Isomorfismos: refinamiento
Algoritmo McKay para resolver problema de isomorfismos
El algoritmo de McKay tiene como objetivo obtener un etiquetado canónico de un grafo, etiquetado que es el mismo para todos los grafos que sean isomorfos. Así cuando ese etiquetado en dos grafos coincide entonces serán isomorfos.
En un tema anterior vimos como aplicar fuerza bruta aplicando la operación operatePermuteGraph() para obtener permutaciones del primer grafo hasta alcanzar una cuya matriz de adyacencia fuese igual que la del segundo grafo, en cuyo caso eran isomorfos. Pero hay limitaciones al aplicar fuerza bruta para saber si dos grafos son isomórficos que hace impracticable para grafos con más de 9 nodos. El objetivo entonces de este algoritmo de McKay es solventar esto, pudiendo resolverlo con grafos con muchos más nodos.
Antes de empezar a explicar la implementación que he llevado a cabo del algoritmo de McKay, creo que conviene ver como ese algoritmo mejora la obtención del árbol de particiones donde se localizará el etiquetado canónico del grafo, pues nos dará una idea de los pasos a seguir hasta llegar a una versión definitiva del algoritmo getPartitionTree() que intentamos implementar.
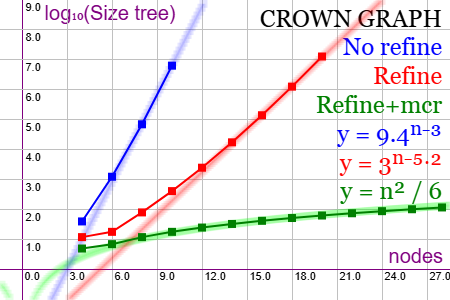
En la Figura vemos el comportamiento del algoritmo de McKay en nuestra aplicación Grafos SVG para el grafo corona para tamaños pares desde 4 a 30 nodos tal como vemos en el eje horizontal. En el eje vertical se presentan los tamaños del árbol de particiones en escala logarítmica, así que los valores "y" de ese eje se corresponden con tamaños 10y nodos del árbol de particiones.
edita-funcion: y = log10(x**2/6); color="rgba(0,255,0,0.1)"; # y = log10(9.4**(x-3)); color="rgba(0,0,255,0.1)"; # y = log10(3**(x-5.2)); color="rgba(255,0,0,0.1)"; # a=[0,4,6,8,10]; b=[0,40,1236,69280,6235300]; x=(i++, a[i]); y=log10(b[i]); color="blue"; # a=[0,4,6,8,10,12,14,16,18,20]; b=[0,12,18,80,410,2472,17318,138560,1247058,12570600]; x=(i++, a[i]); y=log10(b[i]); color="red"; # a=[0,4,6,8,10,12,14,16,18,20,22,24,26,28,30]; b=[0,5,7,12,18,25,33,42,52,63,75,88,102,117,133]; x=(i++, a[i]); y=log10(b[i]); color="green"; _remarcar: 0 _marcar-puntos: 4 _anchoxy: 450 _altoxy: 300 _zoomx: 15 _zoomy: 30 _movex: -13.500 _movey: -4 _usar-colores: 0 _titulo-x: nodes _titulo-y: log₁₀(Size tree) _offset-title-y: -160 _font-size-titulos: 20 _titulo-grafica: CROWN GRAPH No refine Refine Refine+mcr y = 9.4ⁿ⁻³ y = 3ⁿ⁻⁵‧² y = n² / 6 _font-size-titulo-grafica: 24 _colores-titulo-grafica: black,blue,red,green,blue,red,green _contorno: 1
El algoritmo se basa en un recursivo DFS de búsqueda en profundidad y que expusimos en el tema anterior al exponer como generamos el ábol de particiones que recorre todas las permutaciones posibles del grafo inicial, guardando la matriz de adyacencia de las permutaciones que lexicográficamente sea mayores. Esa matriz de adyacencia será entonces el etiquetado canónico (canonical label) del grafo, que nos sirve para comprobar con otro grafo para saber si son isomorfos.
En la Figura la gráfica en azul "No refine" presenta sólo 4 valores, pues con 10 nodos el árbol ya tiene un tamaño de 6235300 ≈ 106.79 nodos. Y con más nodos la aplicación da un error de out of memory
. Vea que el comportamiento es exponencial, incluyendo una estimación y = 9.4n-3 como se observa en la línea recta en azul más claro.
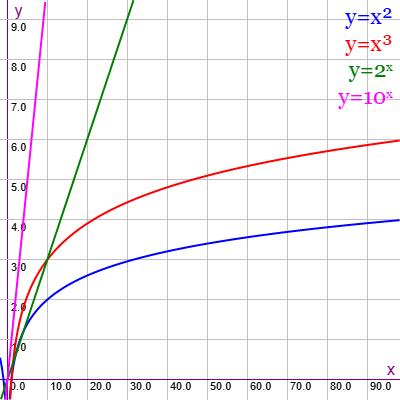
Los comportamientos exponenciales en gráficas logarítmicas se corresponden con líneas rectas con valores muy por encima de las polinómicas y que ascienden muy rápido. Por ejemplo, en la Figura vemos las funciones y = x2, y = x3, y = 2x e y = 10x en representación logarítmica, observando que las dos últimas exponenciales vienen a ser rectas en esa representación, muy por encima de las polinómicas.
El proceso de refinamiento de McKay reduce el caracter exponencial en un factor que depende de las características de cada grafo. Vemos en la Figura la gráfica en color rojo "Refine" donde ahora podemos llegar hasta 20 nodos con un tamaño de 12470600 ≈ 107.1 nodos del árbol de particiones. A partir de ahí la aplicación se queda sin recursos dando el error de out of memory. Se estima la tendencia con y = 3n-5.2 con lo que el refinamiento poda el árbol, pero aún sigue siendo exponencial para ese grafo.
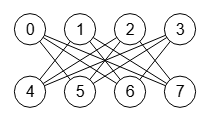
La poda con refinamiento depende de la regularidad del grafo. El grafo corona con 8 nodos de la Figura tiene los siguientes vecinos para cada nodo [[5,6,7],[4,6,7],[4,5,7],[4,5,6],[1,2,3],[0,2,3],[0,1,3],[0,1,2]], que podemos obtener con el algoritmo getNeighbors(). Vemos que cada nodo tiene 3 vecinos, que también podemos comprobar con el algoritmo getVertexDegrees() para obtener los grados de los vértices que son [3,3,3,3,3,3,3,3]. De hecho para un grafo corona con n nodos, todos los vértices tienen grado (n/2)-1. Esta regularidad de los grados de los vértices supone que no se consiga una gran reducción en la poda con sólo refinamiento, pues como veremos en un siguiente apartado con un grafo con 9 nodos y grados [2,5,2,5,4,5,2,5,2] el refinamiento consigue reducir drásticamente el árbol de particiones, pasando de un árbol sin refinamiento con 623530 nodos a un árbol con sólo 13 nodos al usar refinamiento.
Donde en cualquier caso se consigue reducir significativamente el coste es usando la poda con autormorfismos, que denominamos "Refine+mcr". La línea de tendencia es ahora polinómica con una estimación y = n2 / 6 para los nodos del test. Vemos que el último valor para 30 nodos resulta en un tamaño del árbol de sólo 133 ≈ 102.12.

La aplicación devuelve el siguiente resultado para un grafo corona con 200 nodos y 9900 aristas que vemos en la Figura, observando el tamaño del árbol "indexTree":5148 nodos, que responde a un valor polinómico de orden cuadrático para n = 200 nodos pues 5148 ≈ 2002 / 7.8
Time: 1187 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc",
"targetCell":"max-length-first","typeCanon":"edges",
"useMcr":true,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1187,"timeIni":123,"timeRef":468,
"iter":181697,"refine":5149,"indexTree":5148,
"leaves":101,
"prunningMcr":171501,"prunningMcrBreak":0,
...Se observa la poda con automorfismos en el campo "prunningMcr":171501 exponiendo que se hicieron 171501 podas que reducen drásticamente muchísimas ramas del árbol de partitición, poda que, como con la de indicadores, veremos en temas posteriores, pues este tema lo dedicaremos sólo a la poda con refinamiento. Puede importar en la aplicación este ejemplo con el archivo json-crown-graph-200-nodes.txt
Documentos de referencia sobre el problema de isomorfismo de grafos
Hay muchos documentos en Internet para seguir estos temas. La mayor parte son demasiado teóricos, pero sus conceptos y ejemplos con grafos me han venido sirviendo para tratar de implementar este algoritmo de McKay. Relaciono algunos a continuación, donde las claves [Dn] servirán para referenciar estos documentos en este y otros temas y el título en negrita inicial es el nombre del documento en PDF.
- [D1] mckay.pdf: Practical graph isomorphism de Brendan D. McKay, del año 1981, que es el documento original del algoritmo que estamos intentando implementar.
- [D2] practical graph isomorphism 2 (mckay piperno).pdf: Practical graph isomorphism, II, web con un un enlace para descargar en pdf, de Brendan McKay and Adolfo Piperno, del año 2013, de donde he tomado un grafo de ejemplo que veremos en este tema.
- [D3] 2018_K27_report.pdf: Graph isomorphism algorithms in nauty de Fredrik Stenkvist, del año 2018, con grafos de ejemplo muy prácticos.
