Web Tools online: Visor binario
Un visor binario para observar los bytes de un archivo
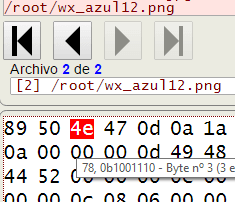
Si queremos estudiar como se conforman los bytes en un archivo, por ejemplo un PNG de imagen, necesitaremos una herramienta para observar el contenido. Con este visor binario podemos cargar un archivo del ordenador y ver sus bytes con varias vistas como binaria, hexadecimal y decimal. Por ejemplo en la Figura se observan los hexadecimales de los primeros bytes de un archivo PNG.
Los cuatro primeros bytes de un PNG son 137, 080, 078, 071 expresados en decimales y 89, 50, 4e, 47 en hexadecimal. Si abrimos un PNG con un visor de texto veremos al inicio el texto "PNG", pues son los caracteres UNICODE que se corresponden con esos valores. Pero un visor de texto no descubre otros caracteres que son de control, como los rangos [0, 32] y [128, 160]. En esos casos o bien no se presentan visualmente o lo hacen con espacios.
En todo caso esta herramientas ofrece también vistas como texto (usando UNICODE en sus códigos 0-255) y en CP437 (un tipo de ASCII extendido). Esa es la página de códigos que se usaba en el primitivo MSDOS, de la cual existe una transposición a Unicode y que también puede verse en en la página de Wikipedia CP437. Las bytes en decimal 0, 32 y 255 son originalmente espacios blancos en CP437, pero aquí usamos los caracteres ⬚, ⬜ y ⬒ respectivamente con objeto de observarlos mejor.
Usando ArrayBuffer y TypedArray para leer bytes de un archivo
La herramienta es muy simple y no se necesitan más explicaciones. Pero quiero aprovechar este tema para exponer como hice para leer los bytes de un archivo.
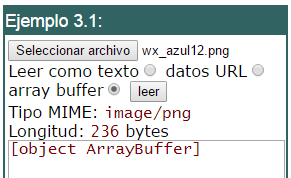
En el tema File API: FileReader que expone como usar un <input type="file"> hay un ejemplo para leer un archivo como array buffer (Figura). Se trata de recuperar el archivo como un conjunto de bits sin estructura predefinida, almacenándose en el objeto de JavaScript ArrayBuffer.
En el ejemplo de ese tema nos limitábamos a recuperar el ArrayBuffer pero no hacíamos nada con sus datos. Pues para ver el contenido de un ArrayBuffer hay que aplicar una vista de los datos. Podemos usar los TypedArray que son un conjunto de objetos de JavaScript que definen estructuras de datos, como Int32Array que es una vista como enteros de 32 bits o Uint32Array que son enteros sin signo también de 32 bits. Para ver bytes (8 bits) deberemos usar Uint8Array.
En el siguiente ejemplo podrá visualizar los bytes de un archivo de su ordenador. Se limita la presentación a los primeros 200 bytes para no cargar en exceso la página con un archivo muy grande. En la herramienta esto se controla con un paginado con un tamaño de página configurable, pero en este ejemplo ese límite no es configurable.
Ejemplo: Recuperando bytes desde un archivo
Puede ver el código completo del ejemplo en el enlace anterior. En lo que sigue explicaremos lo más importante de ese código. El elemento <input type="file" id="input-filebytes"/> nos permite cargar un archivo. En su propiedad files tendremos una colección de archivos, donde files[0] nos devolverá una referencia al primer archivo. Es una colección para el caso que usemos el atributo multiple que permite cargar varios archivos. Pero al no incluir el atributo obtenemos una colección con un único archivo.
La operación es muy simple. Abrimos un nuevo FileReader para leer el achivo usando el modo readAsArrayBuffer. Con un evento load obtenemos el buffer y una vista del mismo con Uint8Array. Tendremos un Array con enteros en el rango [0, 255] que son los valores decimales de los bytes del archivo. La función verBytes() presentará esos bytes en binario, hexadecimal, decimal y texto.
let bytes = [];
const MAX_BYTES = 200;
document.getElementById("input-filebytes").addEventListener("change",
(event) => {
let files = event.target.files;
if (files.length > 0) {
let file = files[0];
let vista = new FileReader();
vista.addEventListener("load", (event) => {
let buffer = event.target.result;
bytes = new Uint8Array(buffer);
//Recorta los primeros 200 bytes
bytes = bytes.slice(0, MAX_BYTES);
verBytes();
});
vista.readAsArrayBuffer(file);
}
});
La función verBytes() tomará el Array con enteros [0, 255] y usando el método reduce() lo convertimos en un string binario, hexadecimal o decimal usando la función toString(). Rellenamos con ceros a la izquierda para que todos los bytes tengan la misma longitud y así se presente en forma de columnas en el contenedor de la página. El string bytesVista será el que finalmente se vierta en el contenedor.
// base será 2 para binario, 16 hexadecimal y 10 decimal
// digitos será 8 binario, 2 hexadecimal y 3 decimal
bytesVista = bytes.reduce((p,v) => {
let item = v.toString(base);
item = "0".repeat(digitos - item.length) + item;
return p + item + " ";
}, "");
Para presentar como texto CP437 tendremos un String como let cp437 = "⬚☺☻♥♦♣♠•◘..." que contiene los 256 caracteres de esa página de códigos CP437. Usando también reduce() convertimos el Array con los bytes en decimal a un string tomando los caracteres de la página de códigos.
bytesVista = bytes.reduce((p,v) => {
return p + cp437[v];
}, "");