Isomorfismos: árbol de particiones
Obtener árbol particiones
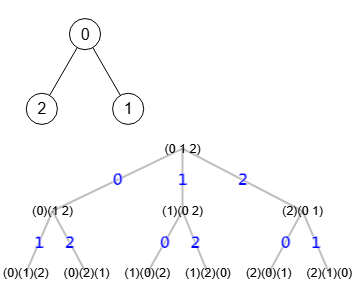
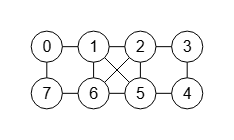
El primer paso para explicar el algoritmo de McKay, o al menos mi particular implementación, es ver como generamos el árbol de particiones para obtener todas las permutaciones del grafo, de donde localizaremos el etiquetado canónico (canonical label) para ese grafo. Usaremos el simple ejemplo de la Figura, un grafo estrella de 3 nodos con el que obtendremos un árbol de particiones con 10 nodos de los cuáles sus 6 hojas son las permutaciones del grafo.
Con el siguiente JSON puede importar ese grafo, ejecutándose el algoritmo getPartitionTree():
{"nodes":[
{"index":0,"nodeOffset":"-17.5","parent":[{"index":-1}]},
{"index":1,"nodeOffset":"16.49 5","parent":[{"index":0}]},
{"index":2,"nodeOffset":"-51.49 5","parent":[{"index":0}]}
],
"config":{
"algorithm":"Get partition tree (McKay)",
"useRefine":false,
"typeCanon":"matrix",
"useMcr":false,
"traceTree":true
}}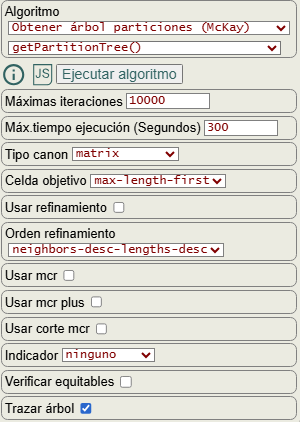
En la Figura vemos las opciones para ejecutar getPartitionTree(). Con máximas iteraciones controlamos que el algoritmo no se ejecute en un tiempo no controlable, algo que aplica a todos los algoritmos como ya hemos visto en temas anteriores. En cualquier caso podemos limitarlo con máximo tiempo ejecución con un valor de 300 segundos por defecto. Con Tipo canon que puede ser matrix, matrixNumber y edges especificamos que estructura vamos a usar para manejar el etiquetado canónico. En el ejemplo usamos matrix como la matriz de adyacencia, pero luego explicaremos en siguientes apartados que la opción de aristas (edges) es más eficiente. La opción celda objetivo sirve para especificar que celda con más de un elemento usaremos para fijar un vértice. La última opción trazar árbol aparece activada y nos devolverá el árbol de particiones en formato JSON que veremos después, así como otras cosas que nos ayudan a entender la ejecución.
La opción verificar equitables aparece desactivada y la explicaremos en un tema posterior. El resto de opciones aparecen desactivadas pues son para la poda con automorfismos y con indicadores que también explicaremos en temas posteriores, pues en este tema sólo nos vamos a centrar en generar el árbol de particiones sin ningún tipo de podas.
Con la ejecución obtenemos el siguiente resultado:
Time: 1 ms
Obtener árbol particiones (McKay): {
1
"useRefine":false,"orderRefine":"neighbors-desc-lengths-desc",
"targetCell":"max-length-first","typeCanon":"matrix","useMcr":false,
"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
2
"timeTotal":1,"timeIni":0,"timeRef":0,
"iter":13,"refine":0,"indexTree":9,
"leaves":6,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
3
"firstCanonicalPartition":[[0],[1],[2]],
"firstCanon":true,
"canonicalPartition":[[0],[1],[2]],
"firstCanonicalLabel":"011100100",
"canonicalLabel":"011100100",
"canonicalIndicator":null,
4
"nodes":
[[[-1,[],[]]],
[[0,[],[]],[0,[],[]],[0,[],[]]],
[[0,[],[],"f*"],[0,[],[],"=(1 2)"],[1,[],[],"<"],[1,[],[],"<"],[2,[],[],"<"],[2,[],[],"<"]]],
"nodeBest":[2,0],
5
"mcr":null,
"fixMcr":null,
"lastEqual":false,"rebuiltMcr":0,"nonRebuiltMcr":0,
6
"tree":[{"index":0,"value":"(0 1 2)","parent":-1},
{"index":1,"value":"(0)(1 2)","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(2)","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(2)(1)","parent":[{"index":1,"value":"2"}]},
{"index":4,"value":"(1)(0 2)","parent":[{"index":0,"value":"1"}]},
{"index":5,"value":"(1)(0)(2)","parent":[{"index":4,"value":"0"}]},
{"index":6,"value":"(1)(2)(0)","parent":[{"index":4,"value":"2"}]},
{"index":7,"value":"(2)(0 1)","parent":[{"index":0,"value":"2"}]},
{"index":8,"value":"(2)(0)(1)","parent":[{"index":7,"value":"0"}]},
{"index":9,"value":"(2)(1)(0)","parent":[{"index":7,"value":"1"}]}],
7
"automorphisms":[[1,[[0],[1,2]]]],
"automorphismsPlus":0}Explicamos brevemente las distintas partes del resultado anterior que hemos separado en partes y numerado para explicarlo mejor a continuación:
- Replica a efectos informativos las opciones que se pasaron al algoritmo y que vimos en la Figura.
