Isomorfismos: poda con indicadores
Impacto en el rendimiento usando la poda con indicadores
En los temas anteriores vimos la poda con automorfismos en el algoritmo de McKay, que simplificábamos con poda mcr de minimum cell representative. En algunos grafos es posible además aplicar una poda con indicadores que reduce mucho más el tamaño del árbol de particiones y, por tanto, de los tiempos de ejecución.
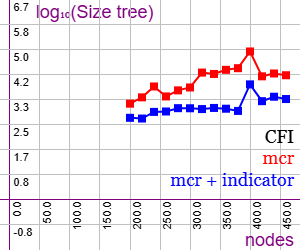
En la Figura vemos la ejecución del árbol de particiones con el grafo CFI con ejemplares de 200 a 460 vértices del grafo, midiendo el tamaño del árbol de particiones con el número de sus nodos (Size tree) en una escala logarítmica en base 10, donde valores como 1, 2, 3, 4, 5 significan 10, 100, 1000, 10000, 100000 nodos del árbol. Puede importar esa gráfica en la aplicación Gráficas matemáticas usando la configuración del archivo math-graph-cfi.txt
Con sólo poda automorfismos (mcr) tenemos la gráfica en color rojo, observando que para el último ejemplar de 460 vértices necesita un árbol de particiones con 13868 nodos (4.14 en el eje logarítmico vertical). Mientras que agregando la poda indicadores (mcr + indicator) en la gráfica en azul se reducen los nodos del árbol hasta 2232 nodos (3.35 en valor logarítmico). Esto supone una reducción de casi un 84% en número de nodos del árbol, algo que que se traduce en tiempos de ejecución, pues el tamaño del árbol de particiones es proporcional al tiempo de ejecución, como se observa en el resultado obtenido para ese grafo a continuación:
CFI-46 (460 nodes 690 edges)
mcr
Time: 8304 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-asc","targetCell":"min-length-first",
"typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,
"typeIndicator":"none",
"timeTotal":8304,"timeIni":69,"timeRef":3237,
"iter":35952,"refine":13869,"indexTree":13868,
"leaves":2037,
"prunningMcr":10252,"prunningMcrBreak":1,
"prunningIndicators":0,"prunningIndicators2":0,
mcr + indicator
Time: 1714 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-asc","targetCell":"min-length-first",
"typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,
"typeIndicator":"lengths",
"timeTotal":1714,"timeIni":54,"timeRef":1458,
"iter":6159,"refine":2233,"indexTree":2232,
"leaves":146,
"prunningMcr":2026,"prunningMcrBreak":1,
"prunningIndicators":0,"prunningIndicators2":186Vea la opción "typeIndicator": "none" sin poda indicadores y "typeIndicator": "lengths" con poda de indicadores usando el valor longitudes que explicaremos después. En "prunningIndicators2":186 vemos que se podan ramas en 186 ocasiones. Las iteraciones también se ven reducidas desde 35952 hasta 6159. Y el tiempo de ejecución, desde 8304 ms hasta 1714 ms.
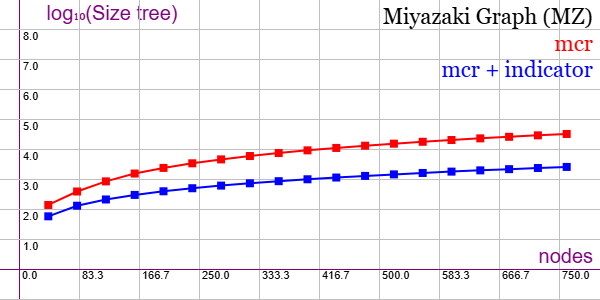
A continuación vemos la misma comparativa para el grafo MZ (Miyazaki Graph). Puede importar esa gráfica en la aplicación Gráficas matemáticas usando la configuración del archivo math-graph-mz.txt
Los tipos de indicadores que implemento en la aplicación son longitudes (lengths), celdas (cells), vecinos (neighbors) y aristas (edges). Con la poda con indicadores tenemos el problema de elegir el tipo de indicador adecuado, además de que para muchos grafos estos indicadores no le suponen ninguna diferenciación, ralentizando además la ejecución, pues su gestión ocupa un tiempo.
Para algunos grafos muy duros como KEF10 de 200 nodos y 1000 aristas con poda autormorfismos y sin poda indicadores no se obtiene el árbol de particiones en 300 segundos con más de 5 millones de iteraciones. Sin embargo con poda indicadores longitudes (lengths) se obtiene en menos de 7 segundos con 47041 iteraciones:
Time: 6857 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-last","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":6857,"timeIni":26,"timeRef":4815,
"iter":47041,"refine":18090,"indexTree":18506,
"leaves":417,
"prunningMcr":24729,"prunningMcrBreak":644,
"prunningIndicators":0,"prunningIndicators2":14284,La familia KEF tiene ejemplares de 200 a 800 nodos, pero aún con indicadores usando el segundo ejemplar KEF11 con 242 nodos y 1331 aristas, que no es mucho mayor que el anterior, no se obtiene el árbol incluso con indicador longitudes en 300 segundos y más de 5 millones de iteraciones.
El grafo MZ que vimos antes tenía un comportamiento uniforme para todos los tamaños, pero para otros como LATIN esto no sucede, como vemos en la siguiente gráfica para tamaños entre 16 y 529 vértices.
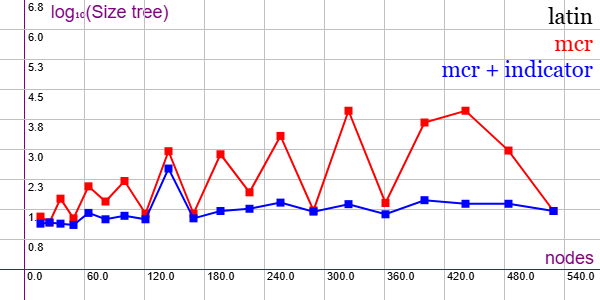
Para algunos tamaños de grafos LATIN el tamaño del árbol de particiones (Size tree) es igual o similar. Sin embargo para otros hay una diferencia muy significativa. En cualquier caso con indicadores vemos que el comportamiento es más uniforme en casi todos los tamaños. En el próximo apartado tomaremos el primer ejemplar con 16 vértices para explicar la poda con indicadores, pues sin ella el árbol de particiones tiene 22 nodos y con indicador tiene 15 nodos. Puede importar esa gráfica en la aplicación Gráficas matemáticas usando la configuración del archivo math-graph-latin.txt
Poda con indicadores
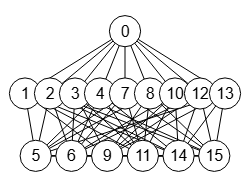
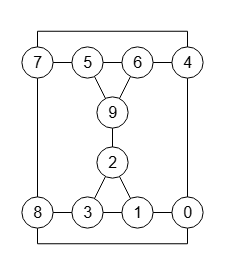
En la Figura vemos el grafo LATIN-4 con 16 vértices y 72 aristas que puede importar en la aplicación con el JSON del archivo graph-latin-4.txt, que nos servirá para explicar la poda con indicadores.
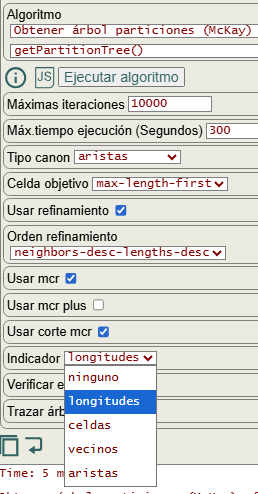
En la Figura vemos las opciones para ejecutar el algoritmo getPartitionTree() que obtiene el árbol de particiones. Activamos la poda con automorfismos activando usar mcr ("useMcr") y usar corte mcr ("useMcrBreak") que ya hemos visto en temas anteriores. En indicador usaremos longitudes ("typeIndicator":"lengths"), observando que además hay disponible vecinos ("neighbors") y aristas ("edges").
A continuación mostramos el resultado obtenido.
