Sintaxis HTML-5
Migrando desde XHTML a HTML-5
Este sitio está escrito con sintaxis XHTML-1.0 aunque es servido como text/html. En estos momentos hay unos 372 documentos con extensión html, php y algunos xhtml. Pero la mayor parte son ejemplos, pues los verdaderos documentos son sólo 94. No voy a convertir los ejemplos pues fueron escritos con sintaxis XHTML y no tiene razón cambiarlos. Además los navegadores los seguirán presentando sin mayor problema. Sin embargo los documentos son los que llevan el verdadero contenido del sitio y también aún están a medio hacer. En el pie por ejemplo y a fecha de hoy (octubre 2011) faltan botones como los de aviso legal o mapa web y quiero ponerlos sólo cuando sepa de qué va cada cosa, pues no puedo limitarme a copiar y pegar. Así que intentaré migrar estos documentos a HTML-5 y seguir actualizando y completando las páginas.
La migración tiene que ir acorde al estudio de las diferentes características de HTML-5. Primero atacaré el tema de la cabecera de los documentos, el <!DOCTYPE>, el <html> y lo que va dentro del <head>. En un paso posterior intentaré ajustar la estructura de mis documentos a los nuevos elementos de secciones como <section>, <nav>, <footer>, etc. Creo que podré hacerlo pues todos mis documentos tienen la misma estructura basada en elementos <div> como <div class="cabeza">, <div class="botonera">, <div class="pie">, etc.
Una plantilla de HTML-5 ahora es más sencilla, empezando sólo con:
<!DOCTYPE html> <html lang="es">
Ya no son necesarias las "ristras" que ponía antes:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="es" xml:lang="es">
Pero antes las ponía y de alguna forma intentaba saber porqué lo hacía (Elementos de cabecera en XHTML-1.0). Ahora intentaré hacer lo mismo preguntándome porqué sólo ponemos <!DOCTYPE html> o que pasó con el espacio de nombres xmlns dentro del <head>. Si me limito a copiar y pegar es posible que funcione, pero es seguro que no sabré porqué funciona.
No parece apropiado hacer los cambios manualmente. Si todos los documentos tienen una misma estructura, es fácil usar una herramienta para eso. Facilitaré la migración usando la herramienta para reemplazar texto.
HTML-5 escrito con sintaxis XHTML
Aún tengo muchas dudas de cómo afrontar el cambio XHTML a HTML-5. Un artículo publicado por Louis Lazaris llamado My Preferred Syntax Style for HTML5 Markup puede aclararnos algo sobre esta materia. Aunque no estoy totalmente de acuerdo con todas sus preferencias, si lo estoy con la idea de que cada uno debe buscar su propio estilo, al menos hasta donde los navegadores nos dejen hacerlo. Hay algunos puntos que me interesa comprobar, consultando directamente en el WHATWG la parte de sintaxis HTML.
Mayúsculas o minúsculas
HTML-5 permite usar indistintamente mayúsculas o minúsculas para los nombres de los elementos o atributos. Por ejemplo <INPUT value="abc">, con el nombre del elemento en mayúsculas y el nombre del atributo en minúscula. Incluso podemos poner <!DOCTYPE html> o <!doctype html> o <!doctype HTML>.
Elementos vacíos
Son elementos como <br />, escrito así en XHTML, con la barra al final y un espacio antes. En HTML-5 podemos eliminar la barra quedando <br>, igual que en HTML-4, pero también da la posibilidad de usarla, tal como se especifica en el apartado Elements - Start tags [WHATWG], diciendo algo como esto: ...si el elemento es vacío o externo podría haber una barra al final. Este caracter no tiene ningún efecto en estos elementos vacíos, pero en elementos externos marca el fin del autocierre
. Los externos son los que se importan de los espacios de nombres MathML o SVG.
WHATWG responde a la pregunta ¿Debería cerrar los elementos con /> o >? diciendo que debido al uso generalizado de la barra en un número importante de páginas ya escritas, consideran que se ha de permitir para ayudar a facilitar la migración desde XHTML de vuelta a HTML. Quizás quede más claro con el principio del W3C pave the cowpaths o mi traducción personal construyendo sobre lo que ya existe. Porqué si se permite y lo seguimos usando, al final se quedará de facto en el lenguaje.