- Recuento de tiempos de ejecución, iteraciones (
iter), veces que ejecuta el refinamiento (refine), nodos del árbol (indexTree), hojas del árbol (leaves), poda con automorfismos (prunningMcryprunningMcrBreak) y poda con indicadores (prunningIndicatorsyprunningIndicators2). - Registros que almacenan la primera partición canónica (
firstCanonicalPartition), la partición canónica (canonicalPartition), el primer etiquetado canónico (firstCanonicalLabel), el etiquetado canónico (canonicalLabel) y el indicador canónico (canonicalIndicator). Realmente lo que estamos buscando es el etiquetado canónico (canonical label). - En
nodesalmacena el árbol de nodos en un formato accesible para el algoritmo, estructura que explicaremos en el siguiente apartado. Es imprescindible para la poda con automorfismos (useMcr) y con indicadores (typeIndicator), pero aún sin esas podas se mantiene esa estructura. - En las variables
mcryfixMcrse almacena lo necesario para la poda con automorfismos. A efectos informativos se devuelven el estado de las variableslastEqual,rebuiltMcrynonRebuiltMcrque explicaremos en temas siguientes. - Si se activa la traza se devolverá en
treeel árbol de nodos en un formato JSON que podemos importar en la aplicación de grafos y que explicaremos en el siguiente apartado. - Con poda automorfismos (
useMcr) o bien con la traza activada, se devuelven los automorfismos que se encuentren.
Analizando el árbol de particiones
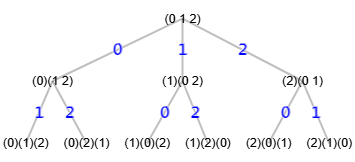
En la Figura vemos el árbol de particiones del ejemplo con el grafo estrella de 3 nodos que vimos en el apartado anterior.
Ya explicamos en el tema anterior sobre permutaciones en grafos que este grafo tiene 6 permutaciones, pero sólo hay 3 matrices de adyacencia diferentes que en ese tema expusimos que eran las siguientes:
Permutación Matriz adyacencia permutada ---------------------------------------- [0,1,2] [[0,1,1],[1,0,0],[1,0,0]] [0,2,1] [[0,1,1],[1,0,0],[1,0,0]] ---------------------------------------- [1,0,2] [[0,1,0],[1,0,1],[0,1,0]] [2,0,1] [[0,1,0],[1,0,1],[0,1,0]] ---------------------------------------- [1,2,0] [[0,0,1],[0,0,1],[1,1,0]] [2,1,0] [[0,0,1],[0,0,1],[1,1,0]]
Vemos que las hojas reflejan las mismas permutaciones. El proceso para generar el árbol es empezar con la partición inicial (0 1 2) que no es otra cosa que la lista de todos los nodos del grafo. Entonces se itera por ellos para fijar los vértices. Así en primer lugar fijamos el 0 con el primer nodo del segundo nivel (0)(1 2), lo que genera dos nodos u hojas en el tercer nivel (0)(1)(2) y (0)(2)(1) que se corresponden con las dos primeras permutaciones de la tabla anterior. En cada arista del árbol se indica en color azul el vértice que se fija. Al final resultará que el algoritmo generará todas las permutaciones posibles de la lista inicial de nodos [0, 1, 2].
Aunque luego explicaremos más sobre el etiquetado canónico, a medida que el algoritmo va llegando a hojas, irá guardando el etiquetado canónico que puede ser la matriz de adyacencia lexicográficamente mayor. De las 6 matrices de adyacencia que resultan en 3 equivalentes de la tabla anterior vemos que la primera es la mayor, por lo que esa será el etiquetado canónico del grafo.
Como explicamos antes, si activamos la traza la aplicación nos devuelve el JSON del árbol de particiones en el campo tree del resultado, al que le agregamos algunos estilos para mejor visualización como vemos en la Figura.