Time: 2 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":2,"timeIni":0,"timeRef":1,
"iter":29,"refine":15,"indexTree":14,
"leaves":6,
"prunningMcr":7,"prunningMcrBreak":3,
"prunningIndicators":0,"prunningIndicators2":1,
"firstCanonicalPartition":[[0],[1],[3],[2],[4],[13],[12],[7],[8],[10],[5],[14],[11],[9],[6],[15]],
"firstCanon":true,
"canonicalPartition":[[0],[1],[3],[2],[4],[13],[12],[7],[8],[10],[5],[14],[11],[9],[6],[15]],
"firstCanonicalLabel":[[0,1],[0,2],[0,3],[0,4],[0,5],[0,6],[0,7],[0,8],[0,9],[1,2],[1,3],[1,4],[1,5],[1,10],[1,11],[1,12],[1,13],[2,3],[2,6],[2,7],[2,12],[2,13],[2,14],[2,15],[3,8],[3,9],[3,10],[3,11],[3,14],[3,15],[4,6],[4,7],[4,8],[4,10],[4,11],[4,12],[4,14],[5,6],[5,7],[5,9],[5,10],[5,11],[5,13],[5,15],[6,8],[6,11],[6,13],[6,14],[6,15],[7,9],[7,10],[7,12],[7,14],[7,15],[8,9],[8,10],[8,12],[8,13],[8,15],[9,11],[9,12],[9,13],[9,14],[10,13],[10,14],[10,15],[11,12],[11,14],[11,15],[12,13],[12,15],[13,14]],
"canonicalLabel":[[0,1],[0,2],[0,3],[0,4],[0,5],[0,6],[0,7],[0,8],[0,9],[1,2],[1,3],[1,4],[1,5],[1,10],[1,11],[1,12],[1,13],[2,3],[2,6],[2,7],[2,12],[2,13],[2,14],[2,15],[3,8],[3,9],[3,10],[3,11],[3,14],[3,15],[4,6],[4,7],[4,8],[4,10],[4,11],[4,12],[4,14],[5,6],[5,7],[5,9],[5,10],[5,11],[5,13],[5,15],[6,8],[6,11],[6,13],[6,14],[6,15],[7,9],[7,10],[7,12],[7,14],[7,15],[8,9],[8,10],[8,12],[8,13],[8,15],[9,11],[9,12],[9,13],[9,14],[10,13],[10,14],[10,15],[11,12],[11,14],[11,15],[12,13],[12,15],[13,14]],
"canonicalIndicator":[1,3,10,0],
"nodes":
[[[-1,[],[1],"PA","PA13"]],
[[0,[0],[1,3],"PA","PA4"],[0,[1],[1,3],"PA","PA6"]],
[[0,[0,1],[1,3,10]],[0,[0,2],[1,3,6],"PI"],[0,[0,3],[1,3,10],"PA"],[0,[0,4],[1,3,10],"PA"],[1,[1,0],[1,3,10],"PA"],[1,[1,2],[1,3,10],"PA"]],
[[0,[0,1,4],[1,3,10,0],"f*"],[0,[0,1,13],[1,3,10,0],"==(4 13)(5 14)(6 15)(7 12)(8 10)(9 11)"],[2,[0,3,7],[1,3,10,0],"==(1 3)(4 7)(5 6)(8 10)(12 13)(14 15)"],[3,[0,4,1],[1,3,10,0],"==(1 4)(2 8)(3 12)(6 9)(7 13)(11 14)"],[4,[1,0,4],[1,3,10,0],"==(0 1)(2 3)(5 7)(8 11)(9 10)(12 14)"],[5,[1,2,5],[1,3,10,0],"==(0 1 2 3)(4 5 6 7)(8 9 10 11)(12 13 14 15)"]]],
"nodeBest":[3,0],
"mcr":[0],
"fixMcr":
[[[0,1,2,3],[0,1,2,3,4,5,6,7,8,9]],
[[0,2,9,11],[0,1,2,4,5,8,9,11,12,14]],
[[0,5,10,15],[0,1,2,3,5,6,7,10,11,15]],
[[4,6,13,15],[0,2,4,5,6,8,9,12,13,15]],
[[],[0,4,8,12]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":12,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15)","parent":-1},
{"index":1,"value":"(0)(1 2 3 4 7 8 10 12 13)(5 6 9 11 14 15)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(3)(2)(4 13)(7 12)(8 10)(5 14)(9 11)(6 15)","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(1)(3)(2)(4)(13)(12)(7)(8)(10)(5)(14)(11)(9)(6)(15)","parent":[{"index":2,"value":"4"}]},
{"index":4,"value":"(0)(1)(3)(2)(13)(4)(7)(12)(10)(8)(14)(5)(9)(11)(15)(6)","parent":[{"index":2,"value":"13"}]},
{"index":5,"value":"(0)(2)(1 3 8 10)(4 7 12 13)(5 6 14 15)(9 11)","parent":[{"index":1,"value":"2"}]},
{"index":6,"value":"(0)(3)(1)(2)(7 12)(4 13)(8 10)(6 15)(9 11)(5 14)","parent":[{"index":1,"value":"3"}]},
{"index":7,"value":"(0)(3)(1)(2)(7)(12)(13)(4)(10)(8)(6)(15)(11)(9)(5)(14)","parent":[{"index":6,"value":"7"}]},
{"index":8,"value":"(0)(4)(12)(8)(1 7)(3 13)(2 10)(5 11)(6 14)(9 15)","parent":[{"index":1,"value":"4"}]},
{"index":9,"value":"(0)(4)(12)(8)(1)(7)(3)(13)(2)(10)(5)(11)(14)(6)(9)(15)","parent":[{"index":8,"value":"1"}]},
{"index":10,"value":"(1)(0 2 3 4 5 9 11 13 14)(6 7 8 10 12 15)","parent":[{"index":0,"value":"1"}]},
{"index":11,"value":"(1)(0)(2)(3)(4 13)(5 14)(9 11)(7 12)(8 10)(6 15)","parent":[{"index":10,"value":"0"}]},
{"index":12,"value":"(1)(0)(2)(3)(4)(13)(14)(5)(11)(9)(7)(12)(8)(10)(6)(15)","parent":[{"index":11,"value":"4"}]},
{"index":13,"value":"(1)(2)(0)(3)(5 14)(4 13)(9 11)(6 15)(8 10)(7 12)","parent":[{"index":10,"value":"2"}]},
{"index":14,"value":"(1)(2)(0)(3)(5)(14)(13)(4)(9)(11)(6)(15)(8)(10)(7)(12)","parent":[{"index":13,"value":"5"}]}],
"automorphisms":
[[[0],[1],[2],[3],[4,13],[5,14],[6,15],[7,12],[8,10],[9,11]],
[[0],[1,3],[2],[4,7],[5,6],[8,10],[9],[11],[12,13],[14,15]],
[[0],[1,4],[2,8],[3,12],[5],[6,9],[7,13],[10],[11,14],[15]],
[[0,1],[2,3],[4],[5,7],[6],[8,11],[9,10],[12,14],[13],[15]],
[[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]]],
"automorphismsPlus":0}Ejecutamos un test de 50000 isomorfismos con poda indicador observando que todos resultaron isomórficos.
Time: 29735 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","typeCanon":"edges","targetCell":"max-length-first","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"isomorphic":50000,"nonIsomorphic":0,
"firstTime":1,"minTime":0,"averageTime":1,"maxTime":17,
"iter1":29,"iter2":30,
"indexTree1":14,"indexTree2":15,
"minIndexTree":10,"maxIndexTree":41,
"refine1":15,"refine2":16,
"numAut1":5,"numAut2":5,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":7,"prunningMcr2":7,"prunningMcrBreak1":3,"prunningMcrBreak2":4,
"rebuiltMcr1":0,"rebuiltMcr2":0,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":1,"prunningIndicators2b":2,
"canonical":[[0,1],...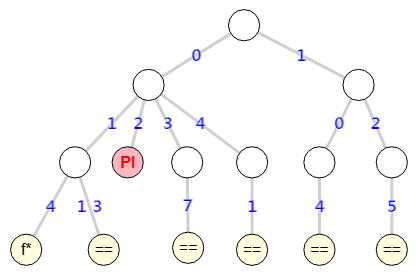
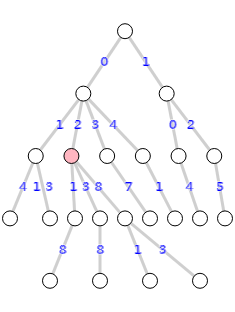
En la Figura vemos el árbol de particiones con 15 nodos usando poda indicador. Y en la Figura vemos el árbol sin esa poda con 22 nodos. Se observa que se poda una rama en el nodo marcado con "PI", con lo que podamos 7 nodos en ese subárbol.