Elementos vacíos en SGML, XHTML y HTML
HTML nace usando el lenguaje de marcas SGML ya existente. Luego viene XML-XHTML. El concepto inicial de poner <br> en HTML se basaba en una omisión permitida de tag de cierre, es decir, es una facilidad para escribir el elemento que en realidad es <br></br>. Pero el <br /> con la barra al final es un invento de XML para hacerlo compatible con versiones anteriores de SGML. Esto lo podemos ver en la especificación SGML, por ejemplo en el documento de referencia Web SGML and HTML 4.0 Explained de Martin Bryan. Parece ser que se definió una excepción a SGML (el Anexo K) para permitir marcar elementos vacíos como <br/> en lugar de tener que escribir <br></br>, especialmente para XML-1.0. Pues XML soporta <br></br> pero no las omisiones de tag como <br>. Pero si no se tiene en cuenta esa excepción, una marca como <br/> se debería entender en HTML-SGML como <br>>: Sí, con dos caracteres mayor que a la derecha.
La respuesta a esto está en el concepto de minimización de elementos en SGML, específicamente el llamado null end tags (NET) dentro del grupo de minimización de los short tags. Este aspecto no lo contempla HTML. Así <em>foo</em> puede minimizarse como <em/foo/. Por lo tanto <br/ es la minimización de <br></br>, que a su vez con la omisión de tag de cierre de SGML quedaría <br>. Pero si ponemos <br /> como dice XML-XHTML debería ser entendido según SGML como <br>> pues el mayor que de la derecha no cierra ningún tag y se considera un caracter de texto legítimo. Sin embargo los navegadores renderizando HTML tratan los elementos vacíos de la forma XML-XHTML como una excepción. Así <br /> lo "arreglan" los navegadores actuales en HTML (no en XHTML) considerándolo como el string <br> después de aplicar también el concepto de omisión de tag de cierre.
La historia de Internet y específicamente de HTML es un verdadero lío. Lo anterior se explica en el documento Empty elements in SGML, HTML, XML, and XHTML, artículo escrito por Jukka Korpela que abre diciendo:
Los elementos vacíos fueron introducidos en HTML por error: los tag presentacionales se deslizaron en HTML contrariamente al espíritu de SGML ...
Ese artículo me ha aclarado algo, pues habían muchas cosas que no acababa de entender en HTML y esto de los elementos vacíos era una de ellas. HTML y también XML-XHTML pretendían basarse en SGML, donde ningún elemento debería ser vacío. Es decir, todos los elementos deben tener contenido. Otra cosa es que inicialmente ese contenido esté vacío. La idea inicial era que HTML portaría el contenido de texto del documento con una estructura adecuada, mientras que los aspectos de presentación (el estilo) se debían insertar con CSS. Separar contenido de estilo era la clave. ¿Entonces que pintan los elementos vacíos de HTML-XHTML que no tienen contenido?.
También hay elementos que tienen contenido indebidamente ubicado en un atributo. Como en un <input type="text" value="..." >, un ejemplo de un elemento con contenido en su value. Los atributos caracterizan un elemento y no deberían portar su contenido. Por otro lado el elemento <img> no tiene nada que ver con el contenido. Debería ser incorporado con estilo. O en todo caso hacer lo mismo que el elemento <object> que acompaña un contenido para cuando el recurso no pueda ser presentado. De hecho éste se creó para intentar reemplazar al anterior, pero no ha tenido éxito. ¿Y que decir de los <meta>? ¿Porqué no puede ser <meta name="description" content="xxxxx" > como <meta name="description">xxxxx</meta> con el valor de content en su sitio lógico? Los elementos <br> y <hr> se llevan el premio en este aspecto. Son elementos sin contenido por naturaleza. ¿Qué hacen? ¿Separar contenidos de texto?. Para eso están los párrafos <p>. De hecho inicialmente <p> era un separador de texto como podía ser <br> y por eso se podía (y aún se mantiene) omitir el tag de cierre. En una especificación posterior ese separador de párrafos se convirtió en un verdadero elemento con contenido: el párrafo es su contenido. Pero aún podemos seguir omitiendo el tag de cierre.
Atributos con comillas
WHATWG especifica que cuando los valores de los atributos no contienen espacios podemos ponerlo sin comillas. Por ejemplo <input value=algo />. Cuando hay espacios hemos de poner comillas dobles <input value="algo así" /> o bien simples <input value='algo así' />.