{"nodes":[
{"index":0,"value":"(0 1 2)","nodeOffset":"23 -5","parent":[{"index":-1}]},
{"index":1,"value":"(0)(1 2)","nodeOffset":"-4 -5","parent":[{"index":0,"value":"0"}]},
{"index":2,"value":"(0)(1)(2)","nodeOffset":"-4 -5","parent":[{"index":1,"value":"1"}]},
{"index":3,"value":"(0)(2)(1)","nodeOffset":"6 -5","parent":[{"index":1,"value":"2"}]},
{"index":4,"value":"(1)(0 2)","nodeOffset":"23 -5","parent":[{"index":0,"value":"1"}]},
{"index":5,"value":"(1)(0)(2)","nodeOffset":"16 -5","parent":[{"index":4,"value":"0"}]},
{"index":6,"value":"(1)(2)(0)","nodeOffset":"26 -5","parent":[{"index":4,"value":"2"}]},
{"index":7,"value":"(2)(0 1)","nodeOffset":"46 -5","parent":[{"index":0,"value":"2"}]},
{"index":8,"value":"(2)(0)(1)","nodeOffset":"36 -5","parent":[{"index":7,"value":"0"}]},
{"index":9,"value":"(2)(1)(0)","nodeOffset":"46 -5","parent":[{"index":7,"value":"1"}]}
],
"config":{
"rulesCss":"text[data-node]{font-size:5}",
"nodeRadius":0,
"lineColor":"rgba(0,0,0,0.25)",
"lineFontColor":"blue",
"lineWidth":2
}}Este JSON no es necesario para que el algoritmo encuentre el etiquetado canónico y sólo se devuelve si se activa el trazado. En cambio la aplicación usa la estructura del campo nodes para representar el árbol de nodos y que replicamos a continuación:
"nodes": [[[-1,[],[]]], [[0,[],[]],[0,[],[]],[0,[],[]]], [[0,[],[],"f*"],[0,[],[],"=(1 2)"],[1,[],[],"<"],[1,[],[],"<"],[2,[],[],"<"],[2,[],[],"<"]]], "nodeBest":[2,0],
Para visualizarlo mejor lo ponemos como sigue, agregando unos índices en azul:
0 [0[[-1,[],[]]],
1 [0[0,[],[]], 1[0,[],[]], 2[0,[],[]]],
2 [0[0,[],[],"f*"], 1[0,[],[],"=(1 2)"], 2[1,[],[],"<"],3[1,[],[],"<"], 4[2,[],[],"<"],5[2,[],[],"<"]]]
Cada entrada del array principal es un nivel, así este árbol tiene 3 niveles 0, 1 y 2 que también vemos en la Figura, pues no hay que olvidar que esta estructura de nodos es la misma que vemos en el JSON que presentamos en la Figura. Cada nodo es un array [indexParent, [], []] donde el índice indexParent indica que posición en el array del nivel inmediatamente superior es el padre de ese nodo. Así el nodo raíz tiene un índice -1 indicando que no tiene padre y es el raíz. Los dos subarrays que aparecen siempre vacíos en todos los nodos se utilizan para almacenar datos para la poda con automorfismos y con indicadores, algo que ahora no nos ocupa y que veremos en temas posteriores.
En el nivel 1 vemos que hay 3 nodos con índice que apunta al padre 0 del nivel anterior. Luego vemos en el nivel 2 que hay 6 nodos, tal que los dos primeros apuntan al nodo 0 del segundo nivel, los dos siguientes al 1 y los dos últimos al 2. Esos nodos de nivel 2 son las hojas del árbol y son las que generan las permutaciones finales tal como vemos en la Figura.
Como ya hemos dicho, realmente esta estructura en nodes no es necesaria para el caso de que no se usen podas con automorfismos o indicadores, pero en cualquier caso la aplicación no deja de usarla. Además si se activa la traza se agregará lo siguiente:
- En la primera hoja de la izquierda se agrega "f*" para informar que es el primer etiquetado canónico ("f" de first), que se guarda en
canonicalLabely también se almacena enfirstCanonicalLabel. - Cada vez que llegue a una hoja comparará la matriz de adyacencia de la permutación con el anterior
canonicalLabel, pudiendo ser "=", "<" y ">". En el ejemplo vemos que la segunda hoja es igual y tiene "=(1 2)", donde (1 2) es el automorfismo encontrado, algo que explicaremos en un tema posterior. El resto de hojas son todas menores "<". - Si hubiese alguna mayor pasaría a ser el nuevo etiquetado canónico, quitándose el asterisco de "f*" y traspasándose a ese nodo con ">*", de tal forma que el asterisco indica el nodo con el etiquetado canónico. Recordamos que estas anotaciones son a efectos informativos solamente, pues para la aplicación se almacena en el campo
"nodeBest":[2,0]el nodo con el etiquetado canónico, que se encuentra en el nivel 2, posición 0.
Tipo de canon matriz de adyacencia
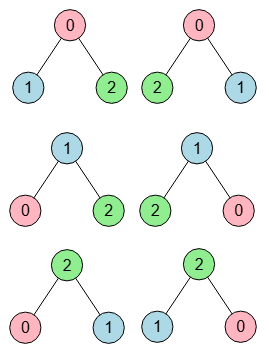
Ya comentamos que el grafo estrella con 3 nodos tiene 6 permutaciones con sólo 3 matrices de adyacencia distintas, correspondiéndose a 3 simetrías que se establecen con un nodo distinto en el centro, tal como vemos en la Figura y tambiém vimos en un tema anterior Permutaciones en grafos.
Esas permutaciones y matrices de adyacencia son las siguientes:
Permutación Matriz adyacencia permutada --------------------------------------------- [0,1,2] [[0,1,1],[1,0,0],[1,0,0]] [0,2,1] [[0,1,1],[1,0,0],[1,0,0]] --------------------------------------------- [1,0,2] [[0,1,0],[1,0,1],[0,1,0]] [2,0,1] [[0,1,0],[1,0,1],[0,1,0]] --------------------------------------------- [1,2,0] [[0,0,1],[0,0,1],[1,1,0]] [2,1,0] [[0,0,1],[0,0,1],[1,1,0]]
En la aplicación podemos usar como tipo de canon la matriz de adyacencia. Entonces si la aparición de las permutaciones en la aplicación son las tres matrices de adyacencia anteriores en ese orden, realmente trabajaremos con su representación en una cadena de "0" y "1" como sigue:
[[0,1,1],[1,0,0],[1,0,0]] "011100100" [[0,1,0],[1,0,1],[0,1,0]] "010101010" [[0,0,1],[0,0,1],[1,1,0]] "001001110"
Entonces se trata de guardar como etiquetado canónico la mayor de esas cadenas. Al principio almacenamos la primera como el mejor canon. Cuando aparezca la segunda vemos que "011100100" > "010101010" observándose que el tercer dígito establece esa comparación, con lo que seguimos manteniendo la primera matriz de adyacencia como mejor canon. Cuando aparezca la tercera resultará también que "011100100" > "001001110" con lo que finalizamos con mejor canon la primera matriz de adyacencia.