La primera hoja izquierda marcada con "f*" es la canónica y todas las demás resultaron iguales "==". El campo "nodes" del resultado nos da el árbol que trasladamos en posición vertical:
[-1,[],[1],"PA","PA13"]] (0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15)
[0,[0],[1,3],"PA","PA4"] (0)(1 2 3 4 7 8 10 12 13)(5 6 9 11 14 15)
[0,[0,1],[1,3,10]] (0)(1)(3)(2)(4 13)(7 12)(8 10)(5 14)(9 11)(6 15)
[0,[0,1,4],[1,3,10,0],"f*"]
[0,[0,1,13],[1,3,10,0],"=="]
[0,[0,2],[1,3,6],"PI"] (0)(2)(1 3 8 10)(4 7 12 13)(5 6 14 15)(9 11)
[0,[0,3],[1,3,10],"PA"]
[2,[0,3,7],[1,3,10,0],"=="]
[0,[0,4],[1,3,10],"PA"]
[3,[0,4,1],[1,3,10,0],"=="]
[0,[1],[1,3],"PA","PA6"]]
[1,[1,0],[1,3,10],"PA"]
[4,[1,0,4],[1,3,10,0],"=="]
[1,[1,2],[1,3,10],"PA"]
[5,[1,2,5],[1,3,10,0],"=="]"firstCanonicalPartition":[[0],...], "firstCanon":true, "canonicalPartition":[[0],...], "firstCanonicalLabel":[[0,1],..], "canonicalLabel":[[0,1],...], "canonicalIndicator":[1,3,10,0],
En la aplicación almacenamos el etiquetado canónico en el campo "canonicalLabel", que con "firstCanonicalLabel", "canonicalPartition" y "firstCanonicalPartition" nos sirve para ejecutar el algoritmo con poda automorfismos, como vimos en temas anteriores. Ahora ademas usamos el campo "canonicalIndicator" que almacena el indicador canónico de la hoja marcada con el etiquetado canónico.
Vemos que la hoja canónica marcada con "f*", la primera encontrada, está en el tercer nodo [0,[0,1,4],[1,3,10,0],"f*"], recordando que el primer "0" es el índice del padre en el nivel inmediato superior, el primer subarray [0,1,4] es el camino de vértices fijados que usámos para la poda con automorfismos y el último subarray [1,3,10,0] es el vector indicador (o camino indicador o simplemente indicador) de longitudes en este caso que se guarda en "canonicalIndicator":[1,3,10,0].
El indicador se inicia en el nodo raíz con el valor [1]. A medida que vamos generando nodos en el árbol agregamos su valor indicador componiendo un camino o vector de valores indicadores, así el segundo nodo tiene el camino indicador [1,3], el tercero [1,3,10] y el cuarto [1,3,10,0], observando que todas las hojas que sean particiones discretas tienen indicador 0. Así cuando llegamos al nodo no terminal [0,[0,2],[1,3,6],"PI"] vemos que su indicador [1,3,6] es lexicográficamente menor que [1,3,10,0], así que ninguna hoja descendente de ese subárbol podrá tener un etiquetado canónico mayor que el actual, con lo que podamos ese subárbol. Vea que agregamos el comentario informativo "PI" de poda indicador. Observe que es el único nodo con menor indicador en ese nivel, pues tiene [1,3,6] y todos los demás tienen [1,3,10].
En las páginas 26 a 28 del documento de referencia [D7] de McKay y también en [D5] de McKay y Piperno, encontramos estas definiciones:
Un invariante de un nodo μ del árbol de particiones es un valor Φ(μ) que depende únicamente de las propiedades combinatorias de μ y sus ancestros en ese árbol y que cumple ciertas condiciones técnicas.
Por ejemplo, Φ(μ) = [c(μ'), c(μ"), ..., c(μ)] es un invariante de nodo con orden lexicográfico donde μ', μ", ..., μ es el camino desde la raíz del árbol al nodo μ y c(μ) es la función indicadora del nodo, algo como longitudes, vecinos o aristas.
La función indicadora debe cumplir c(G, π, μ) = c(Gγ, πγ, μγ) para cualquier permutación γ del grafo.
Sea Φ* el invariante de nodo más grande encontrado en una hoja. Entonces, el grafo etiquetado lexicográficamente mayor correspondiente a una hoja μ con Φ(μ) = Φ* es un grafo canónico.
Esto permite podar las partes del árbol que no pueden contener un grafo canónico.
- Si μ1 y μ2 son nodos del árbol de particiones al mismo nivel y Φ(μ1) > Φ(μ2) entonces ningún etiquetado canónico es decendente desde μ2.
- Si μ1 y μ2 son nodos del árbol de particiones al mismo nivel y Φ(μ1) ≠ Φ(μ2) entonces ningún grafo etiquetado que desciende de μ1 es igual a uno que desciende de μ2.
- Si μ1 y μ2 son hojas del árbol de particiones donde se encuentra el automorfismo γ tal μ2 = (μ1)γ, entonces γ mapea el subárbol descendente de μ1 en el árbol descendente de μ2. Así que cualquier etiquetado descendente de μ2 es igual que alguno descendente de μ1.
En un tema anterior sobre poda con automorfismos expusimos el principio tercero. Aplico en mi implementación el primer principio para podar ramas en el árbol de particiones que explicaremos en este tema.
No acabo de entender el segundo, pues no veo como puede podarse con ese concepto, pues si Φ(μ1) ≠ Φ(μ2) entonces o Φ(μ1) > Φ(μ2) y se poda la rama de μ2 como dice el primer punto o Φ(μ1) < Φ(μ2) y entonces μ2 contendrá un mayor etiquetado canónico y será el nuevo Φ*.
Ya he comentado que los documentos de referencia exponen un algoritmo que no he podido o he sabido implementar directamente. Basándome en conceptos clave, ejemplos y especialmente verificando ejemplos de grafos con el algoritmo testIsomorphims(), he llegado a los siguientes principios que aplico a mi implementación, donde indico los campos prunningMcr, prunningIndicator y prunningIndicator2 que acumulan esos casos y que se devuelven con la traza del árbol.
- Si μ1 y μ2 son dos hojas y el indicador canónico anterior era Φ* = Φ(μ1) con el etiquetado canónico G(μ1) entonces comparando Φ(μ1) y Φ(μ2) puede suceder lo siguiente:
- Si Φ(μ1) < Φ(μ2) entonces Φ* = Φ(μ2) será el nuevo indicador canónico con G(μ2) como nuevo etiquetado canónico.
- Si Φ(μ1) = Φ(μ2) entonces tendremos estos casos comparando G(μ1) y G(μ2)
- Si G(μ1) < G(μ2) entonces G(μ2) será el nuevo etiquetado canónico manteniéndose el mismo indicador canónico.
- Si G(μ1) = G(μ2) entonces se encuentra el automorfismo γ tal μ2 = (μ1)γ lo que permitirá podar con automorfismos (
prunningMcryprunningMcrBreak). - Si G(μ1) > G(μ2) no hay nada que deducir.
- Si Φ(μ1) > Φ(μ2) no hay nada que deducir pero evitamos tener que comparar los dos etiquetados canónicos G(μ1) y G(μ2) (
prunningIndicator).
- Si μ1 y μ2 son nodos no hojas al mismo nivel y Φ(μ1) > Φ(μ2) entonces ningún etiquetado canónico es decendente desde μ2 y se puede podar el subárbol que desciende de este nodo (
prunningIndicator2).
"prunningMcr":7, "prunningMcrBreak":3, "prunningIndicators":0, "prunningIndicators2":1,
En la traza del ejemplo anterior vemos que se producen 10 podas con automorfismos (prunningMcr y prunningMcrBreak) y una poda con indicadores prunningIndicators2.
En el algoritmo se comparan los indicadores y cuando son iguales se comparan los etiquetados canónicos. Un etiquetado canónico puede ser la matriz de adyacencia o la lista de aristas. Ya vimos en un tema anterior como comparar etiquetados canónicos, siendo más eficiente comparar listas de aristas. En cualquier caso comparar etiquetados canónicos consume mucho tiempo especialmente con grafos grandes, así que si nos ahorramos esta comparación en la alternativa prunningIndicator ahorraremos tiempos de ejecución. Y si diseñamos adecuadamente el algoritmo podemos incluso ahorrarnos la función auxiliar para obtener el canon a partir de la partición discreta, pues en esa alternativa no lo necesitamos.
Observe que si no usamos indicadores el algoritmo aplica sólo los principios A, B y C que son los que afectan a la poda con automorfismos, lo que sucederá también usando indicadores pero cuando en todos los casos siempre resultan iguales.
...
[0,[0,1],[1,3,10]]
[0,[0,1,4],[1,3,10,0],"f*"]
[0,[0,1,13],[1,3,10,0],"=="]
[0,[0,2],[1,3,6],"PI"]
...Vea que el camino indicador almacenado es [1,3,10,0] en la hoja canónica "f*" así que para comparar ese indicador con [1,3,6] que está en un nivel superior es como si tomáramos tantas primeras posiciones de [1,3,10,0] como posiciones tenga el que vamos a comparar [1,3,6], así que se cumple el primer principio con Φ(μ1) = [1,3,10] > Φ(μ2) = [1,3,6], con lo que en el subárbol de μ2 no encontraremos ningún etiquetado canónico y podamos ese subárbol.