- [D4] canonical.dvi.pdf: McKay’s Canonical Graph Labeling Algorithm de Stephen G. Hartke and A. J. Radcliffe, del año 2009.
- [D5] Nauty Traces – Introduction.pdf: Nauty and Traces: Practical Graph Isomorphism en una web, de Brendan McKay and Adolfo Piperno, de la versión más reciente 2.9.3 con fecha 01/01/2026 de la aplicación Nauty and Traces que implementa el algoritmo de McKay.
- [D6] nug29.pdf: La guia de usuario completa puede descargarse en nauty and Traces User’s Guide (Version 2.9.3), con fecha 31/12/2025
- [D7] slides-brendan-mckay-lecture-mons.pdf: 55 Years of Graph Isomorphism Testing de Brendan McKay, probablemente del año 2018. Una presentación que resume el problema con ejemplos y conceptos.
- [D8] vol-064-paper 18.pdf: Attacks on Hard Instances of Graph Isomorphism de Greg Tener and Narsingh Deo, año 2008.
- [D9] ComputingIsomorphism.pdf: Computing Isomorphism de Lucia Moura, año 2009.
- [D10] Efficient_isomorphism of_Miyazaki_graphs.pdf: Efficient Isomorphism of Miyazaki Graphs de Greg Tener and Narsingh Deo, del año 2011.
- [D11] conauto.pdf: Efficient Algorithms for Graph Isomorphism Testing, con la aplicación Conauto 2.0, de José Luís López Presa, año 2009. Y también Use of Automorphisms in Conauto-2.0 de Luis Felipe Núñez Chiroque, año 2011.
Refinamiento en el algoritmo de McKay
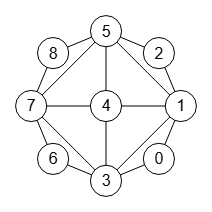
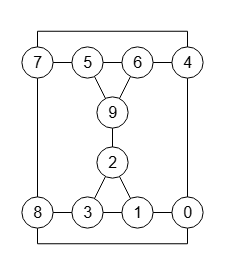
En la Figura vemos un grafo que nos servirá para explicar el proceso de refinamiento. Puede ver el JSON en graph-sample-2.txt para importar en la aplicación. Lo he tomado del documento [D2] y que también se expone en [D5].
Ejecutando getPartitionTree() para obtener el árbol de particiones, nos devuelve el siguiente resultado usando la traza, activando usar refinamiento ("useRefine":true) y no activando otras podas ("useMcr":false, "typeIndicator":"none").
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":false,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":17,"refine":13,"indexTree":12,
"leaves":8,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanon":true,
"canonicalPartition":[[1],[3],[5],[7],[0],[2],[6],[8],[4]],
"firstCanonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[],[]],[0,[],[]],[0,[],[]],[0,[],[]]],
[[0,[],[],"f*"],[0,[],[],"=(0 2)(3 5)(6 8)"],[1,[],[],"=(1 3)(2 6)(5 7)"],[1,[],[],"=(0 6 8 2)(1 3 7 5)"],[2,[],[],"=(0 2 8 6)(1 5 7 3)"],[2,[],[],"=(0 8)(1 5)(3 7)"],[3,[],[],"=(0 6)(1 7)(2 8)"],[3,[],[],"=(0 8)(1 7)(2 6)(3 5)"]]],
"nodeBest":[2,0],
"mcr":null,
"fixMcr":null,
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":0,
"tree":[{"index":0,"value":"(1 3 5 7)(0 2 6 8)(4)","parent":-1},
{"index":1,"value":"(1)(3 5)(7)(0 2)(6 8)(4)","parent":[{"index":0,"value":1}]},
{"index":2,"value":"(1)(3)(5)(7)(0)(2)(6)(8)(4)","parent":[{"index":1,"value":3}]},
{"index":3,"value":"(1)(5)(3)(7)(2)(0)(8)(6)(4)","parent":[{"index":1,"value":5}]},
{"index":4,"value":"(3)(1 7)(5)(0 6)(2 8)(4)","parent":[{"index":0,"value":3}]},
{"index":5,"value":"(3)(1)(7)(5)(0)(6)(2)(8)(4)","parent":[{"index":4,"value":1}]},
{"index":6,"value":"(3)(7)(1)(5)(6)(0)(8)(2)(4)","parent":[{"index":4,"value":7}]},
{"index":7,"value":"(5)(1 7)(3)(2 8)(0 6)(4)","parent":[{"index":0,"value":5}]},
{"index":8,"value":"(5)(1)(7)(3)(2)(8)(0)(6)(4)","parent":[{"index":7,"value":1}]},
{"index":9,"value":"(5)(7)(1)(3)(8)(2)(6)(0)(4)","parent":[{"index":7,"value":7}]},
{"index":10,"value":"(7)(3 5)(1)(6 8)(0 2)(4)","parent":[{"index":0,"value":7}]},
{"index":11,"value":"(7)(3)(5)(1)(6)(8)(0)(2)(4)","parent":[{"index":10,"value":3}]},
{"index":12,"value":"(7)(5)(3)(1)(8)(6)(2)(0)(4)","parent":[{"index":10,"value":5}]}],
"automorphisms":
[[[0,2],[1],[3,5],[4],[6,8],[7]],
[[0],[1,3],[2,6],[4],[5,7],[8]],
[[0,6,8,2],[1,3,7,5],[4]],
[[0,2,8,6],[1,5,7,3],[4]],
[[0,8],[1,5],[2],[3,7],[4],[6]],
[[0,6],[1,7],[2,8],[3],[4],[5]],
[[0,8],[1,7],[2,6],[3,5],[4]]],
"automorphismsPlus":0}Sin refinamiento el árbol de particiones tendrá 8! = 362880 hojas y un total de 623530 nodos, necesitando 884179 iteraciones y 5133 ms para completarlo y obtener el etiquetado canónico. Con refinamiento vemos que solo necesita 8 hojas, 13 nodos, 17 iteraciones y 1 ms para obtener el canónico. Recordar que "indexTree":12 es el último índice del nodo agregado al árbol y como empiezan desde cero entonces el árbol tiene 13 nodos. Ese árbol que se obtiene al activar la traza es el siguiente:

Puede importar el árbol anterior en la aplicación con partition-tree-sample-2.txt. El árbol anterior con refinamiento es exactamente igual que el que vemos en los documentos de referencia [D2] y [D5] de McKay y Piperno que indicamos antes.
Veamos ahora el refinamiento inicial. Para empezar a refinar primero buscamos los vecinos de los nodos del grafo con getNeighbors():
[[1,3],[0,2,3,4,5],[1,5],[0,1,4,6,7],[1,3,5,7],[1,2,4,7,8],[3,7],[3,4,5,6,8],[5,7]]
Cada subarray anterior son los vértices vecinos de cada índice de vértice. Agrupamos por tamaño de vecinos, es decir, por grados:
0 1 2 3 4 5 6 7 8 [[1,3],[0,2,3,4,5],[1,5],[0,1,4,6,7],[1,3,5,7],[1,2,4,7,8],[3,7],[3,4,5,6,8],[5,7]] Agrupando índices por tamaños de vecinos: Grado 5: [1,3,5,7] Grado 4: [4] Grado 2: [0,2,6,8]
Así que la primera partición será [[1,3,5,7], [0,2,6,8], [4]] ordenando las celdas por grados y longitudes descendentes, lo que se corresponde con la opción "orderRefine":"neighbors-desc-lengths-desc" que se aplica al generar el árbol. Esta partición inicial se ubica en el nodo raíz del árbol de la Figura.
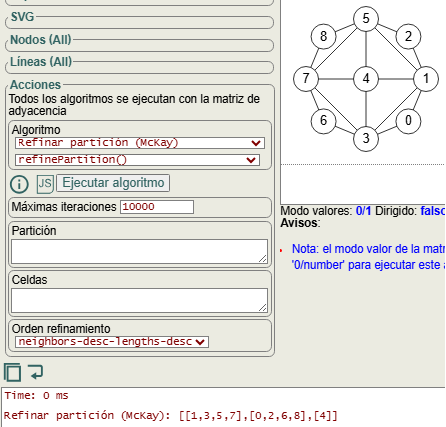
Aparte del algoritmo getPartitionTree() para obtener el árbol de particiones, la aplicación contempla ejecutar sólo refinePartition() para refinar una partición del grafo, algoritmo que expondremos más abajo. En la Figura vemos que usamos el mismo grafo de ejemplo y refinamos con los campos partición y celdas vacío en este caso para que genere la partición inicial, usando además el orden "neighbors-desc-lengths-desc", obteniéndose la primera partición [[1,3,5,7], [0,2,6,8], [4]]
El siguiente paso es seleccionar la celda objetivo entre todas las celdas con más de un elemento de la partición, usando el criterio "targetCell":"max-length-first" con lo que la seleccionada será [1,3,5,7] pues es la primera de máxima longitud.
Ahora seleccionamos el vértice 1 pues es el elemento mínimo de la celda [1,3,5,7] y procedemos a fijar ese vértice 1 en la partición, quedando [[1], [3,5,7], [0,2,6,8], [4]] pues simplemente extraemos 1 de la celda objetivo y lo ubicamos en la celda previa [1] con sólo ese vértice. En una partición las celdas unitarias o triviales son vértices fijados, pues el objetivo es llegar a una partición hoja (o partición discreta) donde todas las celdas son de tamaño unitario o triviales.