En el resultado obtenido que vimos más arriba, observamos el campo "firstCanonicalLabel": "011100100" como primer canon y "canonicalLabel": "011100100" como el más grande, que en este ejemplo se mantiene igual que el primero:
... "firstCanonicalPartition":[[0],[1],[2]], "firstCanon":true, "canonicalPartition":[[0],[1],[2]], "firstCanonicalLabel":"011100100", "canonicalLabel":"011100100", "canonicalIndicator":null, "nodes": [[[-1,[],[]]], [[0,[],[]],[0,[],[]],[0,[],[]]], [[0,[],[],"f*"],[0,[],[],"=(1 2)"],[1,[],[],"<"],[1,[],[],"<"],[2,[],[],"<],[2,[],[],"<"]]], "nodeBest":[2,0], ...
El árbol nodes tendrá las hojas al final como ya hemos explicado, que en caso de activar traceTree, nos agregará "f" de first, "=", "<", ">" y "*" como indicativo de mejor canon con el que se comparan los otros. Así el primero tiene "f*", el segundo "=" pues tiene la misma matriz de adyacencia y los cuatro restantes son menores "<".
[-1,[],[]]
[0,[],[]]
[0,[],[],"f*"]
[0,[],[],"=(1 2)"]
[0,[],[]]
[1,[],[],"<"]
[1,[],[],"<"]
[0,[],[]]
[2,[],[],"<]
[2,[],[],"<"]A veces vamos a exponer ese campo nodes visualmente en posición vertical, pues así se observa mejor las ramas del árbol de particiones.
Tipo de canon matriz de adyacencia en formato numérico
En lugar de comparar cadenas de "01" de las matrices de adyacencia podemos intentar convertirlas en un formato numérico, con el tipo de canon matrixNumber, usando el formato binario de números de JavaScript, pues algo como 0b011 es el número 3 en decimal. Así que las tres matrices de adyacencia del ejemplo resultan en estos valores
[[0,1,1],[1,0,0],[1,0,0]] [0b011, 0b100, 0b100] = [3,4,4] [[0,1,0],[1,0,1],[0,1,0]] [0b010, 0b101, 0b010] = [2,5,2] [[0,0,1],[0,0,1],[1,1,0]] [0b001, 0b001, 0b110] = [1,1,6]
Vemos que [3, 4, 4] > [2, 5, 2] y también [3, 4, 4] > [1, 1, 6], con lo que volvemos a tener la primera matriz de adyacencia como mejor canon. Obviamente ahora el número de comparaciones que hay que hacer resulta menor pues con la matriz de adyacencia hay que comparar n×n = n2 posiciones en el peor caso, pero con matrixNumber sólo tenemos que hacer n comparaciones en el peor caso. Teóricamente debería ser más eficiente, sin embargo en la práctica no hay diferencia significativa con el tipo de canon con la matriz de adyacencia en formato cadena.
Además este tipo de canon matrixNumber está limitado a matrices con un máximo n = 1023, pues el máximo número binario que podemos representar en JavaScript es 0b111···111 con 1023 dígitos 1, resultando ser el número 8.98846567431158e+307, pues si le agregamos otro dígito "1" entonces resulta Infinity. Ver más sobre esto en el tema sobre los números en JavaScript preguntándonos dónde empieza Infinity.
Tipo de canon aristas
Al llegar a cada hoja del árbol hemos de compararla con la etiqueta canónica, con lo que este proceso de comparación es crucial en el control de tiempos del algoritmo. Buscando la forma de reducir esos tiempos, también usamos como canon la lista de aristas. Un grafo no dirigido con n nodos tiene una matriz de adyacencia con un tamaño de n2 posiciones y su lista de aristas será como mucho de un tamaño de n(n-1)/2, lo cual sucede para un grafo completo. Así que siempre será menor que n2 y es por lo que conviene intentar usar las listas de aristas para el etiquetado canónico. Para el ejemplo del grafo de estrella con 3 nodos teníamos las siguientes:
Permutación Matriz adyacencia permutada Lista aristas ------------------------------------------------------- [0,1,2] [[0,1,1],[1,0,0],[1,0,0]] [[0,1],[0,2]] [0,2,1] [[0,1,1],[1,0,0],[1,0,0]] [[0,1],[0,2]] ------------------------------------------------------- [1,0,2] [[0,1,0],[1,0,1],[0,1,0]] [[0,1],[1,2]] [2,0,1] [[0,1,0],[1,0,1],[0,1,0]] [[0,1],[1,2]] ---------------------------------------------------------- [1,2,0] [[0,0,1],[0,0,1],[1,1,0]] [[0,2],[1,2]] [2,1,0] [[0,0,1],[0,0,1],[1,1,0]] [[0,2],[1,2]]
Usando la representación en cadena de las 3 matrices de adyacencia tenemos:
"011100100" [[0,1],[0,2]] "010101010" [[0,1],[1,2]] "001001110" [[0,2],[1,2]]
Observamos que lexicográficamente las matrices de adyacencia se ordenan "011100100" > "010101010" > "001001110" en el mismo orden en que aparecen en la tabla anterior, tal como vimos en apartados anteriores. Mientras que las listas de aristas se ordenan al revés [[0,2],[1,2]] > [[0,1],[1,2]] > [[0,1],[0,2]]. Esto será cierto siempre que se ordenen las aristas en orden ascendente, con lo que el orden lexicográfico entre dos matrices de adyacencia es el inverso del orden lexicográfico de sus listas de aristas.