El valor que devuelve la función indicadora es simplemente el número de celdas que tiene cada partición, a excepción de los nodos terminales que le asignamos 0:
Partition Valor función
indicatora
------------------------------------------------------------------------
(0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15) 1
(0)(1 2 3 4 7 8 10 12 13)(5 6 9 11 14 15) 3
(0)(1)(3)(2)(4 13)(7 12)(8 10)(5 14)(9 11)(6 15) 10
(0)(1)(3)(2)(4)(13)(12)(7)(8)(10)(5)(14)(11)(9)(6)(15) 0
(0)(2)(1 3 8 10)(4 7 12 13)(5 6 14 15)(9 11) 6El vector indicador del nodo terminal con etiquetado canónico es la lista de valores [1,3,10,0] que viene a ser el camino de indicadores por los nodos que pasa, agregando al final un 0 pues a los nodos terminales siempre le aplicamos directamente un valor 0 sin más cálculos. Los comparamos así:
Φ(μ2) = [1,3,6] Φ(μ1) = [1,3,10,0] ≡ [1,3,10] (mismo nivel) Compare Φ(μ2), Φ(μ1) ------------------------ 1 == 1 3 == 3 6 < 10 ⇒ Φ(μ2) < Φ(μ1)
Los indicadores deben ser invariantes del grafo
En los principios téoricos que vimos más arriba decíamos que un invariante de un nodo μ del árbol de particiones es un valor Φ(μ) que depende únicamente de las propiedades combinatorias de μ y sus ancestros en ese árbol y que cumple ciertas condiciones técnicas. Así definíamos un vector o camino indicador o simplemente indicador como una secuencia de valores devueltos por una función indicadora, que devuelve el número de celdas de las particiones, indicador que denominamos "longitudes" en la aplicación.
Para entender esto veamos el grafo de ejemplo de la Figura que puede verse en el documento de referencia [D3] y que puede importar en la aplicación con este JSON en el archivo graph-sample-4b2.txt
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":1,"timeIni":0,"timeRef":1,
"iter":17,"refine":10,"indexTree":9,
"leaves":7,
"prunningMcr":5,"prunningMcrBreak":0,
"prunningIndicators":2,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[7],[3],[6],[2],[9],[5],[1],[8],[4]],
"firstCanon":false,
"canonicalPartition":[[2],[5],[6],[0],[8],[7],[4],[3],[1],[9]],
"firstCanonicalLabel":[[0,7],[0,8],[0,9],[1,6],[1,8],[1,9],[2,4],[2,7],[2,8],[3,5],[3,6],[3,9],[4,5],[4,7],[5,6]],
"canonicalLabel":[[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"canonicalIndicator":[1,6,0],
"nodes":
[[[-1,[],[1],"PA","R5","R6","PA","R7","PA","R8","PA","R9"]],
[[0,[0],[1,0],"f"],[0,[1],[1,0],"=>"],[0,[2],[1,6]],[0,[4],[1,0],"<"],[0,[5],[1,0],"<"],[0,[9],[1,6],"PA"]],
[[2,[2,5],[1,6,0],">*"],[2,[2,6],[1,6,0],"==(0 8)(1 3)(4 7)(5 6)"],[5,[9,1],[1,6,0],"==(0 7)(1 5)(2 9)(3 6)(4 8)"]]],
"nodeBest":[2,0],
"mcr":[0,1,2,4],
"fixMcr":
[[[2,9],[0,1,2,4,5,9]],
[[],[0,1,2,3,4]]],
"lastEqual":true,"rebuiltMcr":5,"nonRebuiltMcr":3,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9)","parent":-1},
{"index":1,"value":"(0)(7)(3)(6)(2)(9)(5)(1)(8)(4)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(1)(5)(6)(7)(4)(9)(8)(3)(2)(0)","parent":[{"index":0,"value":"1"}]},
{"index":3,"value":"(2)(5 6)(0 8)(4 7)(1 3)(9)","parent":[{"index":0,"value":"2"}]},
{"index":4,"value":"(2)(5)(6)(0)(8)(7)(4)(3)(1)(9)","parent":[{"index":3,"value":"5"}]},
{"index":5,"value":"(2)(6)(5)(8)(0)(4)(7)(1)(3)(9)","parent":[{"index":3,"value":"6"}]},
{"index":6,"value":"(4)(8)(5)(1)(9)(2)(3)(6)(7)(0)","parent":[{"index":0,"value":"4"}]},
{"index":7,"value":"(5)(1)(3)(0)(8)(2)(4)(6)(9)(7)","parent":[{"index":0,"value":"5"}]},
{"index":8,"value":"(9)(1 3)(4 7)(0 8)(5 6)(2)","parent":[{"index":0,"value":"9"}]},
{"index":9,"value":"(9)(1)(3)(7)(4)(0)(8)(6)(5)(2)","parent":[{"index":8,"value":"1"}]}],
"automorphisms":
[[[0,8],[1,3],[2],[4,7],[5,6],[9]],
[[0,7],[1,5],[2,9],[3,6],[4,8]]],
"automorphismsPlus":0}El test de isomorfismos resulta correcto para las 3662880 primeras permutaciones.
Time: 52741 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","typeCanon":"edges","targetCell":"max-length-first","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"isomorphic":362880,"nonIsomorphic":0,
"firstTime":1,"minTime":0,"averageTime":0,"maxTime":29,
"iter1":17,"iter2":17,
"indexTree1":9,"indexTree2":9,
"minIndexTree":6,"maxIndexTree":12,
"refine1":10,"refine2":10,
"numAut1":2,"numAut2":2,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":5,"prunningMcr2":5,"prunningMcrBreak1":0,"prunningMcrBreak2":0,
"rebuiltMcr1":5,"rebuiltMcr2":6,
"prunningIndicators1":2,"prunningIndicators2":3,
"prunningIndicators1b":0,"prunningIndicators2b":0,
"canonical":[[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"warnings":["The graph has more than 9 nodes and only the first 9!=362880 permutations will be tested or less if the maximum time of 60 seconds is exceeded"]}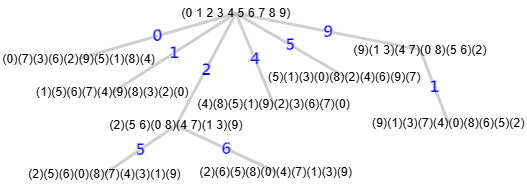
En la Figura vemos el árbol de particiones.
A continuación vemos el campo "nodes" que es el árbol de particiones puesto en forma vertical para visualizarlo mejor, con lo que explicaremos como se aplican algunos principios básicos de la implementación que he llevado a cabo.
[-1,[],[1],"PA","R5","R6","PA","R7","PA","R8","PA","R9"]
[0,[0],[1,0],"f"]
[0,[1],[1,0],"=>"]
[0,[2],[1,6]]
[2,[2,5],[1,6,0],">*"]
[2,[2,6],[1,6,0],"==(0 8)(1 3)(4 7)(5 6)"]
[0,[4],[1,0],"<"]
[0,[5],[1,0],"<"]
[0,[9],[1,6],"PA"]
[5,[9,1],[1,6,0],"==(0 7)(1 5)(2 9)(3 6)(4 8)"]"prunningMcr":5, "prunningMcrBreak":0, "prunningIndicators":2, "prunningIndicators2":0,
Observamos que la primera hoja "f" siempre se marca como canónica, con lo que al llegar a esa hoja tendríamos "f*". Luego encontró que la segunda "=>" tenía el mismo indicador canónico [1,0] (se indica con el primer "=" de "=>") pero su etiquetado canónico era mayor (se indica con ">" de "=>"), con lo que pasa a ser la canónica marcándose con "=>*" y quitando el "*" de la anterior.
Luego llega a la tercera hoja con indicador [1,6,0] que es mayor que el anterior canónico pasando a ser el canónico ahora, marcándose con ">*" y quitando el "*" de la anterior.
La cuarta hoja tiene el mismo indicador [1,6,0] pero su etiquetado canónico es igual que el anterior, así que se marca con "==", donde el primer igual es el del indicador y el segundo del etiquetado canónico. Con esto se obtiene el automorfismo (0 8)(1 3)(4 7)(5 6) que nos servirá para una poda con MCR posterior, como vemos en el nodo no hoja [0,[9],[1,6],"PA"] donde "PA" indica que se produjo una poda con automorfismo (prunningMcr) o en el nodo raíz donde hay cuatro "PA".
Las hojas quinta y sexta tienen el comentario "<" con lo que sus indicadores [1,0] son menores que el último canónico [1,6,0], con lo que no será necesario comparar los etiquetados canónicos. Se contabilizan estos dos casos en "prunningIndicators":2.
En este ejemplo no hay ningún nodo no terminal cuyo indicador sea menor que el canónico, por lo que no se produce ninguna poda con indicador que se contabiliza en prunningIndicator2 y se marca en el árbol con "PI", como vimos en el ejemplo del apartado anterior.
Este grafo tiene como partición canónica "canonicalPartition": [[2],[5],[6],[0],[8],[7],[4],[3],[1],[9]] que viene a ser la permutación 2,5,6,0,8,7,4,3,1,9. Su etiquetado es "canonicalLabel": [[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]].
