
En este tema veremos como preparar los archivos para empaquetarlos en un ZIP con el módulo zip.js. Haremos un ejemplo interactivo básico para verlo en funcionamiento. En el tema siguiente explicaremos los fundamentos básicos para crear un ZIP. Para ello nos basaremos en la especificación técnica a la que nos referimos en el párrafo anterior. Y también en la herramienta ZIP que nos permite trazar la creación de un ZIP. En el tema Gestor ZIP se explica el funcionamiento de esa herramienta.
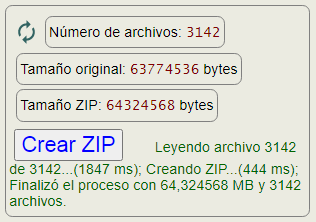
En la Figura vemos una captura de una ejecución con una descarga de un ZIP con 3142 archivos y 63,77 MB. El límite máximo en esa aplicación es de 2,14 GB, aunque el formato ZIP permite hasta el doble de ese tamaño. Para tamaños inferiores a 100 MB los tiempos de ejecución no son muy grandes. Por ejemplo, la descarga de la Figura ocupó 1,847 segundos leyendo los archivos y 0,444 segundos creando el ZIP (en Chrome 89). Si se incrementa mucho el tamaño, la ejecución en la creación del ZIP se incrementa más que proporcionalmente. En una ejecución de prueba de un único archivo de 1,15 GB tarda 6,4 leyendo y 26,16 segundos creando el ZIP.
En cualquier caso mi objetivo inicial no es usarlo para descargas de gran volumen. Ni siquiera en principio que sirva como un gestor universal de ZIP, puesto que crear un ZIP con compresión y otras opciones es algo mucho más complejo. En el módulo zip.js sólo se contempla el empaquetado o almacenamiento de archivos, algo que va a cubrir mi necesidad inicial de descargar múltiples archivos de distintas extensiones en la herramienta Web Tools online. Y siempre con el objetivo de un tamaño de descarga muy inferior al señalado antes.
Necesidad de las descargas en ZIP
Para mi caso el motivo principal de tener la posibilidad de descargar archivos en ZIP se fundamenta en el uso de herramientas web. Estas cargan archivos en el navegador para su edición y posterior descarga para sustituirlos en el ordenador, donde tenemos ubicados los recursos fuente.
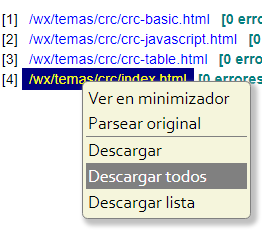
Por ejemplo, minimizar documentos HTML, CSS, JS o PHP. Los cuatro archivos que se exponen en la Figura ocupan 232 KB. Una tarea que suelo hacer antes de subir documentos HTML a la web es minimizarlos con la herramienta Minimizador. Al finalizar el proceso me permite descargar en un único paso todos los documentos que haya procesado.

Sin utilizar ZIP la descarga se realiza en archivos individuales. Si el navegador detecta una descarga múltiple puede emitir un aviso de advertencia, como se observa en la Figura. Además los nombres de archivos no pueden tener barras. Si los descargamos con barras el navegador las cambiará por un guion bajo o intermedio. Para unificar el comportamiento en todos los navegadores reemplazo la barra por otro caracter configurable, como "^", con objeto de que posteriormente en la carpeta de descargas podemos identificar el archivo y trasladarlo a su destino según carpetas. Esto realmente es engorroso.
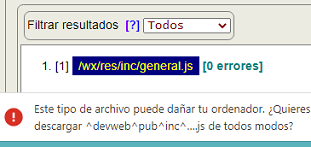
Y otro problema es cuando descargamos un archivo JavaScript, pues el navegador suele emitir una advertencia como la de la Figura, obligando al usuario a aceptar expresamente la descarga.
Para evitar estos contratiempos pensé en descargar los archivos en un ZIP. En lugar de usar gestores de ZIP existentes y de software libre, decidí construirme uno muy básico con el único objetivo de usarlo para descarga de múltiples archivos y de un tamaño no excesivo.
