Referencias XLSX
Referencias y rangos en WXTABLE
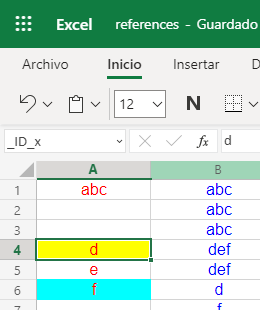
Conocer las referencias a celdas y rangos en XLSX es importante antes de estudiar las fórmulas en XLSX. En la Figura puede ver una celda con fondo amarillo que se identifica con la cadena _ID_x. Es una captura en EXCEL del ejemplo que usaremos para este tema, ejemplo cuyos datos en formato WXTABLE puede encontrar en este enlace references.txt y en formato XLSX en references.xlsx.
En WXTABLE cuando declaramos atributos y estilos, una referencia a una celda es M,N donde M es el número de fila y N el de columna. Se inician en cero, con lo que 0,0 referencia la tabla, M,0 referencia la fila M y 0,N referencia la columna N. Cuando referenciamos en WXTABLE dentro de las fórmulas usamos la forma [RMCN] donde R y C son letras literales. Así que 1,1 y [R1C1] son dos formas de referenciar la primera celda superior izquierda de valores.
Un rango es una zona obligatoriamente rectangular de celdas definido por la celda superior izquierda y la inferior derecha, separando ambas referencias con dos puntos (":"). Así que 1,1:10,3 es el rango que cubre el rectángulo desde la celda 1,1 hasta la celda 10,3. En las fórmulas lo expresaríamos como [R1C1]:[R10C3].
Las referencias como [R1C1] con "R" y "C" mayúsculas seguidas de un número mayor o igual que cero son referencias absolutas. Además existen las referencias relativas, que son de la forma [r±Mc±N], con "r" y "c" minúsculas, donde el signo puede ser positivo, negativo o ninguno, en cuyo caso se entiende positivo. M y N son números mayores o iguales que cero. Supongamos que estamos ubicados en la celda X,Y y ahí ubicamos una fórmula como la siguiente =[r+2c-3] (o bien =[r2c-3] pues el signo + es opcional), con lo que estamos referenciando una celda 2 filas más abajo y 3 columnas a la izquierda. Es decir, estamos referenciando la celda X+2,Y-3.
Se pueden mezclar referencias absolutas y relativas. Por ejemplo, con [R1c+2] nos referimos a la fila 1 y dos columnas a la derecha de la posición actual donde se ubica la fórmula.
Por último para referirnos a una referencia en otra hoja pondríamos [Tab2!R1C1], que referencia la celda 1,1 de la hoja Tab2. Las referencias en la propia hoja pueden incluirse o obviarse, puesto que si una referencia no tiene nombre de hoja se supone que pertenece a la hoja donde esté ubicada.
En XLSX esto funciona de forma similar. En el apartado siguiente veremos como se traducen estas referencias a XLSX usando el ejemplo de la Figura.