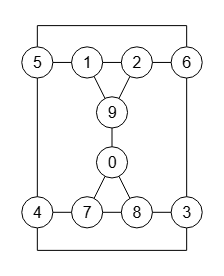
Vamos a aplicar al primer grafo de la Figura la permutación anterior 2,5,6,0,8,7,4,3,1,9 usando la operación operatePermuteGraph(), obteniendo el grafo de la Figura que puede importar en la aplicación con graph-sample-4c.txt.
En la traza obtenida siguiente vemos que su partición canónica es [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]] que se corresponde con la permutación identidad, donde su etiquetado canónico canonicalLabel es igual que el anterior y que este propio grafo, como no podía ser de otra forma.
Time: 4 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":4,"timeIni":1,"timeRef":1,
"iter":17,"refine":10,"indexTree":9,
"leaves":7,
"prunningMcr":5,"prunningMcrBreak":0,
"prunningIndicators":4,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]],
"firstCanon":true,
"canonicalPartition":[[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]],
"firstCanonicalLabel":[[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"canonicalLabel":[[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"canonicalIndicator":[1,6,0],
"nodes":
[[[-1,[],[1],"R2","PA","R3","R4","PA","R5","R6","PA","R7","R8","PA","R9"]],
[[0,[0],[1,6]],[0,[1],[1,0],"<"],[0,[3],[1,0],"<"],[0,[5],[1,0],"<"],[0,[7],[1,0],"<"],[0,[9],[1,6],"PA"]],
[[0,[0,1],[1,6,0],"f*"],[0,[0,2],[1,6,0],"==(1 2)(3 4)(5 6)(7 8)"],[5,[9,7],[1,6,0],"==(0 9)(1 7)(2 8)(3 6)(4 5)"]]],
"nodeBest":[2,0],
"mcr":[0,1,3],
"fixMcr":
[[[0,9],[0,1,3,5,7,9]],
[[],[0,1,2,3,4]]],
"lastEqual":true,"rebuiltMcr":8,"nonRebuiltMcr":2,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9)","parent":-1},
{"index":1,"value":"(0)(1 2)(3 4)(5 6)(7 8)(9)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(2)(3)(4)(5)(6)(7)(8)(9)","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(2)(1)(4)(3)(6)(5)(8)(7)(9)","parent":[{"index":1,"value":"2"}]},
{"index":4,"value":"(1)(8)(7)(3)(4)(0)(6)(2)(9)(5)","parent":[{"index":0,"value":"1"}]},
{"index":5,"value":"(3)(5)(7)(2)(0)(9)(1)(8)(4)(6)","parent":[{"index":0,"value":"3"}]},
{"index":6,"value":"(5)(3)(2)(7)(9)(0)(8)(1)(6)(4)","parent":[{"index":0,"value":"5"}]},
{"index":7,"value":"(7)(2)(1)(6)(5)(9)(3)(8)(0)(4)","parent":[{"index":0,"value":"7"}]},
{"index":8,"value":"(9)(7 8)(5 6)(3 4)(1 2)(0)","parent":[{"index":0,"value":"9"}]},
{"index":9,"value":"(9)(7)(8)(6)(5)(4)(3)(1)(2)(0)","parent":[{"index":8,"value":"7"}]}],
"automorphisms":
[[[0],[1,2],[3,4],[5,6],[7,8],[9]],
[[0,9],[1,7],[2,8],[3,6],[4,5]]],
"automorphismsPlus":0}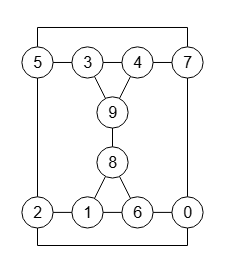
Y a continuación aplicamos otra permutación aleatoria 0,3,8,5,6,7,1,4,2,9 también al primer grafo de la Figura, obteniendo el grafo de la Figura que puede importar con graph-sample-4d.txt.
En la traza vemos que se obtiene otra partición canónica pero el etiquetado canónico canonicalLabel es el mismo, como era de esperar.
Time: 2 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":2,"timeIni":0,"timeRef":1,
"iter":17,"refine":11,"indexTree":10,
"leaves":8,
"prunningMcr":4,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[5],[1],[4],[8],[9],[3],[6],[2],[7]],
"firstCanon":false,
"canonicalPartition":[[8],[3],[4],[0],[2],[5],[7],[1],[6],[9]],
"firstCanonicalLabel":[[0,7],[0,8],[0,9],[1,6],[1,8],[1,9],[2,4],[2,7],[2,8],[3,5],[3,6],[3,9],[4,5],[4,7],[5,6]],
"canonicalLabel":[[0,7],[0,8],[0,9],[1,2],[1,5],[1,9],[2,6],[2,9],[3,4],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"canonicalIndicator":[1,6,0],
"nodes":
[[[-1,[],[1],"PA","PA","PA"]],
[[0,[0],[1,0],"f"],[0,[1],[1,0],"=>"],[0,[2],[1,0],"=<"],[0,[3],[1,0],"==(0 7)(1 3)(2 5)(4 6)(8 9)"],[0,[4],[1,0],"==(0 5)(1 4)(2 7)(3 6)(8 9)"],[0,[8],[1,6],"R4"],[0,[9],[1,6],"PA"]],
[[5,[8,3],[1,6,0],">*"],[5,[8,4],[1,6,0],"==(0 2)(1 6)(3 4)(5 7)"],[6,[9,1],[1,6,0],"==(0 7)(1 3)(2 5)(4 6)(8 9)"]]],
"nodeBest":[2,0],
"mcr":[0,1,8],
"fixMcr":
[[[],[0,1,2,4,8]],
[[],[0,1,2,3,8]],
[[8,9],[0,1,3,5,8,9]],
[[],[0,1,2,4,8]]],
"lastEqual":true,"rebuiltMcr":1,"nonRebuiltMcr":7,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9)","parent":-1},
{"index":1,"value":"(0)(5)(1)(4)(8)(9)(3)(6)(2)(7)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(1)(4)(3)(7)(5)(9)(0)(6)(8)(2)","parent":[{"index":0,"value":"1"}]},
{"index":3,"value":"(2)(7)(6)(3)(8)(9)(4)(1)(0)(5)","parent":[{"index":0,"value":"2"}]},
{"index":4,"value":"(3)(6)(1)(0)(2)(8)(7)(4)(9)(5)","parent":[{"index":0,"value":"3"}]},
{"index":5,"value":"(4)(1)(6)(2)(0)(8)(5)(3)(9)(7)","parent":[{"index":0,"value":"4"}]},
{"index":6,"value":"(8)(3 4)(0 2)(5 7)(1 6)(9)","parent":[{"index":0,"value":"8"}]},
{"index":7,"value":"(8)(3)(4)(0)(2)(5)(7)(1)(6)(9)","parent":[{"index":6,"value":"3"}]},
{"index":8,"value":"(8)(4)(3)(2)(0)(7)(5)(6)(1)(9)","parent":[{"index":6,"value":"4"}]},
{"index":9,"value":"(9)(1 6)(5 7)(0 2)(3 4)(8)","parent":[{"index":0,"value":"9"}]},
{"index":10,"value":"(9)(1)(6)(7)(5)(2)(0)(3)(4)(8)","parent":[{"index":9,"value":"1"}]}],
"automorphisms":
[[[0,7],[1,3],[2,5],[4,6],[8,9]],
[[0,5],[1,4],[2,7],[3,6],[8,9]],
[[0,2],[1,6],[3,4],[5,7],[8],[9]],
[[0,7],[1,3],[2,5],[4,6],[8,9]]],
"automorphismsPlus":0}Ahora analicemos los tres árboles del campo "nodes":
Árbol particiones del grafo original
[-1,[],[1],"PA","R5","R6","PA","R7","PA","R8","PA","R9"]
[0,[0],[1,0],"f"]
[0,[1],[1,0],"=>"]
[0,[2],[1,6]]
[2,[2,5],[1,6,0],">*"]
[2,[2,6],[1,6,0],"==(0 8)(1 3)(4 7)(5 6)"]
[0,[4],[1,0],"<"]
[0,[5],[1,0],"<"]
[0,[9],[1,6],"PA"]
[5,[9,1],[1,6,0],"==(0 7)(1 5)(2 9)(3 6)(4 8)"]
Grafo canónico (permutación [2,5,6,0,8,7,4,3,1,9] del grafo original)
[-1,[],[1],"R2","PA","R3","R4","PA","R5","R6","PA","R7","R8","PA","R9"]
[0,[0],[1,6]]
[0,[0,1],[1,6,0],"f*"]
[0,[0,2],[1,6,0],"==(1 2)(3 4)(5 6)(7 8)"]
[0,[1],[1,0],"<"]
[0,[3],[1,0],"<"]
[0,[5],[1,0],"<"]
[0,[7],[1,0],"<"]
[0,[9],[1,6],"PA"]]
[5,[9,7],[1,6,0],"==(0 9)(1 7)(2 8)(3 6)(4 5)"]
Permutación [0,3,8,5,6,7,1,4,2,9] del grafo original
[-1,[],[1],"PA","PA","PA"]
[0,[0],[1,0],"f"]
[0,[1],[1,0],"=>"]
[0,[2],[1,0],"=<"]
[0,[3],[1,0],"==(0 7)(1 3)(2 5)(4 6)(8 9)"]
[0,[4],[1,0],"==(0 5)(1 4)(2 7)(3 6)(8 9)"]
[0,[8],[1,6],"R4"],
[5,[8,3],[1,6,0],">*"]
[5,[8,4],[1,6,0],"==(0 2)(1 6)(3 4)(5 7)"]
[0,[9],[1,6],"PA"]
[6,[9,1],[1,6,0],"==(0 7)(1 3)(2 5)(4 6)(8 9)"]Observamos que para los tres grafos isomórficos el etiquetado canónico canonicalLabel se encuentra en una hoja con el mismo indicador canónico [1,6,0]. Por eso decimos que los indicadores son invariantes, pues no dependen del grafo isomórfico, sino de su posición en el árbol con respecto al camino de particiones que recorra. Así vemos que se producen los indicadores [1], [1,0], [1,6] y [1,6,0] en los nodos de los tres árboles, aunque no en el mismo orden o posición.