Creando una aplicación para descargar ZIP
En este apartado y siguientes de este tema se explica como usar el script zip.js para crear un ZIP a partir de archivos cargados desde su ordenador. Esta aplicación de ejemplo es precisamente eso, un ejemplo. Se limita el número de archivos a diez y el tamaño de la descarga a 1 MB. No se utilizan opciones. Los archivos en ningún caso son comprimidos ni cifrados.
Además el ZIP se limita a las opciones mínimas, pues la función que crea el ZIP es createZip({files, options}), donde files es el conjunto de archivos a descargar y options son opciones adicionales que pudiéramos configurar. En el tema siguiente explicaremos cómo se estructura un ZIP y el objetivo de las opciones. Aquí lo que nos interesa es como preparar los archivos para la función createZip() y como descargar el buffer obtenido. Empezamos presentando el ejemplo:
Ejemplo: Download ZIP
Lo primero es establecer lo necesario para obtener los archivos desde el ordenador. En el tema File API se explica como usar el objeto FileReader para leer archivos. Ahora además añadiremos como leer carpetas.
En el HTML tenemos un elemento <input type="file"> y una opción para seleccionar carpetas, inicialmente establecida:
<input type="checkbox" id="checkFolders" checked /> <input type="file" id="filesInput" multiple webkitdirectory mozdirectory msdirectory directory />
Si no se selecciona por carpetas entonces la selección es por archivos. En ese caso el atributo multiple indicará que se pueden seleccionar múltiples archivos. En la selección por carpetas ese atributo es ignorado y se selecciona la primera carpeta, tras lo cual se cargan todos sus archivos.
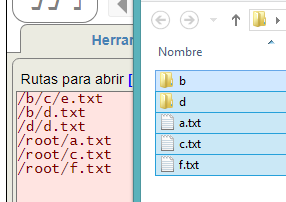
Esto se mejora en la herramienta ZIP, donde podemos arrastrar hasta un campo de rutas múltiples archivos y carpetas, cargándose todos los archivos individuales y los que están dentro de las carpetas. Como se observa en la Figura, arrastramos hasta el campo de rutas archivos y carpetas, listándose los archivos que están en el interior de las carpetas "b" y "d", mientras que los archivos que están por fuera se insertan en una carpeta "root".
Se activa la selección por carpetas incluyendo el atributo directory. Desde hace años no ha sido adoptado como estándar y es necesario prefijarlo. Los navegadores parecen aceptar webkitdirectory. De todas formas preferimos incorporar todas las posibilidades. Activar o desactivar el <input type="checkbox"> resulta en eliminar o incorporar esos atributos directory en el <input type="file">.
Una vez seleccionados los archivos y con el evento change, se ejecuta la función listFiles() que listará los archivos y los representará en un contenido de texto. Realizamos un filtrado para eliminar archivos sin contenido. Al final obtenemos files, una colección de archivos que hemos seleccionado con contenido.
let filesZip = {};
let buffer = null;
function listFiles(event){
let error = "";
try {
clearMsg();
filesZip = {}, buffer = null;
let filesInput = [...event.target.files].filter(v => v.size>0);
let files = [];
let max = Math.min(maxFiles, filesInput.length);
for (let i=0; i<max; i++){
let file = filesInput[i];
if (file.size>0) {
files.push({
name: file.name,
webkitRelativePath: file.webkitRelativePath,
lastModified: file.lastModified,
size: file.size,
type: file.type
});
}
}
if (max<filesInput.length) error = langApp==="es" ?
`AVISO: El número de archivos fue limitado a ${maxFiles}.\n` :
`WARNING: Number of files limited to ${maxFiles}.\n`;
document.getElementById("filesList").textContent = "files = " +
JSON.stringify(files, null, 2);
} catch (e){error = e.message}
if (error) insertMsg("filesList", error);
}
Las funciones clearMsg() e insertMsg() son funciones auxiliares para borrar mensajes y contenidos de la aplicación e insertar nuevos mensajes. No tiene mayor relevancia por lo que no las exponemos aquí. Puede ver el código completo de la aplicación de ejemplo en index.js, script para manejar el ejemplo.
Las variables globales filesZip y buffer se vacían en este función, pues contendrán los bytes de los archivos cuando se ejecute la función para leer los archivos que veremos en un siguiente apartado.