Referencias absolutas y relativas en XLSX
A continuación se muestran los datos en formato WXTABLE de este ejemplo:
{
"sheets": {
"Tab1": {
"attributes": {
"1,2": {
"data-formula": "=[R1C1]"
},
"2,2": {
"data-formula": "=[r-1c-1]"
},
"3,2": {
"data-formula": "=[r-2C1]"
},
"4,1": {
"data-id": "x"
},
"4,2": {
"data-formula": "=join(\"\",[R4C1]:[R6C1])"
},
"5,2": {
"data-formula": "=join(\"\",[r-1c-1]:[r1c-1])"
},
"6,1": {
"data-id": "y"
},
"6,2": {
"data-formula": "=[id=x]"
},
"7,2": {
"data-formula": "=[id=y]"
},
"8,2": {
"data-formula": "=join(\"\",[id=x]:[id=y])"
},
"9,2": {
"data-formula": "=[RMC1]"
},
"10,2": {
"data-formula": "=join(\"\",[R9C1]:[RMC1])"
},
"11,2": {
"data-formula": "=[Tab2!R1C1]"
}
},
"styles": {
"1,3:11,3;0,3": "width:200px;",
"1,4:11,5;0,4:0,5": "width:300px;",
"1,1;5,1;9,1:11,1": "color:rgb(255, 0, 0);text-align:center;",
"1,2:11,2": "color:rgb(0, 0, 255);text-align:center;",
"2,1:3,1;7,1:8,1": "text-align:center;",
"4,1": "color:rgb(255, 0, 0);background-color:rgb(255, 255, 0);text-align:center;",
"6,1": "color:rgb(255, 0, 0);background-color:rgb(0, 255, 255);text-align:center;"
},
"values": [
["1", "2", "3", "4", "5"],
["abc","abc","[R1C1]","$A$1","Referencia absoluta"],
["","abc","[r-1c-1]","A1","Referencia relativa"],
["","abc","[r-2C1]","$A1","Referencia mezclada"],
["d","def","join(\"\",[R4C1]:[R6C1])","TEXTJOIN(\"\";FALSE;$A$4:$A$6)","Rango absoluto"],
["e","def","join(\"\",[r-1c-1]:[r1c-1])","TEXTJOIN(\"\";FALSE;A4:A6)","Rango relativo"],
["f","d","[id=x]","_ID_x","Referencia identificada"],
["","f","[id=y]","_ID_y","Referencia identificada"],
["","def","join(\"\",[id=x]:[id=y])","TEXTJOIN(\"\";FALSE;_ID_x:_ID_y)","Rango con referencias identificadas"],
["g","f","[RMC1]","$A$11","Referencia máxima fila"],
["h","ghf","join(\"\",[R9C1]:[RMC1])","TEXTJOIN(\"\";FALSE;$A$9:$A$11)","Rango con referencia máxima fila"],
["i","ABC","[Tab2!R1C1]","'Tab2'!$A$1","Referencia en otra hoja"]
]
},
"Tab2": {
"attributes": {},
"styles": {},
"values": [
["1", "2"],
["ABC", ""],
["", ""]
]
}
},
"images": []
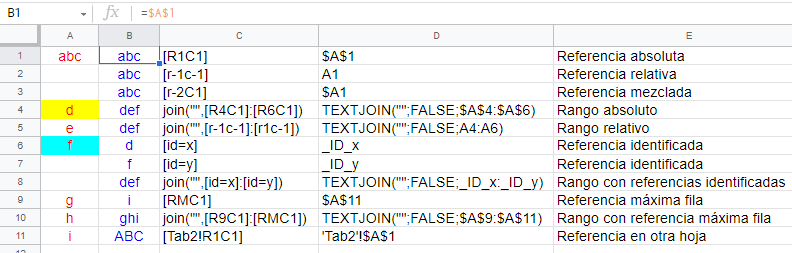
}En la Figura puede ver una captura de pantalla en GoogleSheet del libro XLSX de ejemplo. Observe que tiene dos hojas: "Tab1" y "Tab2". En la primera columna hay valores de texto en algunas celdas. En la segunda columna están las fórmulas. En la tercera se expone como sería esa fórmula en WXTABLE, mientras que en la cuarta se expone como es en XLSX. En la última columna hay una definición del tipo de referencia o rango.
Como comentamos en el tema anterior, las fórmulas se ubican en el elemento <sheetData> del archivo xl/worksheets/sheet1.xml. Veamos la primera fila:
<sheetData>
<row r="1" hidden="0">
<c r="A1" t="s" s="1">
<v>0</v>
</c>
<c r="B1" t="str" s="2">
<f>$A$1</f>
<v>abc</v>
</c>
<c r="C1" t="s" s="0">
<v>1</v>
</c>
<c r="D1" t="s" s="0">
<v>2</v>
</c>
<c r="E1" t="s" s="0">
<v>3</v>
</c>
</row>
...
</sheetData>Abreviamos código con puntos suspensivos. Están las 5 columnas que vemos en la Figura. A excepción de la segunda columna, el resto son valores de texto que se almacenan en el archivo de cadenas compartidas, tal como explicamos en el tema anterior. La columna que nos interesa observar es la segunda:
<row r="1" hidden="0">
...