Atributos booleanos
Los atributos llamados booleanos son aquellos que cuando aparecen significa que toman el valor verdadero, por lo que tienen por defecto el valor falso. Por ejemplo el atributo disabled pondrá un control de formulario como desactivado. Así <input /> no contiene explícitamente ese atributo y por tanto se sobreentiende como que el control no está desactivado. Usamos el atributo poniendo <input disabled /> sin más. Así era en HTML-4 y sigue siendo en HTML-5. Pero en XHTML había que ponerlo así: <input disabled="disabled" />. Por ejemplo, estos tres cuadros de texto deberán aparecer desactivados:
Ejemplo:
De hecho los navegadores encuentran el nombre del atributo disabled e ignorarán cualquier valor que se ponga, como el último que hemos puesto disabled="xxx".
Omisiones de elementos
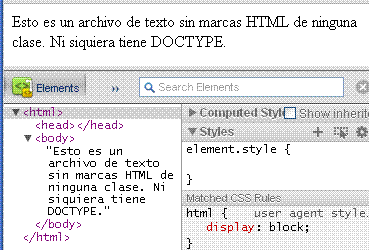
En HTML-5 hay muchas cosas que podemos omitir. Por ejemplo, envíamos desde el servidor el archivo sin-marcas.html. Se remite como un documento text/html pero el contenido es sólo texto, sin marcas HTML de ninguna clase. En Chrome podemos analizar el DOM construido, tal como vemos en la imagen de al lado. Vemos que, aunque no pusimos ningún elemento HTML, al cargar el DOM en el navegador se consideran implícitos los elementos <html>, <head> y <body>. Esto de hecho ya venía sucediendo así y HTML-5 no ha hecho otra cosa que adaptarse a lo que ya existía. Y esto es que el navegador recibe un tipo text/html y entiende que debe ser un documento HTML, por lo que "rellena" los elementos mínimamente indispensables que le falten para tratar de acomodarlo en el DOM.
Es el mismo caso de <table>, otra cosa que también ya se daba, que era la necesidad de que una tabla contenga al menos un <tbody> (cuerpo de tabla). Aunque no era ni es necesario especificarlo, en caso de que no se provea el navegador rodeará todos los <tr> o filas de la tabla con ese elemento. De igual forma se pueden omitir las etiquetas finales de los elementos <p> o <li> entre otros, aunque esto es más bien por mantener la costumbre adquirida en el uso (o abuso) de la omisión de tags de cierre.
Atributos por defecto
En cuanto a los atributos si es verdad que HTML-5 especifica muchos de ellos por defecto. Por ejemplo, el atributo type era requerido en HTML-4 para el elemento <script>. Supongo que antes era así porque también se usaba VBScript, pero ahora es JavaScript el lenguaje de mayor uso. Por lo tanto con HTML-5 ese atributo tiene el valor por defecto text/javascript, por lo que puede omitirse.
El elemento script y las secciones CDATA
Con el elemento <script> en XHTML teníamos una limitación al usar los caracteres especiales < y & dentro de un script, tal como comenté en mi glosario XHTML 1.0. El script debía ser encerrado en unas secciones CDATA a su vez escapadas como comentarios en JavaScript, como en este ejemplo:
<script type="text/javascript">
//<![CDATA[
var a=true;
var b=true;
if (a && b) {
document.write("<b>PLUG & PLAY</b>");
}
if (!(a<b)){
document.write("<br />a no es < que b");
}
//]]>
</script>Ese script se ejecuta a continuación:
Ejemplo:
La razón de esto era que no podíamos validar en XHTML (como XML) el contenido interior del script debido a que existían caracteres reservados HTML que no podían formar parte de ese contenido. El ampersand "&" sirve para identificar una referencia a un caracter UNICODE, mientras que el signo "<" indentifica el inicio de un elemento HTML. Sin embargo esos caracteres tienen otros cometidos en el código del script cuando no están en un string (no aparecen entrecomillados): el "&" es un operador booleano y el "<" es el operador comparativo "menor que". Por lo tanto los datos podrían incluirse en una sección CDATA que admite cualquier caracter en XML a excepción de la secuencia "]]>" que es la terminación de esa sección CDATA. Por otro lado en HTML-4 también se especifica que los navegadores podían hacer una salvedad con esos dos caracteres dentro de un elemento <script> o <style> [HTML-4.01: SGML basic types], no considerándolos tal como lo hacen cuando los encuentran fuera de esos elementos. Ahora HTML-5 sigue esta regla, por lo que no es necesario hacer ningún escape con secciones CDATA.