El paso siguiente a fijar un vértice en la partición no discreta es refinarla. Pero en algunos casos al fijar el vértice ya la partición se convierte en discreta, con lo cual no es necesario refinarla, pues una partición discreta ya no se puede refinar más. Vea un ejemplo en un siguiente apartado.
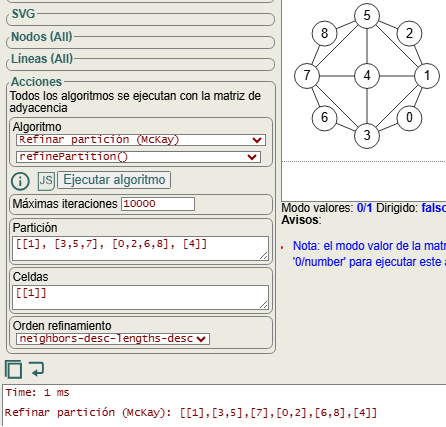
El siguiente paso es refinar esa partición [[1], [3,5,7], [0,2,6,8], [4]] mediante la celda fijada [[1]], observando en la Figura que se obtiene la nueva partición [[1],[3,5],[7],[0,2],[6,8],[4]] que fija el vértice 7, observando ese nodo a la izquierda del segundo nivel del árbol de la Figura.
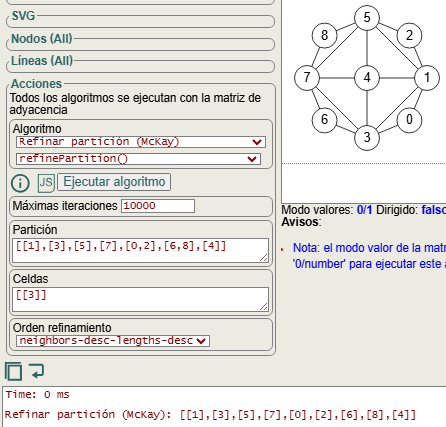
Al volver recursivamente con la nueva partición [[1],[3,5],[7],[0,2],[6,8],[4]] seleccionamos la celda objetivo [3,5], fijamos el menor vértice 3 quedando la partición [[1],[3],[5],[7],[0,2],[6,8],[4]], refinándola con la celda fijada [[3]], con lo que finalmente obtendremos la primera hoja del árbol [[1],[3],[5],[7],[0],[2],[6],[8],[4]], donde todas las celdas son unitarias y se corresponde con el nodo de la izquierda en el tercer nivel del árbol de la Figura.
El proceso continuará de forma recursiva iterando por los vértices de cada celda seleccionada, obteniéndose al final las 8 hojas del árbol de la Figura.
Refinamiento, particiones equitables y particiones ordenadas
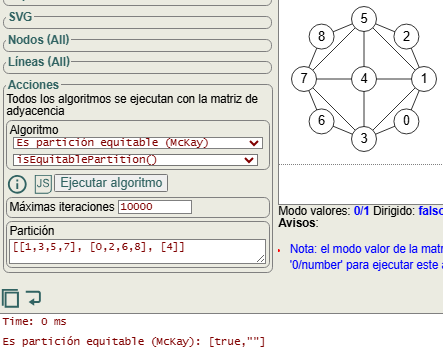
Para entender como funciona el algoritmo de refinamiento es necesario entender el concepto de partición equitable. La partición inicial que obteníamos en el apartado anterior era [[1,3,5,7], [0,2,6,8], [4]].
Usando el algoritmo isEquitablePartition() en la aplicación vemos en la Figura que devuelve [true, ""] con lo que se verifica que lo es.
Una partición (..., ci, ..., cj, ...), donde ck son sus celdas, es equitable con respecto a un grafo si para cada pareja de celdas ci, cj con i=j ∨ i≠j sucede que si v1, v2 son dos vértices de cj entonces deg(v1, ci) = deg(v2, ci) donde deg(v, c) es el número de vecinos del vértice v en la celda c.
Si dividimos manualmente la primera celda en dos [[1,3], [5,7], [0,2,6,8], [4]] podemos comprobar que esa partición no es equitable, devolviendo isEquitablePartition() el siguiente resultado:
Es partición equitable (McKay): [false, "Vj=[0,2,6,8], v1=0, v2=2, Vi=[1,3], neighbors(v1)=[1,3], neighbors(v2)=[1]"]
Si tomamos los vértices v1=0, v2=2 de la celda c1 = [0,2,6,8] y otra celda c2 = [1,3] vemos que en el grafo el vértice v1=0 tiene 2 vecinos que coincide con c2 = [1,3] mientras que el vértice v2=2 tiene los vecinos [1,5] de los cuáles un único vecino [1] está en la celda c2 = [1,3]. Si fuera c2 = [1,3,5,7] entonces tanto los vecinos de 0 como los de 2 estarían en esa celda y sería equitable.
Una partición discreta siempre será equitable, por lo que es posible (aunque poco usual) que depués de fijar un vértice obtengamos una partición discreta, con lo que no sería necesaria refinarla más pues no puede ser más fina. Vea un ejemplo en otro apartado.
El refinamiento inicial puede producir una partición no equitable, algo que solucionamos con el algoritmo forceEquitablePartition() que veremos más abajo. Pero a partir de tener la primera partición ya equitable, el proceso de fijar vértices y refinar siempre produce particiones equitables.
Por ejemplo, cuando fijábamos el primer vértice 1 del apartado anterior teníamos la partición inicial [[1,3,5,7], [0,2,6,8], [4]] y a continuación separábamos ese vértice 1 quedando la partición [[1], [3,5,7], [0,2,6,8], [4]]. Puede comprobar que NO es equitable con el algoritmo isEquitablePartition(), pues devuelve lo siguiente:
Es partición equitable (McKay): [false, "Vj=[3,5,7], v1=3, v2=7, Vi=[3,5,7], neighbors(v1)=[7], neighbors(v2)=[3,5]"]
Así que fijar un vértice hace que la partición resultante no sea equitable. Y es por eso que inmediatamente a continuación aplicamos el algoritmo de refinamiento para obtener la nueva partición [[1],[3,5],[7],[0,2],[6,8],[4]], que ahora si es equitable, lo que podemos comprobar con isEquitablePartition().
El siguiente paso es entender el concepto de particiones ordenadas. En la documentación se definen los siguientes conceptos
- Una partición es un conjunto de subconjuntos no vacíos disjuntos de los vértices del grafo, algo como π = {c0, ..., cr}, donde cada ci = {v0, ..., vk} es un subconjunto de vértices del grafo.
- Una partición ordenada es la lista de subconjuntos de una determinada partición, así que la partición ordenada es la lista π = (c0, ..., cr) con los mismos subconjuntos de la partición anterior, donde usamos paréntesis en lugar de llaves, observando que la diferencia está en que esta lista tiene un orden en las celdas mientras que en el conjunto con llaves no hay orden en sus celdas.
- Cada subconjunto ci de una partición se denomina celda de la partición. Como subconjunto también es un conjunto, así que el orden de sus vértices no es importante, pero en la aplicación normalizamos su presentación con un orden ascendente de los vértices. Es importante entender que el orden de las celdas en la partición ordenada si es importante, pues es una lista de celdas. Pero los vértices dentro de una celda conforman un (sub)conjunto de vértices con lo que su orden no importa.
- Una celda es trivial si tiene un único elemento y se dice que ese elemento es fijado por la partición a la que pertenece.
- Una partición es discreta si todas sus celdas son triviales. Es lo que denominábamos particiones hojas pues se generan en las hojas del árbol de particiones.Hay que aclarar que con poda con indicadores pueden producirse hojas en el árbol que no son particiones discretas, como veremos en un ejemplo en un tema posterior.
- La partición unitaria es la que tiene una única celda. Suele producirse al generar el refinamiento inicial en un grafo con el mismo grado en todos sus vértices.
Al ordenarse las particiones definimos un orden entre todas las particiones que se pueden generar. Así si π1 y π2 son dos particiones ordenadas
- Decimos que son iguales π1 ≃ π2 si ambas tienen las mismas celdas.
- Decimos que π1 es más fina que π2, que expresamos como π1 ≤ π2, si cada celda de π1 es un subconjunto de alguna celda de π2. De forma opuesta podríamos decir que π2 es más gruesa que π1 que expresamos como π2 > π1
Como ejemplo vemos la rama de la izquierda del árbol de particiones de la Figura, que explicamos su generación en el apartado anterior, realizando el refinamiento inicial, fijando vértices 1 y 3 y refinando, con lo que tenemos esa primera rama con estas 3 particiones:
π1 = [[1,3,5,7], [0,2,6,8], [4]] π2 = [[1],[3,5],[7],[0,2],[6,8],[4]] π3 = [[1],[3],[5],[7],[0],[2],[6],[8],[4]]
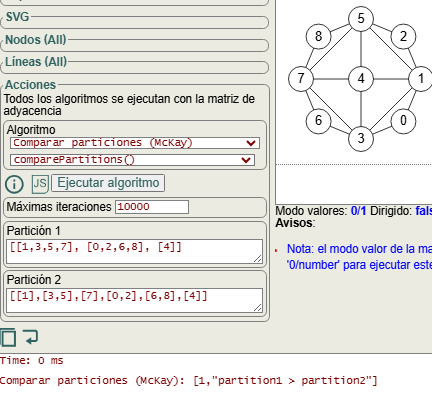
En la aplicación disponemos del algoritmo comparePartitions(), algoritmo que realmente no interviene en getPartitionTree() para obtener el árbol de particiones, pero que sirve para ir entendiendo todo esto.