Recordemos que una arista no dirigida como u-v con u<v también podemos representarla como v-u, pues en la matriz de adyacencia aparecerá m[u][v]=1 y m[v][u]=1. En la lista de aristas en forma compacta usamos la primera u-v como representativa, que en formato de Array es [u, v]. Si además ordenamos toda la lista de aristas e0, ... ei, ... ej, ... de tal forma que con i<j aparecerá primera la arista ei = [ui, vi] y después ej = [uj, vj] en base a que ui < uj o bien ui = uj ∧ vi < vj.
Esto nos simplifica en JavaScript con una comparación entre Arrays [u,v]>[x,y] pues los coerciona como si hiciéramos [u,v].toString()>[x,y].toString() realizando una comparación alfanúmerica. Así si tenemos [[0,1], [0,2]] y [[0,1],[0,10]], las primeras aristas son iguales y al comparar las segundas resulta [0,2]>[0,10] pues alfanuméricamente "2">"10".

Usando el grafo CFI-20 con 200 nodos y 300 aristas que vemos en la Figura, ejecutamos el árbol de particiones con todas las podas posibles y con los tres tipos de canon, matriz de adyacencia (matrix), matriz numérica (matrixNumber) y aristas (edges), obteniéndose estos resultados donde, a excepción de los tiempos de ejecución, se obtienen los mismos resultados numéricos:
Time: 238 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first",
"typeCanon":"matrix","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":238,"timeIni":5,"timeRef":122,
"iter":727,"refine":292,"indexTree":291,
"leaves":43,
"prunningMcr":271,"prunningMcrBreak":119,
"prunningIndicators":0,"prunningIndicators2":84,
...
Time: 236 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first",
"typeCanon":"matrixNumber","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":236,"timeIni":5,"timeRef":124,
"iter":727,"refine":292,"indexTree":291,
"leaves":43,
"prunningMcr":271,"prunningMcrBreak":119,
"prunningIndicators":0,"prunningIndicators2":84,
...
Time: 144 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first",
"typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"lengths",
"timeTotal":144,"timeIni":5,"timeRef":126,
"iter":727,"refine":292,"indexTree":291,
"leaves":43,
"prunningMcr":271,"prunningMcrBreak":119,
"prunningIndicators":0,"prunningIndicators2":84,
...Vemos que el tiempo total ("totalTime") del último con tipo de canon aristas es de 144 ms, inferior a los otros dos. Vemos que el tiempo de inicialización "timeIni":5 es el mismo para los tres y el que pasa en el proceso de refinamiento "timeRef" es similar en los tres. El resto de tiempo se ocupa en otros procesos, como el de comparar cánones de etiquetado, observando que con aristas ocupa menos tiempo.
Puede descargar el grafo de la Figura con el enlace cfi-20.txt que viene en formato de texto DIMACS e importarlo en la aplicación.
El tipo de canon usado no debe interferir en el etiquetado canónico. Para probarlo vamos a usar el grafo de la Figura (que puede descargar con graph-sample.txt en JSON para importar en la aplicación) usando el algoritmo getCanonicalGraph() que veremos más abajo y que obtiene el grafo canónico mediante el algoritmo getPartitionTree(), en este caso sin usar refinamiento ni podas. Se obtiene lo siguiente para cada tipo de canon usado matrix, matrixNumber y edges:
typeCanon = matrix Time: 535 ms Obtener grafo canónico (McKay): [[0,1,1,1,1,0,0,0], [1,0,1,1,0,1,0,0], [1,1,0,1,0,0,1,0], [1,1,1,0,0,0,0,1], [1,0,0,0,0,1,0,0], [0,1,0,0,1,0,0,0], [0,0,1,0,0,0,0,1], [0,0,0,1,0,0,1,0]] typeCanon = matrixNumber Time: 577 ms Obtener grafo canónico (McKay): [[0,1,1,1,1,0,0,0], [1,0,1,1,0,1,0,0], [1,1,0,1,0,0,1,0], [1,1,1,0,0,0,0,1], [1,0,0,0,0,1,0,0], [0,1,0,0,1,0,0,0], [0,0,1,0,0,0,0,1], [0,0,0,1,0,0,1,0]] typeCanon = edges Time: 389 ms Obtener grafo canónico (McKay): [[0,1],[0,2],[0,3],[0,4],[1,2],[1,3],[1,5],[2,3],[2,6],[3,7],[4,5],[6,7]]
[[0,1,1,1,1,0,0,0], [1,0,1,1,0,1,0,0], [1,1,0,1,0,0,1,0], [1,1,1,0,0,0,0,1], [1,0,0,0,0,1,0,0], [0,1,0,0,1,0,0,0], [0,0,1,0,0,0,0,1], [0,0,0,1,0,0,1,0]]
Se observa que con los tipos de canon matrix y matrixNumber se obtiene la misma matriz de adyacencia. Con el tipo edges se obtiene una lista de aristas que si la importamos en la aplicación y vemos su matriz de adyacencia (a la izquierda) comprobaremos que se corresponde con la misma matriz de adyacencia.
