La caché web
Razones para usar caché web
La caché web almacena copias de los recursos de una página web en el navegador o en servidores proxy con el objeto de evitar las limitaciones de la latencia y el ancho de banda. Ambos conceptos inciden sobre la velocidad de carga de una página. Al obtener una página o partes de ella desde las copias almacenadas en el navegador (o proxy) evitamos gastar conexiones con el servidor de origen y el ancho de banda queda disponible para otras acciones. Las páginas se cargan más rápido, algo que los usuarios apreciarán. Y especialmente en móviles, donde las conexiones con el servidor son más lentas. Un beneficio adicional es que reducimos la carga de trabajo del servidor al disminuir el número de solicitudes.
Enfrentarse con el cacheado no es fácil porque parece que perdemos un poco el control de nuestras páginas. El funcionamiento de la caché web es transparente para el usuario. El navegador no le avisa de que está viendo un contenido desde caché o desde el servidor web. Tememos que el usuario pueda estar viendo contenido desactualizado. Por otro lado la configuración de la caché web es un poco compleja porque hay varias formas de hacerlo. Y quizás es mejor no usar caché web que usar una mal configurada. Todo esto puede hacernos dudar sobre usar caché web.
Además si no implementamos el cacheado los navegadores pueden aún llevar a cabo mecanismos para cachear las páginas basados en heurísticas de uso. De hecho se intenta actualizar el protocolo HTTP 1.1 para incorpar esto, tal como puede verse en un reciente borrador que modifica la parte de Caching in HTTP, donde el apartado 4.2.2 Calculating Heuristic Freshness nos viene a decir que si el servidor no envía cabeceras de caché, el navegador podría determinar la fecha de caducidad con algún algoritmo y cachear la página. Pero cada navegador lo aplicará de una forma particular, lo que dará lugar a un distinto comportamiento.
Hay elementos HTML <meta http-equiv> que resultan inútiles para este propósito. Por ejemplo, el siguiente HTML pretende que una página no sea cacheada:
<!-- NOTA: Cachear desde el HTML no funciona. Hay que usar HTTP para una correcta caché. --> <meta http-equiv="pragma" content="no-cache" /> <meta http-equiv="cache-control" value="no-cache, no-store, must-revalidate" /> <meta http-equiv="expires" content="0">
Pero esto es ignorado por los navegadores y, especialmente, por los proxies pues en ningún caso leen el contenido HTML del documento. Por lo tanto debemos centrar toda nuestra atención en el cacheado del protocolo HTTP y no en estos elementos HTML.
Una breve lista de documentación que he consultado para este tema:
- Caching in HTTP 1.1 es el estándar que explica el funcionamiento.
- Web caching es un sitio especialmente dedicado a esto. El tutorial introductorio nos aclarará un montón de cosas.
- Optimize caching de Google Developers nos ayuda de una forma práctica a configurar la caché web.
- Best Practices for Speeding Up Your Web Site, apartado de Add an Expires or a Cache-Control Header, de Yahoo Developers, con una visión práctica para configurar caché web.
- Redbot es una herramienta en línea que diagnostica las cabeceras. No hay mucha documentación en este sitio. De hecho no he podido encontrar una mayor explicación sobre los posibles tipos de avisos, pero creo que son estos:
- Correcto (una marca verde de verificación).
- Informativo (un círculo azul con una "i" en su interior) supone que no hay errores pero pudiera darse una mejora para obtener un óptimo comportamiento.
- Aviso (una especie de banderín) alertando de que en ciertos casos puede ocasionarse un error.
- Error (una círculo rojo con un guion en su interior), un mal comportamiento que dará lugar a errores.