El <input type="file"> tiene la propiedad files. Obtenemos esta colección de archivos con event.target.files. Recuerde que esta función se ejecuta con el evento change cuando seleccionemos archivos, con lo que event.target nos trae la referencia a ese elemento. La propiedad files es un array, o mejor dicho, un objeto como un array (array-like), que contiene items que son objetos del tipo File como estos:
files = [
{
name: "index.html",
webkitRelativePath: "accesos-data/index.html",
lastModified: 1614890335273,
size: 89857,
type: "text/html"
},
{
name: "links.js",
webkitRelativePath: "accesos-data/links.js",
lastModified: 1614888083003,
size: 17830,
type: "text/javascript"
},
]Lo anterior refleja la selección de una carpeta accesos-data, que contiene dos archivos index.html y link.js. Observe que webkitRelativePath nos trae la ruta relativa respecto a la carpeta seleccionada. Nuevamente tenemos el prefijo webkit pues esto aún no es un estándar. En caso de selección por archivos esta propiedad aparecerá vacía, pero aún tendremos name que nos trae el nombre del archivo. La propiedad lastModified nos trae la fecha de la última modificación del archivo en formato número, fecha que podemos manejar con new Date(lastModified). El tamaño en bytes (size) nos servirá para controlar el tamaño total que vamos a descargar, algo que haremos en la siguiente función.
Leyendo los bytes de los archivos: método clásico
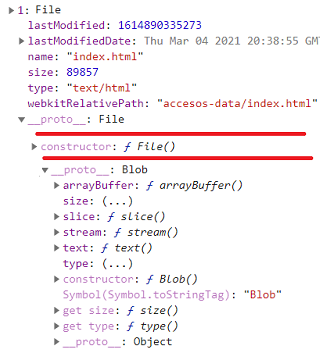
En la colección files que vimos en el apartado anterior no observamos por ningún lado el contenido del archivo. Para entenderlo hemos de saber que un archivo es un objeto del constructor File, que a su vez se construye con el prototipo de Blob. En la Figura puede ver la captura del archivo accesos-data/index.html que obtuvimos en el apartado anterior. Hemos eliminado algunos contenidos donde están las líneas rojas para no alargar en exceso la imagen.
Un Blob es un objeto con datos planos inmutables. Pueden ser, por ejemplo, los bits de un archivo. No son representables directamente. Sus contenidos se deben recuperar de una forma asíncrona, como veremos en este apartado. Inicialmente disponía del único método slice() para recortar su tamaño. Últimamente se han incorporado los nuevos métodos arrayBuffer(), text() y stream(), métodos que utilizan promesas para recuperar el contenido en distintos formatos.
Pero dejemos estos nuevos métodos un momento, pues ahora vamos a recuperar el contenido de los archivos con la siguiente clásica función para leerlos. Se trata de usar el objeto FileReader que nos devolverá un ArrayBuffer. Este es un objeto usado para representar datos binarios en un buffer de bits de cierta longitud específica.
Aún los datos en un ArrayBuffer no pueden utilizarse directamente. Para ello es necesario obtener una vista de los mismos. Para nuestro ZIP necesitamos que esa vista sea en bytes. Para ello usaremos new Uint8Array(arrayBuffer). Se genera un objeto array-like con los bytes como enteros sin signo (Uint8Array = Unsigned integer 8 Array). Este array será el contenido que le pasaremos a la función que creará el ZIP.
function readFiles(event){
let error = "";
try {
clearMsg(["filesZip", "docZip", "downloadResult"]);
filesZip = {}, buffer = null;
let filesInput = document.getElementById("filesInput").files;
if (filesInput.length===0) {
error = langApp==="es" ? "ERROR:..." : "ERROR:...";
} else {
let max = Math.min(maxFiles, filesInput.length);
let size = 0;
for (let i=0; i<max; i++){
let file = filesInput[i];
if (size+file.size>maxSize){
error = langApp==="es" ?