Vemos en la Figura como π1 > π2. Y si comparamos las dos últimas veremos que π2 > π3. Entonces π1 es más gruesa que π2 y a su vez esta es más gruesa que π3.
O si con ese algoritmo las comparamos al revés veremos que π3 ≤ π2 y π2 ≤ π1, con lo que π3 es más fina que π2 y esta a su vez es más fina que π1. Entonces el camino que va desde el nodo raíz del árbol de particiones hasta una hoja es tal que cada partición que se genera siempre es más fina que la anterior, lo que se garantiza con el algoritmo refinePartition(). Cada vez que refinamos una partición la hacemos más fina. Y este refinamiento consecutivo garantiza que siempre llegaremos a una partición discreta en una hoja al final de cada rama, hojas que serán distintas pues habremos ido seleccionando celdas objetivos y vértices en cada celda de forma iterada en cada paso.
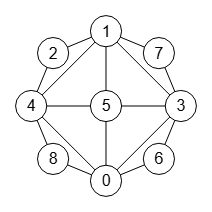
En la Figura vemos el grafo de la permutación 3, 5, 8, 1, 7, 4, 0, 2, 6 que hemos aplicado aleatoriamente al grafo de la Figura, permutación que obtenemos con la operación operatePermuteGraph(). Le aplicamos posicionamiento para ubicar los nodos equivalentemente con los permutados de la Figura, posicionamiento que ya explicamos en el tema anterior. Obtendremos el mismo etiquetado canónico que resaltamos en la traza que vemos más abajo obtenida con el algoritmo getPartitionTree() y el que veíamos en la traza del grafo de la Figura.
Y eso es porque si tenemos el grafo G de la Figura y el grafo H de la Figura que es una permutación γ del anterior y que expresamos como H = Gγ, entonces se cumple que los árboles de particiones son iguales bajo esa permutación, es decir, Tree(H) = Tree(G)γ. Observe en las trazas de los dos grafos que ambos tiene un tamaño de 13 nodos. Esta es la traza del árbol de particiones del grafo permutado de la Figura.
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":false,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":3,"timeIni":1,"timeRef":1,
"iter":17,"refine":13,"indexTree":12,
"leaves":8,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[3],[4],[1],[6],[8],[7],[2],[5]],
"firstCanon":true,
"canonicalPartition":[[0],[3],[4],[1],[6],[8],[7],[2],[5]],
"firstCanonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalLabel":[[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[],[]],[0,[],[]],[0,[],[]],[0,[],[]]],
[[0,[],[],"f*"],[0,[],[],"=(2 7)(3 4)(6 8)"],[1,[],[],"=(0 1)(2 8)(6 7)"],[1,[],[],"=(0 1)(2 6)(3 4)(7 8)"],[2,[],[],"=(0 3)(1 4)(7 8)"],[2,[],[],"=(0 3 1 4)(2 8 6 7)"],[3,[],[],"=(0 4 1 3)(2 7 6 8)"],[3,[],[],"=(0 4)(1 3)(2 6)"]]],
"nodeBest":[2,0],
"mcr":null,
"fixMcr":null,
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":0,
"tree":[{"index":0,"value":"(0 1 3 4)(2 6 7 8)(5)","parent":-1},
{"index":1,"value":"(0)(3 4)(1)(6 8)(2 7)(5)","parent":[{"index":0,"value":0}]},
{"index":2,"value":"(0)(3)(4)(1)(6)(8)(7)(2)(5)","parent":[{"index":1,"value":3}]},
{"index":3,"value":"(0)(4)(3)(1)(8)(6)(2)(7)(5)","parent":[{"index":1,"value":4}]},
{"index":4,"value":"(1)(3 4)(0)(2 7)(6 8)(5)","parent":[{"index":0,"value":1}]},
{"index":5,"value":"(1)(3)(4)(0)(7)(2)(6)(8)(5)","parent":[{"index":4,"value":3}]},
{"index":6,"value":"(1)(4)(3)(0)(2)(7)(8)(6)(5)","parent":[{"index":4,"value":4}]},
{"index":7,"value":"(3)(0 1)(4)(6 7)(2 8)(5)","parent":[{"index":0,"value":3}]},
{"index":8,"value":"(3)(0)(1)(4)(6)(7)(8)(2)(5)","parent":[{"index":7,"value":0}]},
{"index":9,"value":"(3)(1)(0)(4)(7)(6)(2)(8)(5)","parent":[{"index":7,"value":1}]},
{"index":10,"value":"(4)(0 1)(3)(2 8)(6 7)(5)","parent":[{"index":0,"value":4}]},
{"index":11,"value":"(4)(0)(1)(3)(8)(2)(6)(7)(5)","parent":[{"index":10,"value":0}]},
{"index":12,"value":"(4)(1)(0)(3)(2)(8)(7)(6)(5)","parent":[{"index":10,"value":1}]}],
"automorphisms":
[[[0],[1],[2,7],[3,4],[5],[6,8]],
[[0,1],[2,8],[3],[4],[5],[6,7]],
[[0,1],[2,6],[3,4],[5],[7,8]],
[[0,3],[1,4],[2],[5],[6],[7,8]],
[[0,3,1,4],[2,8,6,7],[5]],
[[0,4,1,3],[2,7,6,8],[5]],
[[0,4],[1,3],[2,6],[5],[7],[8]]],
"automorphismsPlus":0}El proceso de refinamiento de particiones equitables respeta la acción de la permutación γ, pues para una partición π tras lo cual fijamos el vertice v y luego procedemos a refinar, dos operaciones que podemos llamar fixRefine(π, v) entonces sucede que
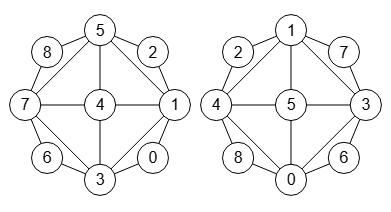
Para comprobar esto tomaremos el grafo G inicial de la Figura y el grafo permutación H de la Figura que agrupamos en una única imagen en la Figura.
Obtuvimos el grafo H aplicando la permutación 3,5,8,1,7,4,0,2,6 como vimos más arriba. En el árbol de particiones del grafo G el nodo raíz del árbol de particiones era (1 3 5 7)(0 2 6 8)(4). Si aplicamos esa permutación a los vértices de esa primera partición obtendremos el nodo raíz del grafo H que era (0 1 3 4)(6 7 8 2)(5):
Vértices G: 0 1 2 3 4 5 6 7 8 Permutación H: 3 5 8 1 7 4 0 2 6 (1 3 5 7)(0 2 6 8)(4) (3 0 1 4)(6 7 8 2)(5) = (0 1 3 4)(2 6 7 8)(5)
Para aplicar la permutación enfrentamos los vértices de G a los índices de la permutación de H. Entonces iteramos por los vértices de la partición (1 3 5 7)(0 2 6 8)(4) del árbol de G buscando ese índice en permutación H y obtenemos el índice en vértices G, con lo que obtenemos (3 0 1 4)(6 7 8 2)(5). Tal como explicamos más arriba, dado que las celdas son conjuntos, en la aplicación ordenamos sus vértices numéricamente para normalizar su presentación, con lo que esa primera partición será computada como (0 1 3 4)(2 6 7 8)(5)
Buscamos ahora la partición con índice 1 ("index":1) del árbol de particiones de G y vemos que al aplicar la permutación tal como hicimos antes obtenemos la partición con índice 7 ("index":7) del árbol de particiones de H:
Árbol G Index: 1 Partition: (1)(3 5)(7)(0 2)(6 8)(4) Árbol H Index: 7 Partition: (3)(0 1)(4)(6 7)(8 2)(5)
A continuación hacemos lo mismo para todo el árbol G obteniendo las particiones del árbol H:
Árbol G Árbol H ---------------------------------------------------------------------------------- 0 (1 3 5 7)(0 2 6 8)(4) 0 (3 0 1 4)(6 7 8 2)(5) = (0 1 3 4)(2 6 7 8)(5) 1 (1)(3 5)(7)(0 2)(6 8)(4) 7 (3)(0 1)(4)(6 7)(8 2)(5) 2* (1)(3)(5)(7)(0)(2)(6)(8)(4) 8 (3)(0)(1)(4)(6)(7)(8)(2)(5) 3 (1)(5)(3)(7)(2)(0)(8)(6)(4) 9 (3)(1)(0)(4)(7)(6)(2)(8)(5) 4 (3)(1 7)(5)(0 6)(2 8)(4) 1 (0)(3 4)(1)(6 8)(7 2)(5) 5 (3)(1)(7)(5)(0)(6)(2)(8)(4) 2* (0)(3)(4)(1)(6)(8)(7)(2)(5) 6 (3)(7)(1)(5)(6)(0)(8)(2)(4) 3 (0)(4)(3)(1)(8)(6)(2)(7)(5) 7 (5)(1 7)(3)(2 8)(0 6)(4) 4 (1)(3 4)(0)(7 2)(6 8)(5) = (1)(3 4)(0)(2 7)(6 8)(5 8 (5)(1)(7)(3)(2)(8)(0)(6)(4) 5 (1)(3)(4)(0)(7)(2)(6)(8)(5) 9 (5)(7)(1)(3)(8)(2)(6)(0)(4) 6 (1)(4)(3)(0)(2)(7)(8)(6)(5) 10 (7)(3 5)(1)(6 8)(0 2)(4) 10 (4)(0 1)(3)(8 2)(6 7)(5) = (4)(0 1)(3)(2 8)(6 7)(5) 11 (7)(3)(5)(1)(6)(8)(0)(2)(4) 11 (4)(0)(1)(3)(8)(2)(6)(7)(5) 12 (7)(5)(3)(1)(8)(6)(2)(0)(4) 12 (4)(1)(0)(3)(2)(8)(7)(6)(5)
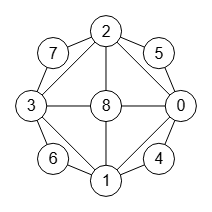
Ambos árboles encuentran el grafo canónico en la partición con "index":2 y para ambos es el mismo etiquetado canónico "canonicalLabel": [[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]], cuyo grafo canónico se representa en la Figura. Ese grafo es el canónico para todas las permutaciones del grafo inicial. Sin embargo las particiones canónicas ("canonicalPartition") de ambos grafos son distintas:
Partición canónica G: (1)(3)(5)(7)(0)(2)(6)(8)(4) permutación: 1,3,5,7,0,2,6,8,4 Partición canónica H: (0)(3)(4)(1)(6)(8)(7)(2)(5) permutación: 0,3,4,1,6,8,7,2,5
Si al grafo G le aplicamos la permutación 1,3,5,7,0,2,6,8,4 de su partición canónica obtendremos la misma lista de aristas anterior del etiquetado canónico que si aplicamos la permutación 0,3,4,1,6,8,7,2,5 de la partición canónica al grafo H.