Cómo funciona la caché web
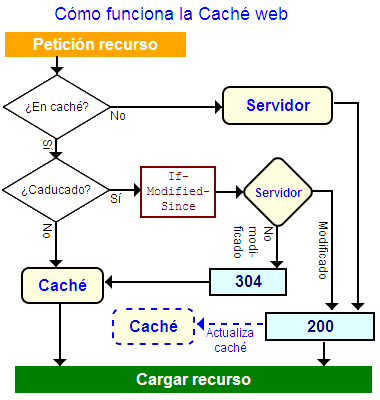
Los recursos de una página web son, principalmente, los archivos HTML, JS, CSS y las imágenes. El funcionamiento de la caché web se determina por la solicitudes del navegador y respuestas del servidor y por medio de la información sobre el recurso en caché. En líneas generales el funcionamiento es el siguiente:
- El servidor puede indicar al navegador que no guardé en caché el recurso, enviándole una cabecera
Cache-Control: no-cache. En ese caso el navegador debe siempre requerir el recurso original del servidor. - Si el servidor no envía una cabecera de validación como
Last-ModifiedoE-Tag, el navegador no podrá controlar la caducidad del recurso y por tanto no lo cacheará. - Si es una página segura (protocolo https) el navegador no cacheará los recursos.
- Los recursos en la caché del navegador disponen de una fecha de caducidad obtenida de una cabecera
Cache-Control: max-ageoExpiresque en un tiempo anterior le había enviado el servidor. Cuando un usuario requiere una página el navegador comprueba si la tiene en caché y luego comprueba si está actualizada (o no caducada), lo que conlleva que la fecha actual sea inferior a la fecha de caducidad. En ese caso le sirve el recurso desde la caché sin necesidad de realizar niguna conexión con el servidor. - La cabecera validadora
Last-Modified(o alternativamenteE-Tag) informa al navegador de la fecha cuando fue modificado el archivo por última vez. Si un recurso ha caducado el navegador enviará una consulta con una cabeceraIf-Modified-Since(oIf-None-MatchparaE-Tag) y la fecha de última modificaciónLast-Modified(o elE-Tagen su caso) que tenga almacenada. El servidor comprueba si el recurso ha sido modificado. En caso negativo le responde con un código de estado HTTP 304Not Modified. El navegador entonces procede a recuperar la copia desde su caché pues no ha sido modificada. Esto conlleva una conexión con el servidor pero sólo se reciben las cabeceras HTTP. En otro caso si el servidor comprueba que el recurso fue modificado le enviará un código200y el contenido del nuevo recurso. El navegador actualizará entonces la información en la caché. - Puede suceder que un navegador o proxy sirva un contenido caducado de la caché si tras hacer una consulta
If-Modified-Sinceno pudo conectar con el servidor por alguna razón o este le devolvió un código de estado 5xx por ejemplo. Si no queremos que el usuario vea un documento caducado bajo ninguna circunstancia envíaremos desde el servidor una cabeceraCache-control: must-revalidate. Esto es usual hacerlo en páginas con sesiones y cookies y/o que recogan datos de formularios.
La fecha de caducidad puede ser comunicada por el servidor de dos formas. Una es con un cabecera como Expires: Sun, 15 May 2014 21:15:42 GMT. Mientras no se sobrepase esa fecha el navegador tirará de la caché. Esta cabecera pertenece al protocolo HTTP 1.0 y es ampliamente soportada. El servidor Apache dispone del módulo mod_expires con el que podemos configurar la caché. En el archivo de configuración httpd.conf o en un .htaccess pondríamos algo como ExpiresByType text/html "access plus 1 day" para los documentos HTML. Con eso el servidor calculará la fecha de caducidad sumando 1 día a la fecha en la que se envía el recurso al navegador, agregando además una cabecera Expires a la respuesta.
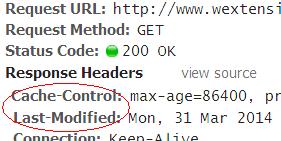
Otra cabecera alternativa de HTTP 1.1. es Cache-Control que puede llevar una lista de directivas separadas por comas (ver lista de directivas de Cache-Control). Por ejemplo Cache-Control:max-age=86400 que establece un período de 86400 segundos de caducidad para el recurso (1 día). El navegador procede a cachear un recurso por primera vez guardando la fecha de ese momento. En otro posterior cuando consulte ese recurso cacheado sólo tiene que sumarle los 86400 segundos a esa fecha y así obtener la fecha de caducidad. Vea que la diferencia con el anterior es que ahora es el navegador el que calcula la fecha de caducidad.