En el siguiente apartado veremos un ejemplo con dos grafos no isomórficos.
Indicadores y grafos no isomórficos
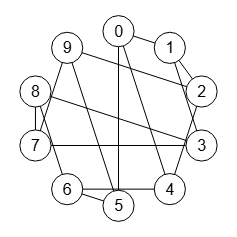
La función indicadora es invariante para un grafo y todas sus permutaciones, pero no para otros grafos que no sean permutaciones. Por ejemplo, el grafo de la Figura (que puede importar con graph-sample-4e.txt) tiene el mismo número de vértices, aristas y grados de los vértices que el primer grafo del apartado anterior de la Figura, pero no es una permutación como veremos a continuación.
En un tema anterior explicábamos el algoritmo isGraphIsomorphic() para comprobar si dos grafos eran isomórficos. Vamos a comprobar si el grafo de la Figura es isomórfico con el de la Figura pasándole su matriz de adyacencia:
0 1 0 0 1 0 0 0 1 0 1 0 1 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 1 1 0 0 0 1 0 0 0 0 1 1 0 0 1 0 1 0 0 1 0 0 0 1 0 0 0 0 1 0 0 1 1 0 0 0
Si usamos fuerza bruta, con las opciones fuerza bruta con todas las permutaciones en orden o con permutación inicial solo comprobará las 8! = 362880 primeras permutaciones para no colapsar el navegador. Como hay 10 nodos tenemos 10! = 3628800 permutaciones y debemos usar el método fuerza bruta con permutaciones aleatorias que las comprobará todas siempre que pongamos un número suficiente de iteraciones, 100 millones en este caso. O usar el método McKay como veremos después.
Con fuerza bruta después de casi 150 segundos obtenemos este resultado:
Time: 149595 ms Es el grafo isomórfico: [false, "The maximum number of permutations 3628800 was reached and we can assure that they are not isomorphic (iterations 57228087 of 100000000)"]
Después de más de 57 millones de iteraciones y comprobar todas las 3628800 permutaciones no encontró ninguna en el grafo de la Figura que fuera igual que el grafo de la Figura. Por lo tanto no son isomórficos.
Si usamos el algoritmo de McKay el resultado es inmediato (sólo 4 ms), observando que el grafo canónico no es el mismo, resaltándose las diferencias:
Time: 4 ms Es el grafo isomórfico: [false, "Canonical graph 0,7,0,8,0,9,1,3,1,5,1,9,2,4,2,6,2,9,3,6,3,8,4,5,4,7,5,6,7,8 is not the same as 0,7,0,8,0,9,1,2,1,5,1,9,2,6,2,9,3,4,3,6,3,8,4,5,4,7,5,6,7,8"]
Hay que recordar que el algoritmo isIsomorphicGraph() devuelve la lista de aristas que es el grafo canónico sin separaciones entre aristas, así 0,7,0,8,0,9,... es fácil de convertir en [[0,7],[0,8],[0,9], ...].
Vemos la traza del árbol de particiones del grafo de la Figura:
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":1,"timeIni":0,"timeRef":1,
"iter":14,"refine":10,"indexTree":9,
"leaves":7,
"prunningMcr":3,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":1,
"firstCanonicalPartition":[[0],[6],[2],[3],[9],[7],[8],[1],[4],[5]],
"firstCanon":false,
"canonicalPartition":[[7],[2],[5],[1],[6],[4],[0],[8],[3],[9]],
"firstCanonicalLabel":[[0,7],[0,8],[0,9],[1,6],[1,8],[1,9],[2,4],[2,7],[2,8],[3,5],[3,6],[3,7],[4,5],[4,9],[5,6]],
"canonicalLabel":[[0,7],[0,8],[0,9],[1,3],[1,5],[1,9],[2,4],[2,6],[2,9],[3,6],[3,8],[4,5],[4,7],[5,6],[7,8]],
"canonicalIndicator":[1,6,0],
"nodes":
[[[-1,[],[1],"PA","R8","PA","R9"]],
[[0,[0],[1,0],"f"],[0,[1],[1,0],"=>"],[0,[2],[1,0],"=>"],[0,[3],[1,0],"=<"],[0,[4],[1,0],"=<"],[0,[5],[1,0],"==(0 4)(1 6)(2 5)(3 8)"],[0,[7],[1,6],"R5","PA"],[0,[9],[1,3],"PI"]],
[[6,[7,2],[1,6,0],">*"]]],
"nodeBest":[2,0],
"mcr":[0,1,2,3,7,9],
"fixMcr":
[[[7,9],[0,1,2,3,7,9]]],
"lastEqual":false,"rebuiltMcr":3,"nonRebuiltMcr":2,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9)","parent":-1},
{"index":1,"value":"(0)(6)(2)(3)(9)(7)(8)(1)(4)(5)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(1)(5)(8)(7)(9)(4)(6)(3)(2)(0)","parent":[{"index":0,"value":"1"}]},
{"index":3,"value":"(2)(7)(3)(6)(5)(0)(8)(1)(4)(9)","parent":[{"index":0,"value":"2"}]},
{"index":4,"value":"(3)(2)(0)(6)(9)(5)(4)(7)(8)(1)","parent":[{"index":0,"value":"3"}]},
{"index":5,"value":"(4)(1)(5)(8)(9)(7)(3)(6)(0)(2)","parent":[{"index":0,"value":"4"}]},
{"index":6,"value":"(5)(7)(8)(1)(2)(4)(3)(6)(0)(9)","parent":[{"index":0,"value":"5"}]},
{"index":7,"value":"(7)(2 5)(1 6)(0 4)(3 8)(9)","parent":[{"index":0,"value":"7"}]},
{"index":8,"value":"(7)(2)(5)(1)(6)(4)(0)(8)(3)(9)","parent":[{"index":7,"value":"2"}]},
{"index":9,"value":"(9)(0 1 3 4 6 8)(2 5 7)","parent":[{"index":0,"value":"9"}]}],
"automorphisms":
[[[0,4],[1,6],[2,5],[3,8],[7],[9]]],
"automorphismsPlus":0}
Exponiendo también el de la Figura veamos los árboles de particiones del campo "nodes":
Árbol particiones del grafo de la Figura [-1,[],[1],"PA","R5","R6","PA","R7","PA","R8","PA","R9"] [0,[0],[1,0],"f"] [0,[1],[1,0],"=>"] [0,[2],[1,6]] [2,[2,5],[1,6,0],">*"] [2,[2,6],[1,6,0],"==(0 8)(1 3)(4 7)(5 6)"] [0,[4],[1,0],"<"] [0,[5],[1,0],"<"] [0,[9],[1,6],"PA"] [5,[9,1],[1,6,0],"==(0 7)(1 5)(2 9)(3 6)(4 8)"] Árbol particiones del grafo no isomórfico de la Figura [-1,[],[1],"PA","R8","PA","R9"] [0,[0],[1,0],"f"] [0,[1],[1,0],"=>"] [0,[2],[1,0],"=>"] [0,[3],[1,0],"=<"] [0,[4],[1,0],"=<"] [0,[5],[1,0],"==(0 4)(1 6)(2 5)(3 8)"] [0,[7],[1,6],"R5","PA"] [6,[7,2],[1,6,0],">*"] [0,[9],[1,3],"PI"]]
Vemos que en los dos casos el indicador canónico es el mismo [1,6,0]. Pero eso no es suficiente para que sean isomórficos, pues más arriba decíamos que la función indicadora debe cumplir c(G, π, μ) = c(Gγ, πγ, μγ) para cualquier permutación γ del grafo. Pero no hay ninguna permutación que convierta un grafo en el otro.