<c r="B1" t="str" s="2">
<f>$A$1</f>
<v>abc</v>
</c>
...
</row>Observe que la celda está ubicada en la referencia r="B1". En XLSX las referencias a celdas son de la forma CN donde "C" es una o más letras desde la "A" a la "XFD" que identifican las 16384 columnas posibles. Y la "N" es un número entero mayor que cero que referencia la fila. Así que B1 es la segunda columna en la primera fila.
En la celda B1 tenemos la fórmula $A$1 en el elemento <f>, fórmula que referencia la celda en la primera columna y primera fila. El resultado de esta fórmula es "abc", valor que está en la celda A1. El signo "$" en la referencia hace que la misma sea absoluta. Así que $A$1 en XLSX es la traducción de la referencia [R1C1] en WXTABLE.
En la segunda fila vemos que hay una referencia relativa A1, traducción de [r-1c-1] en WXTABLE:
<row r="2" hidden="0">
...
<c r="B2" t="str" s="2">
<f>A1</f>
<v>abc</v>
</c>
...
</row>Se pueden mezclar referencias como en la tercera fila, con la referencia $A1 que es la traducción de [r-2C1] en WXTABLE:
<row r="3" hidden="0">
...
<c r="B3" t="str" s="2">
<f>$A1</f>
<v>abc</v>
</c>
...
</row>Las referencias absolutas y relativas en WXTABLE y XLSX no funcionan igual. Si desde una determinada celda referenciamos absolutamente en WXTABLE con [R1C1], al trasladar la fórmula a otra celda la referencia sigue siendo [R1C1]. Mientras que si es relativa [r-1c-1] desde la celda 2,2, al trasladar la fórmula a otra celda se referirá a la que está una fila por encima y una columna a la izquierda de la nueva posición.
En Excel y GoogleSheet esto funciona de otra forma. La diferenciación entre absoluta y relativa es que las absolutas (con "$") nos permite arrastrar el contenido para copiarlo en celdas adyacentes manteniéndose la referencia absoluta. Si es relativa se traslada a la posición relativa en la nueva ubicación. En Excel y GoogleSheet se actualizan todas las referencias existentes que apunten a una celda al cortar y pegar o mover esa celda. También se actualizan referencias en en los casos de insertar o eliminar filas o columa. Ambas cosas no se contemplan en WXTABLE. Vease que estas son características de las aplicaciones y no del propio XLSX.
Rangos XLSX
Las filas 4 y 5 del ejemplo contienen fórmulas que usan el rango $A$4:$A$6 y A4:A6. Estos rangos son las celdas A4, A5 y A6 que contienen los valores "d", "e" y "f". En WXTABLE se insertan las fórmulas join("",[R4C1]:[R6C1]) y join("",[r-1c-1]:[r1c-1]) en las celdas de la segunda columna de las filas cuarta y quinta respectivamente.
La función join(separador, lista_valores) concatena una lista de valores con el separador. La lista de valores puede ser una verdadera lista como join("", "d", "e", "f") devolviendo "def". O bien un rango como en ese caso join("",[R4C1]:[R6C1]) devolviendo también "def". Tiene una traducción a XLSX con TEXTJOIN("", FALSE, rango). Aunque en ejecución hay que anteponer el prefijo _xlfn como se observa en el archivo XML:
<row r="4" hidden="0">
...
<c r="B4" t="str" s="2">
<f>_xlfn.TEXTJOIN("",FALSE,$A$4:$A$6)</f>
<v>def</v>
</c>
...
</row>
<row r="5" hidden="0">
...
<c r="B5" t="str" s="2">
<f>_xlfn.TEXTJOIN("",FALSE,A4:A6)</f>
<v>def</v>
</c>
...
</row>En un tema siguiente explicaremos el motivo de usar el prefijo _xlfn.