Apache dispone de la directiva Header para gestionar cabeceras HTTP. Podemos agregar, reemplazar, fusionar o eliminar cabeceras. Con algo como Header set Cache-Control "max-age=86400" en el httpd.conf o en htaccess configuramos una duración de vida de 86400 segundos (1 día) para un recurso. Podemos filtrar por tipo de recurso con la directiva FilesMatch.
Realmente HTTP 1.1 expone que para saber si un recurso en caché está o no caducado se compara la edad del recurso cacheado con su duración de vida, pero en definitiva es el mismo concepto:
- Tenemos la fecha A cuando se cacheó el recurso.
- Tenemos la fecha actual B en la que se realiza la consulta en la caché.
- El recurso en caché tiene una edad de e = B - A segundos.
- Por otro lado podemos tener:
- Una cabecera
Expiresdel recurso cacheado con la fecha F cuando caduca el recurso. Su duración de vida es de d = F - A segundos. - Una cabecera
Cache-Control: "max-age = d". En este caso ese dato d segundos es la duración de vida. - Si ambas cabeceras están presentes prevalece la segunda.
- Una cabecera
- El recurso no ha caducado si d > e, es decir, si la duración de vida supera la edad. Veáse que con
Expiresesto equivale a F-A > B-A lo que finalmente se reduce a F > B, en definitiva que la fecha de caducidad es mayor que la fecha actual. En el caso deCache-controlvemos que equivale a d > B-A, que es igual que A+d > B. La parte izquierda es la fecha en la que se recuperó el recurso más la duración, lo que viene a ser la fecha de caducidad, llegando finalmente a lo mismo F > B.
Configurar caché web según tipo de recursos
Esta parte es la más díficil de llevar a cabo porque no hay reglas absolutas dado que dependerá de cada sitio web. Se trata de establecer la duración de vida de los recursos. Los sitios que mencioné más arriba Web Caching, Google Developers y Yahoo Developers exponen una serie de consejos de uso general que conviene leer. En todo caso cada uno tendrá que adaptarlo a las características de su sitio web. Debo decir también que la implementación de la caché web en este sitio es fruto de una corta experiencia y posiblemente será objeto de modificaciones. Como todo lo nuevo que se emprende hay que arriesgarse a cometer errores y aprender de ello.
Empezaremos con los recursos HTML, a los que podríamos darle una duración de vida de un mes o más, pero a veces actualizo páginas mejorándolas o corrigendo cosas. Si mi ritmo de publicación nunca será inferior a una vez por semana, puedo usar ese período semanal para la duración de vida de estos recursos. Generalmente no modifico la mayor parte de las páginas. Pero si lo hago y un usuario la ha cacheado inmediatamente antes de la modificación, como mucho tendrá la actualización a la semana siguiente. Esto se podría evitar no cacheando los documentos HTML, pero no aprovecharíamos completamente la caché que tiene su óptimo cuando el navegador no tiene que hacer ninguna conexión con el servidor.
Algunos HTML como el de entrada al sitio y otros que recopilan índices podrían tener una duración de vida menor, por ejemplo de un día. Esto me permitirá hacer modificaciones diarias en esos índices y, especialmente, en la página de entrada al sitio. Otros recursos no cambian, como las imágenes. Podemos darle una duración de vida larga, como mínimo de un mes. Si en un caso concreto modificamos una imagen, es preferible cambiarle el nombre al archivo y luego modificar el HTML desde donde se vincula, pues los HTML tendrán una duración de vida menor.
Los JS y CSS supuestamente no cambian a menudo. Pero no en mi sitio que está dedicado al desarrollo web. Constantemente estoy actualizando esos recursos por lo que debería darle una semana o menos de duración de vida. Yahoo y Google Developers hablan de cachear estos recursos con una larga vida de duración. Luego si tenemos que modificarlos agregaremos una marca de tiempo (fingerprinting) o cualquier otra cosa que modifique el nombre. Por ejemplo, Yahoo dice que un JS como yahoo.js lo renombría como yahoo_2.0.6.js, donde agrega unos números de versión del componente.