Código JavaScript para ejecutar el DFS básico del etiquetado canónico con refinamiento
Esta es una versión básica para generar el árbol de particiones y obtener el etiquetado canónico sólo con uso de refinamiento de particiones, versión previa a la definitiva getPartitionTree() que expondremos en otro tema.
El siguiente pseudocógido resume esta versión básica del algoritmo, donde el resultado es simplemente result = {canonicalLabel:null}
Function getPartitionTreeRefine(matrix, partition, result)
If partition.length===0 // INITIAL STEPS
partition = Initial refinement
Add first root node to nodes
Apply order refine
End If
if (partition.length===n) // DISCRETE PARTITION (after initial refinement)
canon = get canon with this permutation
result.canonicalLabel = canon
Else
cell = Select target cell
While cell.size>0
// Fix vertex
vertex = minimum of cell
indexCell = position of vertex in cell
delete vertex in cell
partition = individualize vertex and refine partition
Add new node with this fixed path to result.nodes
If partition.length===n // DISCRETE PARTITION
canon = get canon with this permutation
If result.canonicalLabel===null
result.canonicalLabel = canon
Else
// Compare canon
If canon > result.canonicalLabel
result.canonicalLabel = canon
result.lastEqual = false
End If
End If
Else
getPartitionTreeRefine(matrix, partition, result)
End If
End While
End If
return result
End FunctionPuede copiar las 4 funciones que exponemos a continuación (getCanon(), getPartitionTreeRefine(), refinePartition() y runGetPartitionTreeRefine()) o descargarlas en el enlace get-partition-tree-refine.txt y pegarlo en la consola del navegador para ejecutarlo.
Tenemos una función auxiliar getCanon() que ya vimos en el tema anterior para obtener el etiquetado canónico a partir de una partición discreta.
// Algorithm for get canonical label
function getCanon({matrix=[], edgesGraph=[], partition=[]}) {
let canon = [];
try {
let indexes = partition.map(v => v[0]);
let edges = edgesGraph.length>0 ? edgesGraph : matrix.edges;
for (let edge of edges) {
let [v, w] = edge;
let [i, j] = [indexes.indexOf(v), indexes.indexOf(w)];
canon.push(i<j ? [i, j] : [j, i]);
}
canon = canon.map(v => v[0]>v[1] ? [v[1],v[0]] : [v[0],v[1]]).toSorted((v,w) => (v[0]===w[0]) ? v[1]-w[1] : v[0]-w[0]);
} catch(e){canon = e.message}
return canon;
}Y este es el algoritmo para obtener el árbol de particiones:
// Algorithm with the sole purpose of showing how to generate the partition tree with a
// recursive DFS including refinement process. Not included in application.
// Copy and run in the browser console.
function getPartitionTreeRefine({matrix=[], n=0, partition=[], result={canonicalLabel:null}}) {
try {
let n = matrix.length;
if (partition.length===0) {
// Initial refinement
for (let index=0; index<n; index++) {
let num = matrix.neighbors[index].length;
let j = partition.findIndex(v => v.num===num);
if (j===-1) {
j = partition.length;
let arr = [];
arr.num = num;
partition.push(arr);
}
partition[j].push(index);
}
// orderRefine (neighbors-desc-length-desc)
partition.sort((v,w) => v.length===w.length ? w.num-v.num : w.length-v.length);
}
if (partition.length===n) { // DISCRETE PARTITION (after initial refinement)
// Get canon with this permutation;
if (temp = getCanon({matrix, partition}), typeof temp==="string") throw new Error(temp);
result.canonicalLabel = temp;
} else {
// Select target cell (max-length-first)
let parts = partition.map((v,i) => [i, v]).filter(v => v[1].length>1);
let [iMax, len] = [-1, 0];
for (let j=0; j<parts.length; j++) {
let [i,v] = parts[j];
let vl = v.length;
if (vl>len) [iMax, len] = [i, vl];
}
let index = iMax;
if (index>-1) {
let cell = partition[index];
let sCell = new Set(cell);
while (sCell.size>0) {
// Fix vertex
let vertex = Math.min(...sCell);
let indexCell = cell.indexOf(vertex);
sCell.delete(vertex);
let part = partition.map(v => v.slice(0));
part[index] = cell.toSpliced(indexCell, 1);
part = part.toSpliced(index, 0, [vertex]);
// Refine partition
if (part.length<n) {
let cells = [[vertex]];
part = refinePartition({matrix, partition:part, cells});
if (typeof part==="string") throw new Error(part);
}
if (part.length===n) { // DISCRETE PARTITION
// Get canon with this permutation
if (temp = getCanon({matrix, partition:part}), typeof temp==="string") throw new Error(temp);
let canon = temp;
if (result.canonicalLabel===null) {
result.canonicalLabel = canon;
} else {
// Compare canon
for (let i=0; i<canon.length; i++) {
if (canon[i]<result.canonicalLabel[i]) {
result.canonicalLabel = canon;
break;
}
}
}
} else {
let res = getPartitionTreeRefine({matrix, partition:part, result});
if (typeof res==="string") throw new Error(res);
}
}
}
}
} catch(e){result = "getPartitionTreeRefine(): " + e.message}
return result;
}El algoritmo anterior es básicamente el mismo que vimos en el tema anterior, remitiéndonos a lo explicado allí sobre su funcionamiento como uno de búsqueda en profundidad (DFS), pues sólo comentaremos lo modificado para el refinamiento.
Ahora usamos la matriz de adyacencia del grafo como argumento matrix, cuando en la versión del tema anterior usábamos la lista de aristas. El problema es que al refinar debemos tener acceso a la lista de aristas edges así como a la lista de vecinos de cada vértice neighbors. Dotamos a la matriz con estos datos, como vemos en esta función que ejecuta el algoritmo anterior para obtener el árbol de particiones con refinamiento para el ejemplo que hemos visto en este tema:
function runGetPartitionTreeRefine() {
let matrix = [[0,1,0,1,0,0,0,0,0],[1,0,1,1,1,1,0,0,0],[0,1,0,0,0,1,0,0,0],[1,1,0,0,1,0,1,1,0],[0,1,0,1,0,1,0,1,0],[0,1,1,0,1,0,0,1,1],[0,0,0,1,0,0,0,1,0],[0,0,0,1,1,1,1,0,1],[0,0,0,0,0,1,0,1,0]];
matrix.edges = [[0,1],[0,3],[1,2],[1,3],[1,4],[1,5],[2,5],[3,4],[3,6],[3,7],[4,5],[4,7],[5,7],[5,8],[6,7],[7,8]];
matrix.neighbors = [[1,3],[0,2,3,4,5],[1,5],[0,1,4,6,7],[1,3,5,7],[1,2,4,7,8],[3,7],[3,4,5,6,8],[5,7]];
return getPartitionTreeRefine({matrix});
}
//The result should be: {"canonicalLabel": [[0,1],[0,2],[0,4],[0,5],[0,8],[1,3],[1,4],[1,6],[1,8],[2,3],[2,5],[2,7],[2,8],[3,6],[3,7],[3,8]]}
// console.log(JSON.stringify(runGetPartitionTreeRefine()));Aunque en este ejemplo guardamos manualmente matrix.edges y matrix.neighbors, en la versión definitiva de getPartitionTree() lo haremos con los algoritmos getEdges() y getNeighbors.