Celdas identificadas XLSX
Como se ha dicho en un apartado anterior, WXTABLE no actualiza referencias en ningún caso. Para paliar esta falta se pueden identificar las celdas. En WXTABLE se identifica una celda con el atributo data-id="x", usando como ejemplo de nombre identificativo la cadena "x". Recuerde que una celda en WXTABLE no es otra cosa que un elemento <td>. En las fórmulas se identificaría esa celda con algo como =[id=x], de tal forma que la aplicación del Gestor de Tablas lo que hace es buscar una celda con el atributo data-id="x". Esto permitirá insertar o eliminar filas o columnas y, mientras no se elimine la identificación, siempre podrá encontrarse la celda <td data-id="x">.
En el objeto de datos de WXTABLE del ejemplo podemos ver donde están los atributos data-id:
{
"sheets": {
"Tab1": {
"attributes": {
...
"4,1": {"data-id": "x"},
...
"6,1": {"data-id": "y"},
...
},
"styles": { ... },
"values": [ ... ]
},
"Tab2": { ... }
},
"images": []
}Esto también es posible en XLSX. En la traducción que hacemos desde WXTABLE modificamos el nombre de ejemplo "x" con un prefijo, quedando _ID_x. En el libro de ejemplos hay dos celdas identificadas que aparecen con fondos amarillo y azul. La primera es _ID_x y la segunda _ID_y. Observe esto en EXCEL en la primera imagen de este tema. En celdas de la segunda columna se usan fórmulas =_ID_x y =_ID_y que apuntan a aquellas celdas (mientras que en WXTABLE esas fórmulas son [id=x] y [id=y]):
<row r="6" hidden="0">
...
<c r="B6" t="str" s="2">
<f>_ID_x</f>
<v>a</v>
</c>
...
</row>
<row r="7" hidden="0">
...
<c r="B7" t="str" s="2">
<f>_ID_y</f>
<v>a</v>
</c>
...
</row>En XLSX las celdas se identifican en el elemento <definedNames> del archivo xl/workbook.xml. Se identifican siempre anteponiendo el nombre de la hoja, puesto que estas identificaciones están disponibles para todas las hojas del libro. Vease que este libro de nuestro ejemplo tiene dos hojas "Tab1" y "Tab2":
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<workbook xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships">
<sheets>
<sheet state="visible" name="Tab1" sheetId="1" r:id="rId4"/>
<sheet state="visible" name="Tab2" sheetId="2" r:id="rId5"/>
</sheets>
<definedNames>
<definedName name="_ID_x">'Tab1'!$A$4</definedName>
<definedName name="_ID_y">'Tab1'!$A$6</definedName>
</definedNames>
</workbook>XLSX también permite identificar rangos, algo que por ahora no es posible en WXTABLE. Aunque si es posible que las celdas identificadas formen parte de un rango, como en el ejemplo para el rango [R4C1]:[R6C1] con [id=x]:[id=y], que son los contenidos "d", "e" y "f", usando la fórmula join("",[id=x]:[id=y]) en WXTABLE y TEXTJOIN("",FALSE,_ID_x:_ID_y) en XLSX:
<row r="8" hidden="0">
...
<c r="B8" t="str" s="2">
<f>_xlfn.TEXTJOIN("",FALSE,_ID_x:_ID_y)</f>
<v>def</v>
</c>
...
</row>Entre ese rango vertical [id=x]:[id=y] podemos insertar o eliminar filas tal que mientras mantengamos las referencias primera y última, el rango siempre estará correctamente identificado.
Referencias fila final y columna final
En WXTABLE es posible referenciar la última fila y última columna. Con [RMC1] referenciamos la fila máxima y primera columna, que en el ejemplo es la fila 11 (sólo hay 11 filas) y la columna 1. Con [RMCM] referenciaríamos la última fila inferior derecha de una tabla WXTABLE, celda [R11C5]. Recuerde que en WXTABLE el número de filas y columnas se limita a los que necesitemos. Además se indican al exportar a XLSX en el elemento <dimension> el rango de la tabla WXTABLE, con objeto de que las aplicaciones que manejen el XLSX puedan optimizar los procesos reconociendo el área de datos:
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships">
<dimension ref="A1:E11"/>
...El ejemplo de la fila 9 referencia la última celda en la primera columna [RMC1] como $A$11 cuyo contenido es la letra "i".