Esa misma idea expone Google Developers diciendo que si conoces cuando un recurso puede ser modificado se pueden usar cortas duraciones de vida. Pero si sabes que podría cambiar pronto pero no exactamente cuando, deberías usar entonces una larga duración de vida junto a marcas de tiempo (fingerprinting)
. Esto esta bien para archivos JS que se vinculen desde pocas páginas que a su vez tengan una corta duración de vida pues se modifican por ejemplo a diario. Pero si yo tengo archivos JS que se vinculan en muchas páginas que cambian poco frecuentemente, esta solución me obligará a modificar todos los vínculos a ese JS en todas las páginas.
En el caso de modificación de un sprite CSS ya estaba usando este concepto para forzar al navegador a que solicitase de nuevo el recurso cuando el nombre fuese modificado. En la siguiente imagen se observa que tiene una duración de vida de un mes (2592000 segundos) como todas las imágenes del sitio, pero al cambiar el nombre del archivo el navegador lo solicitará de nuevo.
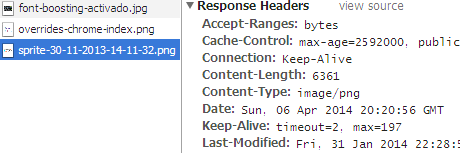
En este caso es fácil realizarlo así puesto que esa URL está vinculada en un único archivo CSS que contiene una única línea con el estilo background: url('/res/img/sprite-30-11-2013-14-11-32.png').
Otro caso que a veces interesa es evitar el cacheado de un archivo JS por ejemplo. El archivo links.js contiene una lista de enlaces que se abren con el botón Accesos de la barra superior. Se solicita al servidor con AJAX (XHR)XHR es el acrónimo de XMLHttpRequest, una interfaz para comunicarse con el protocolo HTTP. En cambio AJAX (Asynchronous JavaScript And XML), que se basa en JavaScript y XHR, es una técnica que permite ejecutar tareas asíncronas no interfiriendo con el comportamiento de la página.. Es una lista que se modifica cada vez que publico un nuevo tema, por lo que el usuario deberá tener siempre esa lista actualizada. Hay que forzar al navegador para que la recupere siempre del servidor:
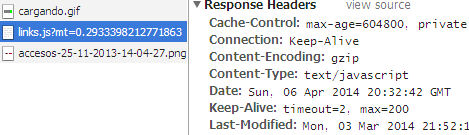
Cada vez que se solicita con XHR la lista agregamos con JavaScript un parámetro GET con un número aleatorio obtenido con Math.random(). En el servidor no se utiliza ese parámetro para ningún cometido, pero esto fuerza al navegador a recuperar siempre el archivo desde el servidor, aunque la caché está configurada con una duración de una semana (604800 segundos) como todos los archivos JS del sitio.
Las URL con consultas GET pueden ser cacheadas con la cadena de parámetros. Pero la documentación de Google habla de algunos problemas relacionados con Firefox dado que parece que usa los ocho primeros caracteres del nombre del archivo para indexarlos en su caché. También algunos proxies no cachean estas URL con GET. Por lo tanto es recomendable poner esa marca con más de 8 caracteres al principio del nombre. Pero esto no siempre será posible, especialmente cuando el nombre de ese archivo se vincula o aparece referenciado en otros múltiples documentos.
Las páginas que funcionan con sesiones PHP, como puede ser el formulario de contacto o el buscador en este sitio, no se cachean. Ambos usan POST para enviar datos de un formulario al servidor. Las peticiones con POST no son cacheadas por el navegador. De todas formas al trabajar con sesiones, PHP usa la opción de configuración del archivo php.ini denominada session.cache_limiter con un valor por defecto nocache. Así que envía estas cabeceras relacionadas con el cacheado:
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires:Thu, 19 Nov 1981 08:52:00 GMT Pragma:no-cache
El valor no-store le dice al navegador que, aparte de no cachear tal como obliga con no-cache, no debe almacenar el contenido ni ninguna parte del mismo en memoria no volátil. Y eliminarla de la memoria volátil tan pronto como sea posible. El valor must-revalidate ya lo explicamos más arriba. Al igual que la cabecera Pragma y Expires que tiene una fecha del pasado, en el fondo están de más en tanto que pasamos el valor no-cache. La cabecera Pragma no es parte de HTTP 1.1, pero PHP y los navegadores a veces la incluyen por si hay sistemas que sólo soportan esa cabecera.