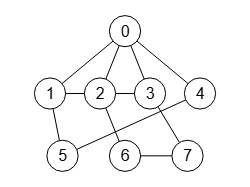
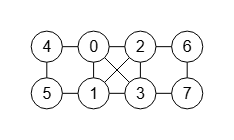
Al importar en la aplicación el grafo canónico mediante la matriz de adyacencia canónica o la lista de aristas canónica anterior, aparece con las posiciones por defecto que vemos en la Figura. Si posicionamos los nodos como aparece en la segunda Figura observamos que se produce la permutación 1,6,2,5,0,7,3,4 con respecto al grafo inicial de la Figura.
Esa permutación puede encontrarse ejecutando el árbol de particiones getPartitionTree() sobre el grafo inicial sin aplicar refinamiento ni podas obteniendo "canonicalPartition": [[1],[6],[2],[5],[0],[7],[3],[4]] que es la hoja con la permutación 1,6,2,5,0,7,3,4 que sirve como canónica:
Time: 396 ms
Obtener árbol particiones (McKay): {
"useRefine":false,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":false,"useMcrPlus":false,"useMcrBreak":false,"typeIndicator":"none",
"timeTotal":396,"timeIni":0,"timeRef":0,
"iter":98241,"refine":0,"indexTree":69280,
"leaves":40320,
"prunningMcr":0,"prunningMcrBreak":0,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[0],[1],[2],[3],[4],[5],[6],[7]],
"firstCanon":false,
"canonicalPartition":[[1],[6],[2],[5],[0],[7],[3],[4]],
"firstCanonicalLabel":[[0,1],[0,7],[1,2],[1,5],[1,6],[2,3],[2,5],[2,6],[3,4],[4,5],[5,6],[6,7]],
"canonicalLabel":[[0,1],[0,2],[0,3],[0,4],[1,2],[1,3],[1,5],[2,3],[2,6],[3,7],[4,5],[6,7]],
...Mediante el uso del ajuste visual para posicionar nodos, obtenemos las posiciones del grafo inicial y luego las ordenamos manualmente siguiendo la permutación 1,6,2,5,0,7,3,4, trasladando esa nueva lista de posiciones al grafo permutado para posicionar exactamente cada nodo en el mismo lugar del nodo que se permuta:
Inicial: 0 1 2 3 4 5 6 7 Permutación: 1,6,2,5,0,7,3,4 Posiciones de nodos del grafo inicial 0 1 2 3 4 5 6 7 [[18.75, 18.75], [37.5, 18.75], [56.25, 18.75], [75, 18.75], [75, 37.5], [56.25, 37.5], [37.5, 37.5], [18.75, 37.5]] Posiciones de nodos del grafo permutado 1 6 2 5 0 7 3 4 [[37.5, 18.75], [37.5, 37.5], [56.25, 18.75], [56.25, 37.5], [18.75, 18.75], [18.75, 37.5], [75, 18.75], [75, 37.5]]
Ya de paso con el grafo de la Figura aprovechamos para obtener el árbol de particiones getPartitionTree() usando refinamiento ("useRefine":true) y podas con automorfismos ("useMcr":true, "useMcrBreak":true) que explicaremos en temas posteriores, obteniéndose el siguiente resultado:
Time: 1 ms
Obtener árbol particiones (McKay): {
"useRefine":true,"orderRefine":"neighbors-desc-lengths-desc","targetCell":"max-length-first","typeCanon":"edges","useMcr":true,"useMcrPlus":false,"useMcrBreak":true,"typeIndicator":"none",
"timeTotal":1,"timeIni":1,"timeRef":0,
"iter":10,"refine":6,"indexTree":5,
"leaves":3,
"prunningMcr":2,"prunningMcrBreak":1,
"prunningIndicators":0,"prunningIndicators2":0,
"firstCanonicalPartition":[[1],[2],[5],[6],[3],[4],[7],[0]],
"firstCanon":true,
"canonicalPartition":[[1],[2],[5],[6],[3],[4],[7],[0]],
"firstCanonicalLabel":[[0,1],[0,2],[0,3],[0,7],[1,2],[1,3],[1,4],[2,3],[2,5],[3,6],[4,5],[6,7]],
"canonicalLabel":[[0,1],[0,2],[0,3],[0,7],[1,2],[1,3],[1,4],[2,3],[2,5],[3,6],[4,5],[6,7]],
"canonicalIndicator":null,
"nodes":
[[[-1,[],[]]],
[[0,[1],[]],[0,[2],[]]],
[[0,[1,2],[]],[0,[1,5],[]],[1,[2,1],[]]]],
"nodeBest":[2,0],
...Podemos ver las siguientes diferencias entre este resultado y el obtenido sin refinamiento ni podas que vimos más arriba:
| Resultado | Sin podas | Con podas Refine+mcr |
|---|---|---|
| Time | 396 ms | 1 ms |
| Iterations | 98241 | 10 |
| Index tree | 69280 | 5 |
| Leaves | 40320 | 3 |
| Canonical partition | [[1],[6],[2],[5],[0],[7],[3],[4]] | [[1],[2],[5],[6],[3],[4],[7],[0]] |
| Canonical label | [[0,1],[0,2],[0,3],[0,4],[1,2],[1,3],[1,5],[2,3],[2,6],[3,7],[4,5],[6,7]] | [[0,1],[0,2],[0,3],[0,7],[1,2],[1,3],[1,4],[2,3],[2,5],[3,6],[4,5],[6,7]] |
La eficiencia es muy significativa. Observe como el árbol sin podas tiene 8! = 40320 hojas pues son todas las permutaciones con 8 nodos, mientras que con podas sólo necesitamos obtener 3 hojas. En ambos casos no se obtiene el mismo etiquetado canónico, pero eso no es importante puesto que para comprobar si dos grafos son isomorfos obtendremos el árbol de particiones de ambos grafos usando las mismas opciones para el algoritmo getPartitionTree(), de tal forma que si ambos etiquetados canónicos son iguales serán isomorfos o no lo serán en otro caso.