<row r="9" hidden="0">
...
<c r="B9" t="str" s="2">
<f>$A$11</f>
<v>f</v>
</c>
...
</row>En el ejemplo se usa la función join("",[R9C1]:[RMC1]) que une los contenidos desde la celda desde la fila 9 hasta la última fila disponible e ignorándose las celdas con contenido vacío. Esto en XLSX se traduce con TEXTJOIN("",FALSE,$A$9:$A$11), donde el segundo argumento con valor FALSE indica que se ignoren las celdas vacías.
<row r="10" hidden="0">
...
<c r="B10" t="str" s="2">
<f>_xlfn.TEXTJOIN("",FALSE,$A$9:$A$11)</f>
<v>f</v>
</c>
...
</row>En la configuración del módulo exportador podemos variar este comportamiento. En lugar de usar la máxima fila y/o columna disponible en WXTABLE podemos modificar el valor del configuración maxRow o maxCol a un valor como 1000, pues inicialmente Excel y GoogleSheet se inician con al menos 1000 filas y 1000 columnas. Por defecto la configuración de esos parámetros tienen valor cero, con lo que se aplicará la máxima fila y columnas disponibles en WXTABLE. Si usáramos el valor maxRow=1000, la fórmula resultante sería _xlfn.TEXTJOIN("",FALSE,$A$9:$A$1000). Cuando se cargue el XLSX el valor resultante "f" será modificado a una cadena vacía "" en GoogleSheet o un 0 en Excel en caso de que la celda A1000 estuviese vacía.
En XLSX es posible referenciar una columna o una fila completa. Así que algo como [R9C1]:[RMC1] puede ponerse como A9:A en XLSX seleccionando la primera columna "A" desde la fila 9 hasta la última. De igual forma algo como [R1C3]:[R1CM] puede ponerse como C1:1 en XLSX seleccionando la primera fila desde la columna "C" hasta la última columna. Esta representación no es posible por ahora en WXTABLE y por tanto no lo uso en la traducción a XLSX.
Referencias a otra hoja
Las referencias a otra hoja en WXTABLE son como [Tab2!R1C1]. En XLSX se traduce de forma parecida con 'Tab2'!$A$1. Hay un ejemplo en la fila 11:
<row r="11" hidden="0">
...
<c r="B11" t="str" s="2">
<f>'Tab2'!$A$1</f>
<v>ABC</v>
</c>
...
</row>En WXTABLE los nombres de hoja empieza con una o más letras [a-zA-Zá-úÁ-ÚüÜñÑçÇ]+ seguido de cero o más de esas letras incluyendo dígitos númericos. Este es el código JavaScript que compone la expresión regular:
const strRegSheet = `[a-zA-Zá-úÁ-ÚüÜñÑçÇ]+[a-zA-Zá-úÁ-ÚüÜñÑçÇ.-]*`;
const regSheet = new RegExp(`^(${strRegSheet})(\\d*)$`);Al hacerlo así evitamos el uso de comillas en los nombres de las hojas, pues en XLSX puede contener cualquier caracter, pero con un soporte para escapar caracteres inválidos en XML, como por ejemplo con los espacios. Esto se observa en OOX en el apartado 18.2.19 sheet (Sheet Information), página 1578, que remite al apartado 22.9.2.19 ST_Xstring (Escaped String), página 3811. Para evitar comprobar si es una cadena válida se escapan con comillas simples en el nombre de la hoja, como se observa en la traducción [Tab2!R1C1] de WXTABLE a 'Tab2'!$A$1 en XLSX.
En XLSX también se permiten referencias a otros libros, algo que no se contempla en WXTABLE. Hay muchas otras cosas de XLSX que WXTABLE no soporta. Como el objetivo es exportar desde WXTABLE a XLSX, estas ausencias de características no afectan a la exportación. Podría por supuesto afectar a la importación desde XLSX a WXTABLE, pero por ahora no contemplo implementar la importación.