Siguiendo con el algoritmo para obtener el árbol, inicialmente el argumento partition tendrá longitud cero, así que procedemos al refinamiento inicial (Initial refinement). Se trata de iterar por los vértices del grafo y obtener el número de vecinos (num) desde matrix.neighbors e ir componiendo celdas para cada uno de esos números num, que no es otra cosa que el grado de los vértices, pues vamos a agrupar los vértices en celdas con el mismo grado, tal como explicamos más arriba. Así en el ejemplo obteníamos las celdas [1,3,5,7] de grado 5, [4] de grado 4 y [0,2,6,8] de grado 2.
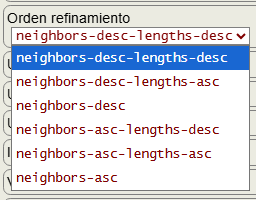
La partición debe ser ordenada en lo que respecta a sus celdas, lo que hacemos en la parte comentada con orderRefine (neighbors-desc-length-desc). En este algoritmo demostrativo ordenamos por grados y longitudes descendentes dando lugar a [[1,3,5,7], [0,2,6,8], [4]], pero en el algoritmo definitivo getPartitionTree() disponemos de la opción orden refinamiento que establece el argumento orderRefine con distintos ordenamientos, entre los que está ese que denominamos neighbors-desc-length-desc y también otros como se observa en la Figura.
El orden refinamiento afecta a las permutaciones que se alcanzan en las hojas del árbol y, por tanto, al etiquetado canónico. En la siguiente tabla vemos los 6 posibles ordenamientos con el nodo raíz y la primera hoja del árbol que se obtiene:
| Orden refinamiento | Nodo raíz | Primera hoja |
|---|---|---|
| neighbors-desc-lengths-desc | (1 3 5 7)(0 2 6 8)(4) | (1)(3)(5)(7)(0)(2)(6)(8)(4) |
| neighbors-desc-lengths-asc | (4)(1 3 5 7)(0 2 6 8) | (4)(1)(7)(3)(5)(0)(2)(6)(8) |
| neighbors-desc | (1 3 5 7)(4)(0 2 6 8) | (1)(3)(5)(7)(4)(0)(2)(6)(8) |
| neighbors-asc-lengths-desc | (0 2 6 8)(1 3 5 7)(4) | (0)(2)(6)(8)(7)(5)(3)(1)(4) |
| neighbors-asc-lengths-asc | (4)(0 2 6 8)(1 3 5 7) | (4)(0)(8)(2)(6)(7)(5)(3)(1) |
| neighbors-asc | (0 2 6 8)(4)(1 3 5 7) | (0)(8)(2)(6)(4)(7)(5)(3)(1) |
En cualquier caso para saber si dos grafos son isomorfos obtenemos el etiquetado canónico en ambos grafos usando siempre las mismas opciones en ambos.
Después del refinamiento inicial puede producirse una hoja, con lo que consultamos si partition.length===n, que siéndolo entonces no entramos en el recursivo y esa hoja será la del etiquetado canónico del grafo finalizándose el algoritmo, como veremos en un ejemplo más abajo.
{kind=link}
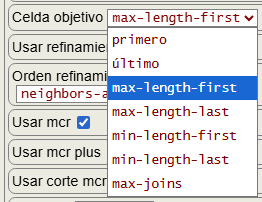
El siguiente paso del algoritmo es seleccionar la celda objetivo que vemos comentado con Select target cell (max-length-first). En el algoritmo definitivo getPartitionTree() también disponemos de varias opciones, como vemos en la Figura. Esta opción tiene efecto cuando usemos la poda con automorfismos (useMcr) que veremos en un siguiente tema, pues con sólo refinamiento no aprecio diferencias en los resultados. En cualquier caso incluimos en el algoritmo el código para la opción max-length-first, que se basa en filtrar las celdas no unitarias y seleccionar la primera de mayor tamaño.
A continuación fijamos un vértice en la parte comentada con Fix vertex, algo que ya explicamos en el tema anterior, tras lo cual puede producirse una partición discreta, pero generalmente no es así y lo comprobamos con part.length<n, en cuyo caso pasamos a refinar esa partición, pues como hemos dicho más arriba, después de fijar un vértice si la partición no es discreta entonces tampoco es equitable, por lo que hay que refinarla para que lo sea.
Llamamos a refinePartition({matrix, partition:part, cells}) con el algoritmo para refinar que explicaremos a continuación, pasando la partición y las celdas cells = [[vertex]] con el vértice fijado previamente. El resto del algoritmo es igual que el visto en el tema anterior.
Refinar partición refinePartition()
Expliquemos ahora el algoritmo para refinar una partición refinePartition():
// Notes in practical graph isomorphism 2 (mckay piperno).pdf
function refinePartition({matrix=[], partition=[], cells=[]}) {
let result = [];
try {
let n = matrix.length;
if (cells.length===0) cells = [Array.from({length:n}, (v, i) => i)];
while (cells.length>0 && partition.length<n) {
// Remove some element W from cells
let cell = cells.pop();
for (let i=0; i<partition.length; i++) {
let part = partition[i];
if (part.length>1) {
// Let 'fragments' = p1,...,pk of 'part' distinguished according to the
// number of edges from each vertex to 'cell'
let fragments = [];
for (let ind=0; ind<part.length; ind++) {
let index = part[ind];
let neighbors = matrix.neighbors[index];
let neighborsToCell = neighbors.filter(v => cell.includes(v));
let num = neighborsToCell.length;
let j = fragments.findIndex(v => v.num===num);
if (j===-1) {
let arr = [];
arr.num = num;
j = fragments.length;
fragments.push(arr);
}
fragments[j].push(index);
}
if (fragments.length>1) {
// orderRefine (neighbors-desc-length-desc)
fragments.sort((v,w) => v.length===w.length ? w.num-v.num : w.length-v.length);
// Replace 'part' by 'fragments' in 'partition'
partition.splice(i, 1, ...fragments);
let ps = part.toString();
let indexPart = cells.findIndex(v => v==ps);
if (indexPart>-1) {
// Replace 'part' by 'fragments' in 'cells'
cells.splice(indexPart, 1, ...fragments);
} else {
// Add all but one of the largest of 'fragments' to 'cells'
let [kMax, len] = [-1, 0];
for (let k=0; k<fragments.length; k++) {
if (fragments[k].length>len) [kMax, len] = [k, fragments[k].length];
}
fragments.splice(kMax, 1);
cells.push(...fragments);
}
}
}
}
}
result = partition;
} catch(e){result = e.message}
return result;
}Los comentarios de este algoritmo se refieren al documento de referencia [D2], donde lo expone en pseudocódigo y que he tratado de seguir aunque cambiando los nombres de algunas variables.
Para explicar su funcionamiento, al menos en lo que he podido asimilar, veremos con el ejemplo de este tema el paso de refinamiento que exponíamos en la Figura, donde teníamos la partición con refinamiento inicial de nodo raíz [[1,3,5,7],[0,2,6,8],[4]] de la que fijábamos el vértice 1 quedando [[1],[3,5,7],[0,2,6,8],[4]] y refinando con las celdas [[1]] con el vértice 1 fijado, obteniéndose [[1],[3,5],[7],[0,2],[6,8],[4]] tras el refinado que vemos en la traza del árbol de particiones:
"tree":[{"index":0,"value":"(1 3 5 7)(0 2 6 8)(4)","parent":-1},
{"index":1,"value":"(1)(3 5)(7)(0 2)(6 8)(4)","parent":[{"index":0,"value":1}]},
...El siguiente esquema traza lo que ocurre en la primera iteración del bucle while de refinePartition(), que en total hará 3 iteraciones aunque las dos últimas no modificarán la partición refinada [[1],[3,5],[7],[0,2],[6,8],[4]]. Puede ver el esquema completo en el archivo de texto scheme-refine-partition.txt
SCHEME REFINEMENT PARTITION
====================================================================
matrix.neighbors =
0 1 2 3 4 5 6 7 8
[[1,3],[0,2,3,4,5],[1,5],[0,1,4,6,7],[1,3,5,7],[1,2,4,7,8],[3,7],[3,4,5,6,8],[5,7]];
Loop WHILE
-----------
Iteration 1 -------------------------------------------------------
partition = [[1],[3,5,7],[0,2,6,8],[4]]
cells = [[1]]
cell.pop()
cell = [1]
cells = []
part = [3,5,7]
// Let fragments = p1,...,pk of part distinguished according to the
// number of edges from each vertex to cell
fragments = []
index = 3
neighbors[3] = [0,1,4,6,7]
neigborsToCell [1] = [1]
num = neighborsToCell.length = 1;
let arr = [3];
arr.num = 1,
fragments = [[3]1]
index = 5
neighbors[5] = [1,2,4,7,8]
neigborsToCell [1] = [1]
num = neighborsToCell.length = 1;
arr.num = 1,
fragments = [[5,3]1]
index = 7
neighbors[7] = [[3,4,5,6,8]
neigborsToCell [1] = []
num = neighborsToCell.length = 0;
let arr = [7];
arr.num = 0,
fragments = [[7]0, [5,3]1]
// orderRefine (neighbors-desc-length-desc)
Sort fragments = [[3,5]1, [7]0]
// Replace part [3,5,7] by fragments in partition
partition = [[1],[3,5],[7],[0,2,6,8],[4]]
indexPart of part [3,5,7] in cells [] = -1
// Add all but one of the largest of fragments to cells
cells = [[7]]
part = [0,2,6,8]
// Let fragments = p1,...,pk of part distinguished according to the
// number of edges from each vertex to cell
fragments = []
index = 0
neighbors[0] = [1,3]
neigborsToCell [1] = [1]
num = neighborsToCell.length = 1;
let arr = [0];
arr.num = 1,
fragments = [[0]1]
index = 2
neighbors[2] = [1,5]
neigborsToCell [1] = [1]
num = neighborsToCell.length = 1;
arr.num = 1,
fragments = [[0,2]1]
index = 6
neighbors[8] = [3,7]
neigborsToCell [1] = []
num = neighborsToCell.length = 0;
let arr = [6];
arr.num = 0,
fragments = [[6]0,[0,2]1]
index = 8
neighbors[8] = [5,7]
neigborsToCell [1] = []
num = neighborsToCell.length = 0;
arr.num = 0,
fragments = [[6,8]0,[0,2]1]
// orderRefine (neighbors-desc-length-desc)
Sort fragments = [[0,2]1,[6,8]0]
// Replace part [0,2,6,8] by fragments in partition
partition = [[1],[3,5],[7],[0,2],[6,8],[4]]
indexPart of part [0,2,6,8] in cells [[7] = -1
// Add all but one of the largest of fragments to cells
cells = [[7],[6,8]]
Iteration 2 -------------------------------------------------------
...