Obtener grafo canónico getCanonicalGraph()
El JavaScript para ejecutar el algoritmo getCanonicalGraph() se expone a continuación usando la versión definitiva de getPartitionTree(), devolviendo la lista de aristas sin modificar o actuando sobre la matriz de adyacencia en su caso como hemos explicado en apartados anteriores.
function getCanonicalGraph({matrix=[], useRefine=true, orderRefine="neighbors-desc-lengths-desc", typeCanon="edges", targetCell="max-length-first",
useMcr=true, useMcrPlus=false, useMcrBreak=false, typeIndicator="none"}){
let result = [];
try {
if (!verifyMode01(matrix)) throw new Error(`(getCanonicalGraph) Matrix must come in mode 0/1`);
let n = matrix.length;
let temp = getPartitionTree({matrix, useRefine, orderRefine, typeCanon, targetCell, useMcr, useMcrPlus, useMcrBreak, typeIndicator});
if (typeof temp==="string") throw new Error(temp);
if (typeCanon==="edges") {
result = temp.canonicalLabel;
} else if (typeCanon==="matrix") {
let arr = temp.canonicalLabel.split("").map(v => +v);
result = Array.from({length: n}, () => []);
for (let i=0; i<arr.length; i++) {
result[i%n].push(arr[i]);
}
} else {
result = temp.canonicalLabel.map(v => Number(v).toString(2).padStart(n, "0").split("").map(v => +v));
}
} catch(e){result = e.message}
return result;
}Código JavaScript para ejecutar el DFS básico para obtener el etiquetado canónico
El siguiente pseudocódigo resume esta versión básica del algoritmo, donde el resultado es simplemente result = {canonicalLabel:null}
Function getPartitionTreeDfs(matrix, partition, result)
If partition.length===0 // INITIAL STEPS
partition = [[0],[1],[2],...,[n-1]]
End If
cell = Select target cell
While cell.size>0
// Fix vertex
vertex = minimum of cell
indexCell = position of vertex in cell
delete vertex in cell
partition = individualize vertex in partition
If partition.length===n // DISCRETE PARTITION
canon = get canonical label with this permutation
If result.canonicalLabel===null
result.canonicalLabel = canon
Else
// Compare canon
If canon > result.canonicalLabel
result.canonicalLabel = canon
result.lastEqual = false
End If
End If
Else
getPartitionTreeDfs(matrix, partition, result)
End If
End While
return result
End FunctionTenemos una función auxiliar getCanon() para obtener el etiquetado canónico a partir de una partición discreta, como veremos después.
// Algorithm for get canonical label
function getCanon({matrix=[], edgesGraph=[], partition=[]}) {
let canon = [];
try {
let indexes = partition.map(v => v[0]);
let edges = edgesGraph.length>0 ? edgesGraph : matrix.edges;
for (let edge of edges) {
let [v, w] = edge;
let [i, j] = [indexes.indexOf(v), indexes.indexOf(w)];
canon.push(i<j ? [i, j] : [j, i]);
}
canon = canon.map(v => v[0]>v[1] ? [v[1],v[0]] : [v[0],v[1]]).toSorted((v,w) => (v[0]===w[0]) ? v[1]-w[1] : v[0]-w[0]);
} catch(e){canon = e.message}
return canon;
}A continuación mostramos el JavaScript de getPartitionTreeDfs(), recursivo de búsqueda en profundidad para obtener el etiquetado canónico. Se ejecuta en la consola del navegador usando getPartitionTreeDfs({edges:[[0,1],[0,2]], n:3}) pasándose la lista de aristas del grafo Star 4 del ejemplo (o cualquiera otra lista de aristas de otro grafo) y produciendo el resultado {"canonicalLabel":[[0,1],[0,2]]} con el etiquetado canónico [[0,1],[0,2]].
Este código sólo sirve para efectos demostrativos, siendo un base sobre el que agregaremos en la versión final todo lo necesario para implementar el algoritmo de McKay getPartitionTree() como veremos en siguientes temas. Se puede copiar o descargar en el enlace get-partition-tree-dfs.txt y pegarlo en la consola del navegador pàra ejecutarlo.
// Algorithm with the sole purpose of showing how to generate the partition tree with a
// recursive DFS.