Le quitamos las secciones CDATA (y el type="text/javascript") al código anterior:
<script>
var a=true;
var b=true;
if (a && b) {
document.write("<b>PLUG & PLAY</b>");
}
if (!(a<b)){
document.write("<br />a no es < que b");
}
</script>Ejecutándose igualmente que antes tal como se muestra aquí:
Ejemplo:
Entonces podemos usar libremente los caracteres "&", "<" como parte del código JavaScript. Y dado que no tenemos que validar HTML-5 como XHTML, ya no nos hace falta escapar nada. Además hay que decir que HTML-5 sólo permite secciones CDATA para contenido externo (MathML or SVG), por lo que los navegadores no deberían encontrarlos dentro de un <script>.
var c="</script>" por algún motivo. Y es que los navegadores cerrarán el elemento ante cualquier aparición de la secuencia </script> donde quiera que se encuentre, incluso aunque esté en un comentario del código o entrecomillado.Mis preferencias en la sintaxis HTML-5
Después de analizar estos detalles llego a la conclusión de que puedo enviar mis documentos servidos como text/html y escritos con la mayor parte de la sintaxis XHTML. Una razón para esto es que puedo usar aplicaciones de programación que van validando el código HTML mientras escribo. Por lo tanto me facilitará la escritura de marcas si fijo unas reglas de escritura en el validador de la aplicación. Por otro lado uso herramientas que he creado que analizan el documento siguiendo las reglas de sintaxis XML (analizador-xml). Así esa herramienta me sirve a la vez para analizar XML y HTML. Finalmente por una simple cuestión de tener un código claro y legible, es decir, que uno pueda leerlo y entenderlo aunque para ello haga falta poner cosas que podrían omitirse.
Estas son entonces mis preferencias para la sintaxis HTML-5:
- Minúsculas para nombres de elementos y atributos:
<input value=.... Lo que es evidente es que hay que usar una regla en esto y mantener la coherencia. Pues como ya están en minúsculas seguiré con ellas. - Cerrar los elementos vacíos:
<input value=... />. Lo considero necesario para que el código resulte legible. Para los que estamos aprendiendo resulta de gran ayuda ver esa barra y reconocer que ahí acaba el elemento y no tratar de buscar inútilmente el tag de cierre. - Comillas dobles en atributos:
<input value="abc" />. Es más cómodo de leer con comillas dobles en todos los casos. - Atributos booleanos con valor siempre:
<input disabled="disabled" />. HTML-5 no lo aprueba pero a los navegadores les da igual. Lo considero necesario para mayor legibilidad del código. Además me simplifica el análisis de HTML con la herramienta que tengo hecha para eso. - Omitir la menor cantidad de tags posible, especialmente los que cierran elementos:
<p>...</p>. Simplemente por comodidad de lectura. Además se da por supuesto que los de cabecera<html>,<head>y<body>siempre hemos de ponerlos, pues hemos de declarar contenido de meta-información o el lenguaje del documento. Otros como<tbody>se podrían omitir, pero no es mala idea ponerlos para no perder de vista que siempre hay un cuerpo de tabla implícito. - Poner atributos por defecto en el caso de que sirva para aclararme al leer el código:
<input type="text" />. Imagino un formulario con un montón de elementos<input>de diversos tipos. Suelo poner el atributotypecerca del nombre del elemento, como una forma de leer rápidamente el tipo de control. - No escapar código script con secciones CDATA pues no necesitaré validar el documento de forma oficial.
Así mi HTML-5 estará escrito con sintaxis XHTML. Quién sabe si algún día tendré que volver a usarlos o reutilizar ciertas partes como de tipo XHTML. Pero esto no acaba aquí. Seguiré estudiando HTML-5 y es posible que tenga que modificar o ampliar este conjunto de reglas. Pero eso es HTML-5: la capacidad de los navegadores para adaptarse a las diversas sintaxis y la nuestra para también adaptarnos a los cambios.