Se observa que en el primero se generan los indicadores [1], [1,0], [1,6] y [1,6,0] mientras que en el segundo se generan estos pero además hay otro distinto [1,3], algo que no sucedería si ambos fueran isomórficos.
Tipos de indicadores
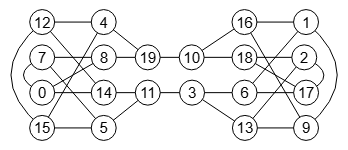
Para explicar los tipos de indicadores usaremos el ejemplo del Grafo de Miyazaki de la Figura que puede importar en la aplicación con miyazaki-graph.txt.
El resultado usando poda indicadores del tipo "lengths" es el siguiente:
Time: 2 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges",
"useMcr":true,"useMcrPlus":false,"useMcrBreak":true,
"typeIndicator":"lengths",
"timeTotal":2,"timeIni":0,"timeRef":1,
"iter":22,"refine":13,"indexTree":12,
"leaves":5,
"prunningMcr":7,"prunningMcrBreak":2,
"prunningIndicators":0,"prunningIndicators2":5,
"firstCanonicalPartition":[[0],[1],[2],[17],[9],[6],[13],[3],[16],[18],[15],[4],[10],[11],[12],[19],[5],[7],[8],[14]],
"firstCanon":true,
"canonicalPartition":[[0],[1],[2],[17],[9],[6],[13],[3],[16],[18],[15],[4],[10],[11],[12],[19],[5],[7],[8],[14]],
"firstCanonicalLabel":[[0,17],[0,18],[0,19],[1,4],[1,5],[1,8],[2,3],[2,6],[2,9],[3,5],[3,9],[4,6],[4,8],[5,7],[6,7],[7,13],[8,12],[9,12],[10,11],[10,14],[10,16],[11,14],[11,15],[12,15],[13,16],[13,19],[14,19],[15,18],[16,17],[17,18]],
"canonicalLabel":[[0,17],[0,18],[0,19],[1,4],[1,5],[1,8],[2,3],[2,6],[2,9],[3,5],[3,9],[4,6],[4,8],[5,7],[6,7],[7,13],[8,12],[9,12],[10,11],[10,14],[10,16],[11,14],[11,15],[12,15],[13,16],[13,19],[14,19],[15,18],[16,17],[17,18]],
"canonicalIndicator":[1,15,0],
"nodes":
[[[-1,[],[1],"PA","PA","PA","PA","PA","PA8"]],
[[0,[0],[1,15],"PA"],[0,[1],[1,15],"PA","PA1"],[0,[3],[1,10],"PI"],[0,[4],[1,12],"PI"],[0,[5],[1,12],"PI"],[0,[8],[1,12],"PI"],[0,[10],[1,10],"PI"]],
[[0,[0,1],[1,15,0],"f*"],[0,[0,2],[1,15,0],"==(1 2)(6 13)(9 17)(16 18)"],[0,[0,9],[1,15,0],"==(1 9)(2 17)(6 13)"],[1,[1,0],[1,15,0],"==(0 1)(2 15)(3 11)(4 18)(5 13)(6 14)(7 9)(8 16)(10 19)(12 17)"],[1,[1,7],[1,15,0],"==(0 1 7 9)(2 12 17 15)(3 11)(4 18)(5 13 14 6)(8 16)(10 19)"]]],
"nodeBest":[2,0],
"mcr":[0,3,4,5,8,10],
"fixMcr":
[[[0,3,4,5,7,8,10,11,12,14,15,19],[0,1,3,4,5,6,7,8,9,10,11,12,14,15,16,19]],
[[0,3,4,5,7,8,10,11,12,14,15,16,18,19],[0,1,2,3,4,5,6,7,8,10,11,12,14,15,16,18,19]],
[[],[0,2,3,4,5,6,7,8,10,12]],
[[],[0,2,3,4,5,8,10]]],
"lastEqual":true,"rebuiltMcr":0,"nonRebuiltMcr":15,
"tree":[{"index":0,"value":"(0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19)","parent":-1},
{"index":1,"value":"(0)(1 2 9 17)(6 13)(3)(16 18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(2)(17)(9)(6)(13)(3)(16)(18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14)","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(2)(1)(9)(17)(13)(6)(3)(18)(16)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14)","parent":[{"index":1,"value":"2"}]},
{"index":4,"value":"(0)(9)(17)(2)(1)(13)(6)(3)(16)(18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14)","parent":[{"index":1,"value":"9"}]},
{"index":5,"value":"(1)(0 7 12 15)(5 14)(11)(4 8)(2)(18)(19)(3)(17)(10)(13)(9)(16)(6)","parent":[{"index":0,"value":"1"}]},
{"index":6,"value":"(1)(0)(15)(12)(7)(14)(5)(11)(8)(4)(2)(18)(19)(3)(17)(10)(13)(9)(16)(6)","parent":[{"index":5,"value":"0"}]},
{"index":7,"value":"(1)(7)(12)(15)(0)(5)(14)(11)(8)(4)(2)(18)(19)(3)(17)(10)(13)(9)(16)(6)","parent":[{"index":5,"value":"7"}]},
{"index":8,"value":"(3)(0 7 12 15)(4 8)(19)(10)(16 18)(1 2 9 17)(5 14)(6 13)(11)","parent":[{"index":0,"value":"3"}]},
{"index":9,"value":"(4)(1 2 9 17)(16 18)(6 13)(3)(0 7)(11)(10)(8)(5 14)(12 15)(19)","parent":[{"index":0,"value":"4"}]},
{"index":10,"value":"(5)(1 2 9 17)(16 18)(10)(6 13)(19)(0 12)(14)(4 8)(3)(7 15)(11)","parent":[{"index":0,"value":"5"}]},
{"index":11,"value":"(8)(1 2 9 17)(16 18)(6 13)(3)(12 15)(11)(10)(4)(5 14)(0 7)(19)","parent":[{"index":0,"value":"8"}]},
{"index":12,"value":"(10)(0 7 12 15)(5 14)(11)(3)(6 13)(1 2 9 17)(4 8)(16 18)(19)","parent":[{"index":0,"value":"10"}]}],
"automorphisms":
[[[0],[1,2],[3],[4],[5],[6,13],[7],[8],[9,17],[10],[11],[12],[14],[15],[16,18],[19]],
[[0],[1,9],[2,17],[3],[4],[5],[6,13],[7],[8],[10],[11],[12],[14],[15],[16],[18],[19]],
[[0,1],[2,15],[3,11],[4,18],[5,13],[6,14],[7,9],[8,16],[10,19],[12,17]],
[[0,1,7,9],[2,12,17,15],[3,11],[4,18],[5,13,14,6],[8,16],[10,19]]],
"automorphismsPlus":0}Un test con 100000 permutaciones aleatorias resultan todas isomórficas:
Time: 43143 ms
Test isomorfismos (McKay): {"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","typeCanon":"edges","targetCell":"max-length-first","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"isomorphic":100000,"nonIsomorphic":0,
"firstTime":1,"minTime":0,"averageTime":0,"maxTime":2,
"iter1":22,"iter2":40,
"indexTree1":12,"indexTree2":22,
"minIndexTree":10,"maxIndexTree":39,
"refine1":13,"refine2":23,
"numAut1":4,"numAut2":7,"numAutPlus1":0,"numAutPlus2":0,
"prunningMcr1":7,"prunningMcr2":9,"prunningMcrBreak1":2,"prunningMcrBreak2":5,
"rebuiltMcr1":0,"rebuiltMcr2":1,
"prunningIndicators1":0,"prunningIndicators2":0,
"prunningIndicators1b":5,"prunningIndicators2b":5,
"canonical":[[0,17],[0,18],[0,19],[1,4],[1,5],[1,8],[2,3],[2,6],[2,9],[3,5],[3,9],[4,6],[4,8],[5,7],[6,7],[7,13],[8,12],[9,12],[10,11],[10,14],[10,16],[11,14],[11,15],[12,15],[13,16],[13,19],[14,19],[15,18],[16,17],[17,18]]}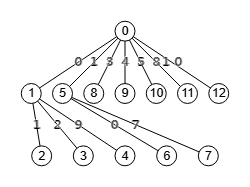
En la Figura vemos el árbol de particiones que puede importar en la aplicación con partition-tree-miyazaki-graph.txt. Prescindimos de las particiones pues ocupan mucho espacio, siendo los números de los nodos el orden en que se van originando.
Las hojas con las particiones discretas están en los nodos 2, 3, 4, 6 y 7 siendo la primera la canónica. Los nodos 8 a 12 también son hojas del árbol pero no son particiones discretas, pues en esos cinco nodos es donde se producen podas en sus subárboles con el indicador longitudes ("lengths").