`AVISO: El ${i+1}º archivo y...` :
`WARNING: The ${i+1}th file and...`;
max = i;
break;
} else {
size += file.size;
let fileRead = new FileReader();
fileRead.addEventListener("load", (event) => {
let error = "";
try {
let arrayBuffer = event.target.result;
let path=file.webkitRelativePath || file.name;
filesZip[path] = {
date: file.lastModified,
content: new Uint8Array(arrayBuffer)
};
if (Object.keys(filesZip).length===max){
//Trace (or create zip and download)
traceFilesZip();
}
} catch (e){error = e.message}
if (error) insertMsg("filesZip", error, true);
});
fileRead.addEventListener("error", (event) => {
let path = file.webkitRelativePath || file.name;
insertMsg("filesZip", `ERROR path="${path}":...`);
});
fileRead.readAsArrayBuffer(file);
}
}
}
} catch (e){error = e.message}
if (error) insertMsg("filesZip", error);
}En el código anterior omitimos parte de los mensajes de error para aligerar el tamaño. Puede verlos en el enlace al código index.js. El FileReader dispone de los eventos load y error. Se activan con el método readAsArrayBuffer(file), que nos devolverá un ArrayBuffer cuando se finalice la lectura.
Obtenemos la vista new Uint8Array(arrayBuffer). Y con la fecha de la última modificación lo almacenamos en la variable global filesZip, pasando la ruta como clave del objeto. En max tenemos el número máximo de archivos que vamos a leer. Cuando se completen todas las lecturas tendremos en filesZip un objeto como el siguiente:
filesZip = {
"accesos-data/index.html": {
"date": "2021-03-04T20:38:55.273Z",
"content": [60, 33, 68, 79, 67, 84, 89, 80, 69, 32, "...89857"]
},
"accesos-data/links.js": {
"date": "2021-03-04T20:01:23.003Z",
"content": [47, 42, 32, 108, 105, 110, 107, 115, 46, 106, "...17830"]
}
}Con la función traceFilesZip() obtenemos la representación anterior del objeto filesZip, donde hemos convertido el número de la fecha en un formato String. Y además recortamos la vista del ArrayBuffer con los diez primeros elementos, indicando en el último el tamaño total. No exponemos el código de traceFilesZip() por no resultar significativo. Si lo necesita puede consultarlo en el código index.js. El objeto original filesZip es el que vamos a necesitar en un siguiente apartado para la función createZip({files}).
Observe en el código que pusimos el comentario //Trace (or create zip and download), pues en lugar de trazar nada podríamos aquí crear el zip y descargarlo en un único paso. En esta aplicación de ejemplo lo haremos en varias fases para observarlo mejor.
Leyendo los bytes de un archivo: nuevos métodos
En el tema sobre Generadores y promesas expliqué como funciona una Promesa. Es un objeto que representa un valor futuro, que en su momento podría resolverse a un valor o rechazarse por un motivo. Es, por tanto, algo para usar claramente con tareas asíncronas. Y esto de la lectura de un archivo es claramente una tarea asíncrona. Antes lo resolvimos con el FileReader y el evento load. Ahora lo vamos a resolver con una promesa.
El caso es que el objeto File dispone de nuevos métodos como comentamos en el tema anterior. Uno de ellos es arrayBuffer(), una función que devuelve una promesa para recuperar el ArrayBuffer del archivo.
En el código anterior sustituimos el trozo desde la sentencia let fileRead = new FileReader() hasta la sentencia fileRead.readAsArrayBuffer(file) inclusives por el siguiente código:
file.arrayBuffer().then(
(arrayBuffer) => {
let error = "";
try {
let path = file.webkitRelativePath || file.name;
filesZip[path] = {
date: file.lastModified,
content: new Uint8Array(arrayBuffer)
};
if (Object.keys(filesZip).length===max){
traceFilesZip();
}
} catch (e){error = e.message}
if (error) insertMsg("filesZip", error, true);
},
(error) => {
let path = file.webkitRelativePath || file.name;
insertMsg("filesZip", `ERROR path="${path}": ${error}`, true);
}
);Vemos que file.arrayBuffer() devuelve una promesa que vamos a gestionar con then, incluyéndose en el primer argumento la función que resuelve la promesa, trayendo en el argumento el arrayBuffer que estamos esperando. Y en la segunda función la que la rechaza, portando el mensaje de error.
Veamos a hora otro método usando las funciones asíncronas. Se designan anteponiendo la palabra clave async. En el siguiente código tenemos una función flecha, anónima, asíncrona y autoejecutable. Observe que async no es el nombre de la función, sino la palabra clave que caracteriza una función como asíncrona.