// Use in the browser console with this execution for Star 3 graph example
function getPartitionTreeDfs({edges=[], n=0, partition=[], result={canonicalLabel:null}}) {
try {
if (partition.length===0) partition = [Array.from({length:n}, (v,i) => i)];
// Select target cell
let index = partition.findIndex(v => v.length>1);
if (index>-1) {
let cell = partition[index];
let sCell = new Set(cell);
while (sCell.size>0) {
// Fix vertex
let vertex = Math.min(...sCell);
let indexCell = cell.indexOf(vertex);
sCell.delete(vertex);
let part = partition.map(v => v.slice(0));
part[index] = cell.toSpliced(indexCell, 1);
part = part.toSpliced(index, 0, [vertex]);
if (part.length===n) {
// Get canonical label with this permutation
if (temp = getCanon({edgesGraph:edges, partition:part}), typeof temp==="string") throw new Error(temp);
let canon = temp;
if (result.canonicalLabel===null) {
result.canonicalLabel = canon;
} else {
// Compare canon
for (let i=0; i<canon.length; i++) {
if (canon[i]<result.canonicalLabel[i]) {
result.canonicalLabel = canon;
break;
}
}
}
} else {
let res = getPartitionTreeDfs({edges, n, partition:part, result});
if (typeof res==="string") throw new Error(res);
}
}
}
} catch(e){result = "getPartitionTreeDfs(): " + e.message}
return result;
}
// The result should be: {"canonicalLabel":[[0,1],[0,2]]}
console.log(JSON.stringify(getPartitionTreeDfs({edges:[[0,1],[0,2]], n:3})));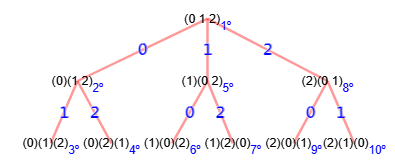
Vemos que es un recursivo tipo búsqueda en profundidad (DFS), igual quel el agoritmo getDepthFirstSearchRecursive. Si al árbol de particiones de la Figura le aplicamos este algoritmo de búsqueda en profundidad, observamos en la Figura el orden de visita de los nodos, de arriba a abajo y de izquierda a derecha, viendo por ejemplo que en la primera rama se indican las posiciones 1º, 2º y 3º de visita a los tres primeros nodos hasta llegar a la primera hoja del árbol.
Usa como estructura del grafo la lista de aristas en el argumento edges. Sin embargo la versión final usará la matriz de adyacencia para ser coherente con todos los algoritmos de la aplicación. La partición (partition) inicial es vacía, algo que se detecta al inicio, construyéndola entonces con una única celda con la lista de nodos. Así en el ejemplo tendríamos partition = [[0,1,2]], conocida como partición unitaria.
A continuación seleccionamos la celda objetivo (select target cell) en la partición entre todas las celdas no triviales, que son las de tamaño mayor que uno. Para este algoritmo sin refinamiento siempre será la primera que encuentre, pero como veremos en siguientes temas, puede darse varias opciones, como la primera de mayor tamaño.
Antes de un bucle while convertimos la celda en un objeto de JavaScript con let sCell = new Set(cell), pues iremos extrayendo vértices de menor número y los iremos quitando con sCell.delete(vertex), así que este bucle finalizará cuando sCell esté vacío. Hacemos una copia de la partición con let part = partition.map(v => v.slice(0)) y quitamos el vértice de la celda y lo ubicamos en un celda unitaria o trivial previa. Así vemos que partiendo de partition = [[0,1,2]] llegamos en el primer paso de la primera rama a part = [[0],[1,2]]. Este proceso se llama fijar un vértice (fix vertex).
Si esta nueva partición part no tiene todas las celdas unitarias o triviales, volvemos a llamar recursivamente al algoritmo con la nueva partición. En otro caso la partición es discreta, con todas las celdas triviales así que la longitud de la partición será igual al total de vértices del grafo (part.length===n).
Con la partición discreta llegamos a una hoja del árbol, teniendo entonces una permutación del grafo. Como el grafo de ejemplo tiene 3 nodos habrán 3! = 6 hojas. Vemos que la primera hoja es [[0],[1],[2]] que viene a ser la permutación identidad 0,1,2, la segunda es [[0],[2],[1]] presentando la permutación 0,2,1 y así sucesivamente. Ahora obtenemos el etiquetado canónico (canonical label) de esa permutación en el grafo, para lo cual podríamos usar el algoritmo operatePermuteGraph() usando la opción desde aristas, pero que en el algoritmo transcribimos esa parte de código en la función auxiliar getCanon(), pasando la lista de aristas del grafo y la partición, obteniendo una lista de aristas del grafo permutado en la variable canon. Para poder comparar dos cánones ordenamos canon tal como explicamos más arriba.
El algoritmo se inicia con el resultado result={canonicalLabel:null} pues lo que vamos a devolver es canonicalLabel que es el etiquetado canónico. En la primera hoja ese result.canonicalLabel será nulo y lo guardamos. Pero en las siguientes hojas lo reemplazaremos sólo si la matriz de adyacencia del grafo permutado es lexicográficamente mayor que la del etiquetado canónico previo que tenemos almacenado, algo que hacemos en el trozo de código compare canon. Tal como explicamos más arriba, el orden lexicográfico de la lista de aristas es el inverso de la matriz de adyacencia, por eso comparamos con canon[i] y result.canonicalLabel[i] que cada arista NO sea menor que su correspondiente canónica en el mismo orden, pues si es menor entonces ya todo el canon actual es menor que el canónico anterior y, a la inversa, la matriz canon actual es mayor que la matriz canónica anterior.
Después de obtener las n! permutaciones del grafo, el algoritmo devolverá el etiquetado canónico almacenado en result.canonicalLabel, etiquetado que nos permitirá comprobar si dos grafos son isomorfos pues debe obtenerse el mismo etiquetado.