Iteration 3 -------------------------------------------------------
...
End Loop WHILE-------------------------------------------------------
cells = [] and return partition = [[1],[3,5],[7],[0,2],[6,8],[4]]En el esquema anterior recordamos los vecinos de los vértices que teníamos en matrix.neighbors pues se va a acceder a ellos. El esquema traza las iteraciones en el bucle while que se inicia con cells=[[1]] y en cada iteración estas celdas pueden incrementarse o reducirse, de tal forma que finalizaremos cuando esté vacía. La partición de entrada se va modificando si unos fragmentos que iremos construyendo tiene longitud mayor de uno, lo que solo sucederá con la primera de las 3 iteraciones que se produce en el bucle while.
Observe como part = [3,5,7] se divide en los fragmentos fragments = [[3,5]1, [7]0] donde el subíndice indica el número de vecinos de los vértices de ese fragmento en relación con los vértices de la celda cell = [1] que se está considerando. Así que en este momento modificamos la partición quedando [[1],[3,5],[7],[0,2,6,8],[4]], donde hemos separado [3,5,7] en [3,5] y [7] teniendo en cuenta el número de vecinos en relación con la celda cell = [1] que contiene el vértice fijado.
Al tratar part = [0,2,6,8] llegamos a los fragmentos fragments = [[0,2]1,[6,8]0] lo que da lugar a modificar la partición quedando partition = [[1],[3,5],[7],[0,2],[6,8],[4]] donde separamos [0,2] y [6,8] atendiendo al número de vecinos en relación con la celda cell = [1].
En el fondo se trata de obligar a que la partición [[1],[3,5,7],[0,2,6,8],[4]], en la que hemos fijado el vértice 1, vuelva a ser equitable, para lo cual reagrupamos los vértices de las partes con longitud mayor que uno atendiendo al número de vecinos con el vértice fijado.
En este momento cells = [[7],[6,8]] y aún tenemos que seguir dos iteraciones más hasta que cells = [], pero no modificarán la última partición alcanzada, por lo que se devuelve partition = [[1],[3,5],[7],[0,2],[6,8],[4]]
Como he comentado, este algoritmo lo implemento a partir del pseudocódigo que he consultado en los documentos de referencia. No estoy seguro de que pueda optimizarse, lo que sería muy conveniente pues este proceso de refinamiento ocupa una parte importante del tiempo total de ejecución al obtener el árbol de particiones. Por ejemplo ¿podría prescindirse de las dos últimas iteraciones dado que no modifican la partición?
Otra duda es que viendo las últimas líneas de refinePartition() que modifican cells, donde en el esquema trazado con el ejemplo anterior sólo se producía la segunda alternativa Add all but one of the largest of 'fragments' to 'cells'. La mayor parte de los ejemplos de grafos que he visto en la documentación de referencia no se daba la primera alternativa Replace 'part' by 'fragments' in 'cells', encontrando sólo algunos ejemplos, como el grafo de la Figura, que se incluye en el documento [D3] y que puede importar en la aplicación con este JSON en el archivo graph-sample-4.txt
Forzar partición equitable forceEquitablePartition()
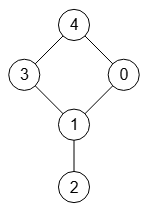
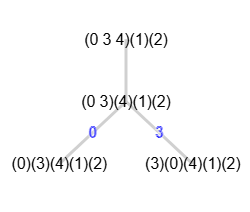
En la página 21 del documento [D3] encontramos el grafo de la Figura (ver JSON en graph-sample-3.txt) que nos servirá para explicar como forzar una partición equitable usando el algoritmo forceEquitablePartition().
En la Figura vemos su árbol de particiones con sólo refinamiento y sin otras podas (mcr o indicador), cuya traza exponemos más abajo. En el árbol observamos un nodo raíz (0 3 4)(1)(2) que genera un segundo nodo (0 3)(4)(1)(2), algo que la mayor parte de las veces no sucede, pues el refinamiento inicial ya produce una partición equitable, como decíamos más arriba, pero ahora no es así. Si obtenemos los vecinos del grafo con getNeighbors() y agrupamos por grados tenemos:
vértices: 0 1 2 3 4 vecinos: [[1,4],[0,2,3],[1],[1,4],[0,3]] grado 1: [2] grado 2: [0,3,4] grado 3: [1]
Así que la partición inicial será [[0,3,4],[1],[2]]. Pero esta partición no es equitable, que podemos comprobar con el algoritmo isEquitablePartition() resultando:
Es partición equitable (McKay): [false, "Vj=[0,3,4], v1=0, v2=4, Vi=[0,3,4], neighbors(v1)=[4], neighbors(v2)=[0,3]"]
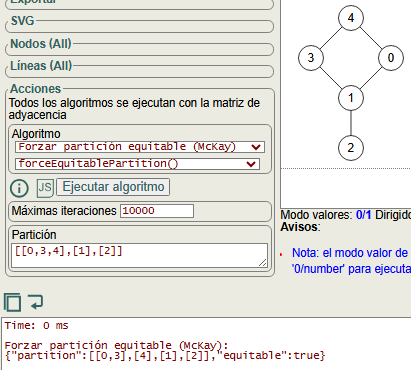
Vea que los vecinos de v1=0 en el grafo son [1, 4] y sólo [4] aparece en [0,3,4]. Mientras que los vecinos de v2=4 en el grafo son [0,3] que ambos aparecen en [0,3,4]. Al no tener el mismo número de vecinos entonces la partición no es equitable. Para arreglarlo el algoritmo (en su versión final) comprueba si la primera partición es equitable, pues cuando no lo sea ejecuta forceEquitablePartition().
En la Figura vemos como le pasamos la partición no equitable [[0,3,4],[1],[2]] y nos devuelve la equitable [[0,3],[4],[1],[2]]. Es a partir de esta cuando empezamos el proceso recursivo de fijar y refinar particiones.
Este es el resultado de obtener el árbol de particiones del grafo de la Figura, árbol que generamos con la opción verificar equitables activada ("checkEquitables": true), observando al final de la traza que nos devuelve "initialEquitable": false, "initialEquitableForced": true indicando que la partición inicial no era equitable y fue forzada a equitable.
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":false,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":3,"refine":1,"indexTree":3,
"leaves":2,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[3],[4],[1],[2]],
"firstCanon":true,
"canonicalPartition":[[0],[3],[4],[1],[2]],
"firstCanonicalLabel":[[0,2],[0,3],[1,2],[1,3],[3,4]],
"canonicalLabel":[[0,2],[0,3],[1,2],[1,3],[3,4]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[],[]]],
[[0,[],[],"f*"],[0,[],[],"=(0 3)"]]],
"nodeBest":[2,0],
"mcr":null,
"fixMcr":null,
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":0,
"tree":[{"index":0,"value":"(0 3 4)(1)(2)","parent":-1},
{"index":1,"value":"(0 3)(4)(1)(2)","parent":0},
{"index":2,"value":"(0)(3)(4)(1)(2)","parent":[{"index":1,"value":0}]},
{"index":3,"value":"(3)(0)(4)(1)(2)","parent":[{"index":1,"value":3}]}],
"automorphisms":
[[[0,3],[1],[2],[4]]],
"automorphismsPlus":0,
"initialEquitable":false,"initialEquitableForced":true}En un apartado anterior exponíamos que había que fijar un vértice de la partición no discreta y luego refinarla. Pero si al fijar el vértice ya se convierte la partición en discreta no es necesario refinarla. En este ejemplo vemos la partición (0 3)(4)(1)(2) que hemos forzado a equitable. Entonces fijamos el vértice 0 quedando (0)(3)(4)(1)(2) discreta, por lo que no es necesario refinarla. Y lo mismo cuando fijamos el vértice 3. Por eso en la traza anterior vemos "refine":1 del único refinamiento que hubo y que fue el de forzar a equitable la primera partición.