(async () => {
try {
let path = file.webkitRelativePath || file.name;
let arrayBuffer = await file.arrayBuffer();
filesZip[path] = {
date: file.lastModified,
content: new Uint8Array(arrayBuffer)
};
if (Object.keys(filesZip).length===max){
traceFilesZip();
}
} catch(e){
let path = file.webkitRelativePath || file.name;
insertMsg("filesZip", `ERROR path="${path}": ${e}. `, true);
}
})();Designar la función como asíncrona nos permitirá usar el operador await. Como file.arrayBuffer() devuelve una promesa, este operador hace que la ejecución de la función asíncrona se pause en ese punto hasta que esa promesa se resuelva o rechace. Si se resuelve se obtiene el ArrayBuffer y se sigue ejecutando el código pausado. Si se rechaza genera un error que podemos interceptar con el bloque try-catch.
Este último método de funciones asíncronas aporta un código más simple de leer, pues no es necesario disponer de funciones para resolver o rechazar que teníamos en los anteriores. Todo pasa por entender y acostumbrarse a las palabras claves async y await.
Creando y descargando el ZIP
El módulo zip.js se carga al iniciar el módulo de la aplicación index.js que ejecuta el ejemplo anterior. Iniciamos el módulo ZIP en una variable global al módulo de la aplicación con const zip = Wextensible.startZip(), donde Wextensible es una variable global que actúa a modo de espacio de nombres. El objeto zip contiene un único método createZip({files=null, options=null, tracing=false}) que devuelve el objeto {error: "", warning: [], arrayBytes: null, trace: []}. Devuelve una traza siempre que activemos el argumento tracing. Si hay un error la ejecución se detiene y devuelve el mensaje de error. En cambio siempre devolverá la lista de avisos en warning sin detenerse la ejecución. Se comentará más sobre estos avisos en el tema siguiente.
En esta aplicación de ejemplo sólo usaremos el argumento files con una estructura que ya obtuvimos antes. Explicaremos las opciones en el tema siguiente. En la lectura de los archivos íbamos componiendo la variable global filesZip. Como vimos para un ejemplo que recuperaba dos archivos, obteníamos la siguiente traza:
filesZip = {
"accesos-data/index.html": {
"date": "2021-03-04T20:38:55.273Z",
"content": [60, 33, 68, 79, 67, 84, 89, 80, 69, 32, "...89857"]
},
"accesos-data/links.js": {
"date": "2021-03-04T20:01:23.003Z",
"content": [47, 42, 32, 108, 105, 110, 107, 115, 46, 106, "...17830"]
}
}El siguiente paso es crear el ZIP. Si hay un error nos vendrá una cadena de texto con el mensaje de error. En arrayBytes vendrá un Uint8Array con el buffer del ZIP. El array de la traza en trace vendrá vacía dado que no activamos el argumento tracing.
function createZip(event){
let error = "";
try {
clearMsg(["docZip", "downloadResult"]);
if (Object.keys(filesZip).length===0){
error = langApp==="es" ? "ERROR:..." : "ERROR:...";
} else {
let res = zip.createZip({files: filesZip});
if (res.error){
error = res.error;
} else {
buffer = res.arrayBytes;
document.getElementById("docZip").textContent = "...";
}
} catch (e){error = e.message}
if (error) insertMsg("docZip", error);
}Y por último descargaremos el buffer usando URL.createObjectURL(blob), tomando como Blob el creado con el buffer y con tipo de salida application/octet-stream, que no es otra cosa que una ristra de bytes (octetos). Conviene eliminar el objeto URL con URL.revokeObjectURL(href) pues ocupará espacio de memoria sin necesidad tras la descarga.
function downloadZip(event){
let error = "";
try {
clearMsg(["downloadResult"]);
if (buffer===null){
error = langApp==="es" ? "ERROR:..." : "ERROR:...";
} else {
let blob=new Blob([buffer],{type:"application/octet-stream"});
let href = window.URL.createObjectURL(blob);
let link = document.createElement("a");
link.href = href;
link.download = "download.zip";
link.style.display = "none";
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
window.URL.revokeObjectURL(href);
document.getElementById("downloadResult").textContent = "...";
}
} catch (e){error = e.message}
if (error) insertMsg("downloadResult", error);
}Hasta aquí todo lo necesario para usar createZip() del módulo zip.js. En el siguiente tema intentaremos explicar como se construye un ZIP.