Refine MCR Indicador Nodos árbol -------------------------------------- No No No >20!=2.43×1018 Sí No No 229 Sí Sí No 24 Sí Sí Sí 13
Sin refinamiento el árbol de nodos tendría un tamaño superior a 20! = 2.43 × 1018, pues esas serían sólo las hojas, con lo que no hay forma de obtenerlo. Usando sólo refinamiento el tamaño es de tan sólo 229 nodos. Con poda automorfismos (MCR) baja hasta 24. Y usando además indicadores el tamaño es de 13 nodos.
A continuación vemos el árbol de nodos tal como se gestiona en el campo "nodes", donde se observan 5 podas "PI" que se trazan con "prunningIndicators2":5
[-1,[],[1],"PA","PA","PA","PA","PA","PA8"]
[0,[0],[1,15],"PA"]
[0,[0,1],[1,15,0],"f*"]
[0,[0,2],[1,15,0],"==(1 2)(6 13)(9 17)(16 18)"]
[0,[0,9],[1,15,0],"==(1 9)(2 17)(6 13)"]
[0,[1],[1,15],"PA","PA1"]
[1,[1,0],[1,15,0],"==(0 1)(2 15)(3 11)(4 18)(5 13)(6 14)(7 9)(8 16)(10 19)(12 17)"]
[1,[1,7],[1,15,0],"==(0 1 7 9)(2 12 17 15)(3 11)(4 18)(5 13 14 6)(8 16)(10 19)"]
[0,[3],[1,10],"PI"]
[0,[4],[1,12],"PI"]
[0,[5],[1,12],"PI"]
[0,[8],[1,12],"PI"]
[0,[10],[1,10],"PI"]Ejecutamos para los cuatro tipos de indicadores disponibles lengths, cells, neighbors, edges obteniendo los resultados que puede consulta en este archivo miyazaki-graph-indicators.txt. No hay diferencia para este grafo en los resultados que son los mismos con todos los indicadores:
"iter":22,"refine":13,"indexTree":12,"leaves":5, "prunningMcr":7,"prunningMcrBreak":2, "prunningIndicators":0,"prunningIndicators2":5, "canonicalPartition":[[0],[1],[2],[17],[9],[6],[13],[3],[16],[18],[15],[4],[10],[11],[12],[19],[5],[7],[8],[14]], "canonicalLabel":[[0,17],[0,18],[0,19],[1,4],[1,5],[1,8],[2,3],[2,6],[2,9],[3,5],[3,9],[4,6],[4,8],[5,7],[6,7],[7,13],[8,12],[9,12],[10,11],[10,14],[10,16],[11,14],[11,15],[12,15],[13,16],[13,19],[14,19],[15,18],[16,17],[17,18]],
lengths [1,15,0] cells [98,1356,0] neighbors [102,1435,0] edges [99,1338,0]
La hoja con el etiquetado canónico tiene estos indicadores canónicos para cada uno de los tipos de indicadores implementados en la aplicación. Veamos como se construyen usando los tres primeros nodos del árbol de la Figura que intervienen hasta llegar a la primera hoja que es la del etiquetado canónico:
Nodo Partición --------------- 0 (0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19) 1 (0)(1 2 9 17)(6 13)(3)(16 18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14) 2 (0)(1)(2)(17)(9)(6)(13)(3)(16)(18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14)
El indicador longitudes (lengths) es el más simple y menos costoso de obtener pues es simplemente el número de celdas de la partición. Así las tres particiones anteriores tienen estos valores de indicadores:
LENGTHS Nodo Valor Indicador = Longitud de la partición (número de celdas) ------------------------------------------------------------- 0 1 1 15 2 0 (en las hojas siempre es 0)
A la partición discreta u hoja siempre se adjudica cero. Así el indicador de la hoja es el vector de valores [1,15,0], valores que se obtienen con la función indicadora que en este caso obtiene la longitud de la partición (número de celdas). Como la primera hoja es la canónica, se guarda este indicador canónico en "canonicalIndicator". Cuando llegamos a un nodo no terminal con "PI" que tiene indicador [1,10] comparamos [1,10] < [1,15] resultando cierto, pues 1 === 1 y 10 < 15, podándose el subárbol de esa rama.
Veamos ahora el indicador celdas (cells), cuya función indicadora devuelve el número de vértices en cada celda, es decir, la longitud de las celdas.
CELLS Nodo Longitudes de las celdas Valor Indicador ------------------------------------------------------------------------------------------------------------------------------- 0 [20] 98 = [..."20"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 1 [1,4,2,1,2,1,1,1,1,1,1,1,1,1,1] 1356 = [..."1,4,2,1,2,1,1,1,1,1,1,1,1,1,1"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 2 (en las hojas siempre es 0) 0
Con longitudes cada valor de la función indicadora era un número, pero ahora es un Array. Dado que la comparación de indicadores es lexicográfica, podemos codificar ese array sumando los códigos ASCII de los caracteres con charCodeAt(). Así el nodo 1 tiene función indicadora [1,4,2,1,2,1,1,1,1,1,1,1,1,1,1] con las longitudes de las celdas. Y codificada queda con el número 1356. Veamos el último nodo 12 del árbol:
Nodo 12: (10)(0 7 12 15)(5 14)(11)(3)(6 13)(1 2 9 17)(4 8)(16 18)(19) Longitudes de celdas: [1,4,2,1,1,2,4,2,2,1] [..."1,4,2,1,1,2,4,2,2,1"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) = 896
Comparemos el nodo 2 que es la partición canónica con este último nodo 12 donde se produce una poda "PI":
Indicador nodo 12: [98, 896] Indicador canónico (nodo 2): [98,1356,0] que se compara al mismo nivel [98,1356] Como [98, 896] < [98, 1356] puesto que 98 === 98 y 896 < 1356 ⇒ se poda esta rama
Si tuvieramos que comparar el indicador sin codificar sería más costoso, pues en cada comparación habría que iterar por cada array:
[98] === [98] [1,4,2,1,1,2,4,2,2,1] < [1,4,2,1,2,1,1,1,1,1,1,1,1,1,1]
Podríamos usar en JavaScript la comparación entre tipos cadena (String) convirtiendo los Arrays con toString() pues "1,4,2,1,1,2,4,2,2,1" < "1,4,2,1,2,1,1,1,1,1,1,1,1,1,1" es verdadero, pero esta comparación también conlleva iterar por lo caracteres aunque lo haga el propio JavaScript. Así que lo mejor es codificar cada Array una única vez y así en las comparaciones se realizan con un único número entero para cada valor del vector indicador.
A continuación vemos el indicador vecinos (neighbors), recordando que el algoritmo inicialmente obtiene y almacena los vecinos de todos los vértices del grafo usando el algoritmo getNeighbors(). Así cada valor de indicador es un Array con la suma en cada celda del número de vecinos que tiene cada vértice. Como los valores de indicadores son Arrays, también es necesario codificarlos.
NEIGHBORS Vecinos de los vértices: [[7,8,14],[6,9,16],[13,17,18],[6,11,13],[12,15,19],[7,11,15], [1,3,17],[0,5,8],[0,7,19],[1,13,16],[16,18,19],[3,5,14],[4,14,15],[2,3,9],[0,11,12], [4,5,12],[1,9,10],[2,6,18],[2,10,17],[4,8,10]] Valores del array son índices de nodos Nodo Vecinos en cada celda Valor Indicador ------------------------------------------------------------------------------------------------------------------------------- 0 [60] 102 = [..."60"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 1 [3,12,6,3,6,3,3,3,3,3,3,3,3,3,3] 1435 = [..."3,12,6,3,6,3,3,3,3,3,3,3,3,3,3"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 2 (en las hojas siempre es 0) 0
Y por último vemos el indicador aristas (edges), contando cuántas aristas hay en cada celda de la partición. En el algoritmo también se obtienen y guardan inicialmente las aristas con getEdges(). Este indicador es más costoso, pues hay que recorrer las celdas y las aristas para contar cuántas aristas hay en cada celda. Vemos que en la partición (0)(1 2 9 17)(6 13)(3)(16 18)(15)(4)(10)(11)(12)(19)(5)(7)(8)(14) sólo hay 2 aristas en la celda (1 2 9 17) que vemos resaltadas en azul en la lista de aristas.
EDGES Aristas del grafo: [[0,7],[0,8],[0,14],[1,6],[1,9],[1,16],[2,13],[2,17],[2,18],[3,6], [3,11],[3,13],[4,12],[4,15],[4,19],[5,7],[5,11],[5,15],[6,17],[7,8],[8,19],[9,13],[9,16], [10,16],[10,18],[10,19],[11,14],[12,14],[12,15],[17,18]] Nodo Aristas en cada celda Valor Indicador ------------------------------------------------------------------------------------------------------------------------------- 0 [30] 99 = [..."30"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 1 [0,2,0,0,0,0,0,0,0,0,0,0,0,0,0] 1335 = [..."0,2,0,0,0,0,0,0,0,0,0,0,0,0,0"].reduce((p,v) => (p+=v.charCodeAt(0), p), 0) 2 (en las hojas siempre es 0) 0