Entre las opciones para ejecutar el algoritmo getPartitionTree() que obtiene el árbol de particiones vimos en el tema anterior esa opción verificar equitables. Activada o no siempre se lleva a cabo con la partición inicial, pero sólo se comprueba con el resto de particiones no discretas (que no sean hojas ni raíz) si estuviera activada, pues como hemos dicho el proceso de fijar vértice más refinar siempre produce una partición equitable, con lo que no es recomendable activarla pues esa verificación consume tiempo.
{kind=link}
Si la activamos para el grafo de la Figura sólo veremos la comprobación inicial pues su árbol de particiones no genera más particiones no discretas. En cambio para el grafo de la Figura si activamos verificar equitables obtendríamos al final de la traza "initialEquitable": true, "equitables": 4, "nonEquitables": 0, verificando que las 4 particiones no discretas de su árbol de particiones son equitables mientras que no detecta ninguna no equitable.
En la Figura vemos un grafo que aparece en el documento [D7]. Al ejecutar el árbol de particiones vemos que tiene solo 2 nodos, produciéndose lo mismo que vimos antes, pero ahora ya la primera partición forzada a equitable es ya una hoja, con lo que el algoritmo no entra en la parte recursiva y finaliza devolviendo esa hoja como canónica.
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":false,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":1,"refine":1,"indexTree":1,
"leaves":0,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":null,
"firstCanon":true,
"canonicalPartition":[[12],[6],[9],[15],[11],[14],[13],[10],[8],[7],[5],[3],[4],[0],[2],[1]],
"firstCanonicalLabel":null,
"canonicalLabel":[[0,2],[0,6],[0,9],[1,7],[1,9],[1,12],[2,4],[2,8],[3,5],[3,7],[3,8],[4,5],[4,7],[5,6],[6,11],[8,10],[9,10],[10,13],[11,12],[11,15],[12,14],[13,14],[13,15]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[],[],"f*"]]],
"nodeBest":[2,0],
"mcr":null,
"fixMcr":null,
"lastEqual":false,"rebuiltMcr":0,"nonRebuiltMcr":0,
"tree":[{"index":0,"value":"(0 3 4 5 6 7 8 9 10 11 12 13 14 15)(1 2)","parent":-1},
{"index":1,"value":"(12)(6)(9)(15)(11)(14)(13)(10)(8)(7)(5)(3)(4)(0)(2)(1)","parent":0}],
"automorphisms":0,
"automorphismsPlus":0,
"initialEquitable":false,"initialEquitableForced":true} El código JavaScript para ejecutar forceEquitablePartition() es el siguiente, donde simplemente refinamos la partición con refinePartition() y luego comprobamos que es equitable con isEquitablePartition() que veremos a continuación.
function forceEquitablePartition({matrix=[], partition=[], orderRefine}) {
let result = {partition, equitable:false};
try {
let items = partition.toSorted((v, w) => w.length-v.length);
for (let c of items) {
result.partition = refinePartition({matrix, partition, cells:[c], orderRefine});
if (typeof partition==="string") throw new Error(partition);
let temp = isEquitablePartition({matrix, partition, verifyInputs:false, withMsg:false});
if (typeof temp==="string") throw new Error(temp);
if (temp[0]) {
result.equitable = true;
break;
}
}
} catch(e){result = e.message}
return result;
Comprobar si una partición es equitable isEquitablePartition()
Más arriba en el apartado de refinamiento, particiones equitables y particiones ordenadas definíamos una partición equitable como sigue:
Una partición (..., ci, ..., cj, ...), donde ck son sus celdas, es equitable con respecto a un grafo si para cada pareja de celdas ci, cj con i=j ∨ i≠j sucede que si v1, v2 son dos vértices de cj entonces deg(v1, ci) = deg(v2, ci) donde deg(v, c) es el número de vecinos del vértice v en la celda c.
El código JavaScript para ejecutar isEquitablePartition() es el siguiente, donde hemos puesto un comentario que hace referencia al documento [D3] donde explica como comprobar si una partición es equitable.
// Notes in 2018_K27_report.pdf
//We define D(W, v) as the number of elements in W that are neighbours to v in the graph G.
//A partition p = (V1|...|Vn) ∈ P(V)* as equitable if for every elements v1 and v2 in the
//same cell Vj of p, D(Vi, v1) = D(Vi, v2) for every i in 1, 2, ..., |p|.
function isEquitablePartition({matrix=[], partition=[], verifyInputs=true, withMsg=true}) {
let result = [true, ""];
try {
if (verifyInputs && !verifyMode01(matrix)) throw new Error(`(isEquitablePartition) Matrix must come in mode 0/1`);
let n = matrix.length;
if (!matrix.hasOwnProperty("neighbors")) {
matrix.neighbors = [];
for (let index=0; index<n; index++) {
let neighbors = getNeighbors({matrix, index});
if (typeof neighbors==="string") throw new Error(neighbors);
matrix.neighbors.push(neighbors);
}
}
if (verifyInputs) {
let keys = Array.from({length: n}, (v,i) => i);
let keysStr = keys.toString();
if (partition.flat().toSorted((v,w)=>v-w).toString()!==keysStr){
throw new Error(`Incorrect partition`);
}
}
for (let jj=0; jj<partition.length; jj++) {
let cellVj = partition[jj];
if (cellVj.length>1) {
if (cellVj.some((v,i,a) => i>0 && a[i-1]>v)) {
throw new Error(`Cell ${JSON.stringify(cellVj)} is not ordered`);
}
for (let j=0; j<cellVj.length; j++) {
for (let k=0; k<j; k++) {
let [v1, v2] = [cellVj[k], cellVj[j]];
for (let ii=0; ii<partition.length; ii++) {
let cellVi = partition[ii];
if (cellVi.length>1) {
let neighborsv1 = matrix.neighbors[v1].filter(v => cellVi.includes(v));
let neighborsv2 = matrix.neighbors[v2].filter(v => cellVi.includes(v));
let dv1 = neighborsv1.length;
let dv2 = neighborsv2.length;
if (dv1!==dv2) {
let msg = withMsg ? `Vj=${JSON.stringify(cellVj)}, v1=${v1}, v2=${v2}, Vi=${JSON.stringify(cellVi)}, ` +
`neighbors(v1)=${JSON.stringify(neighborsv1)}, neighbors(v2)=${JSON.stringify(neighborsv2)}` : "";
return [false, msg];
}
}
}
}
}
}
}
} catch(e){result = e.message}
return result;
}Comparar particiones comparePartitions()
Más arriba definíamos el orden entre particiones,tal que si π1 y π2 son dos particiones ordenadas entonces:
- Decimos que son iguales π1 ≃ π2 si ambas tienen las mismas celdas.
- Decimos que π1 es más fina que π2, que expresamos como π1 ≤ π2, si cada celda de π1 es un subconjunto de alguna celda de π2. De forma opuesta podríamos decir que π2 es más gruesa que π1 que expresamos como π2 > π1
El código JavaScript para ejecutar comparePartitions() hace referencia al documento [D3] donde explica como comparar particiones, que traducimos por Si tenemos dos particiones π1 y π2 decimos que π1 es más fina que π2 si cada celda de la primera partición es un subconjunto de una de las celdas de la segunda, lo que denotamos como π1 ≤ π2
. Y eso es lo que hacemos con este algoritmo.
Recordemos que este algoritmo no interviene en getPartitionTree() para obtener el árbol de particiones y su único objetivo es tratar de entender este concepto de comparación de particiones.
// Notes in 2018_K27_report.pdf
//If we have two partitions p1 and p2 we say that p1 is finer than p2 if every cell of the
//partition p1 is a subset of one of the cells in the partition p2, which is denoted
//p1 <= p2
function comparePartitions({matrix=[], partition1=[], partition2=[]}) {
let result = [-1, "Undefined"];
try {
if (!verifyMode01(matrix)) throw new Error(`(comparePartitions) Matrix must come in mode 0/1`);
let n = matrix.length;
if (!matrix.hasOwnProperty("edges")) {
let edges = getEdges({matrix, edgesCompact:true});
if (typeof edges==="string") throw new Error(edges);
matrix.edges = edges;
}
if (!matrix.hasOwnProperty("neighbors")) {
matrix.neighbors = [];
for (let index=0; index<n; index++) {
let neighbors = getNeighbors({matrix, index});
if (typeof neighbors==="string") throw new Error(neighbors);
matrix.neighbors.push(neighbors);
}
}
let keys = Array.from({length: n}, (v,i) => i);
let keysStr = keys.toString();
if (partition1.flat().toSorted((v,w)=>v-w).toString()!==keysStr){
throw new Error(`Incorrect partition 1`);
}
if (partition2.flat().toSorted((v,w)=>v-w).toString()!==keysStr){
throw new Error(`Incorrect partition 2`);
}
result = [1, `partition1 > partition2`];
let ok = true;
for (let cell of partition1) {
if (cell.some((v,i,a) => i>0 && a[i-1]>v)) {
throw new Error(`Cell ${JSON.stringify(cellVj)} is not ordered`);
}
if (!partition2.some(v => cell.every(w => v.includes(w)))) {
ok = false;
break;
}
}
result = ok ? [0, `partition1 <= partition2`] : [1, `partition1 > partition2`];
} catch(e){result = e.message}
return result;
}