Caché web pública y privada
HTTP 1.1 introduce Cache-control que permite configurar la duración de vida y también otros aspectos. El servidor puede especificar si el recurso puede guardarse en una caché pública (valor public) como la de los servidores proxy, en una caché privada (valor private) que son la de los dispositivos de usuario y, finalmente, que no se guarde en caché en ningún caso (no-cache).
Los servidores proxy actuan como intermediarios cercanos al usuario. Así cuando hacemos una petición al servidor de origen, el proxy realiza la validación de su caché y si el recurso no ha caducado se lo envía al usuario. La ventaja es que el recurso guardado por el primer usuario que acceda a una página puede ser ampliamente compartido por el resto de usuarios que accedan posteriomente. Pero hay mucho sobre proxies que me hace dudar. Especialmente cuando leo lo que expone el documento de Google Developers que señalé mas arriba.
Por un lado dice ese documento que cachear públicamente un recurso también significa que se comparte públicamente las posibles cookies. Y éstas pueden contener datos que afectan a la privacidad de los usuarios. Por esta razón hay muchos proxies que no cachean recursos con cookies. En este sitio uso cookies en las páginas con sesiones PHP, que vienen a ser las del buscador y la de contacto. Ya de por sí no se cachean, por lo que en principio el problema anterior parece no afectarme tanto.
Por otro lado también dice el documento de Google Developers que algunos proxies públicos tienen problemas con la compresión gzip pues no detectan la cabecera Content-Encoding. Y todos mis HTML, JS y CSS se envian comprimidos. En definitiva, antes estas dudas y mientras tanto usaré la caché privada para los HTML, JS y CSS, pero si cachearé públicamente las imágenes.
Implementando caché web en Apache
La caché web para este sitio cuyas duraciones de vida expuse en el apartado anterior se puede implementar en el servidor Apache de esta forma:
Header unset ETag FileETag None <FilesMatch "\.(ico|jpg|png|gif|txt)$"> #1 mes = 60x60x24x30 = 2592000 segundos Header set Cache-Control "max-age=2592000, public" </FilesMatch> <FilesMatch "\.(html|css|js)$"> #1 semana = 60x60x24x7 = 604800 segundos Header set Cache-Control "max-age=604800, private" </FilesMatch> <LocationMatch "^(/|/articulos/|/como-se-hace/|/herramientas/|/temas/)index\.html$"> #1 día = 60x60x24 = 86400 segundos Header set Cache-Control "max-age=86400, private" </LocationMatch>
Prefiero usar Cache-Control en lugar de Expires porque es una cabecera más actualizada y permite un mayor control. Pero no hay que olvidar que hay que usar siempre Cache-Control (con max-age) o alternativamente Expires. Y al mismo tiempo Last-Modified o alternativamente ETag, pues sin esto el navegador no podrá validar la caché. El ETag es un identificador único que genera el servidor y que se modifica cuando lo hace el archivo. Exactamente igual que la fecha-hora del Last-Modified, que también es único y que cambia cuando lo hace el archivo. Éste tiene la ventaja de que lo podemos leer y entender, mientras que el otro es una cadena de dígitos y letras que no nos dice nada. Y otra razón es que podemos inyectar con PHP una fecha-hora como cabecera Last-Modified más fácilmente que si fuera un E-Tag, como veremos en el siguiente tema. De todas formas el servidor podría enviar ambas y el navegador tomará la que necesite sin mayor problema, pero eliminando una aligeramos el tamaño de las cabeceras.
El problema que hay con el htaccess anterior es que la directiva FilesMatch puede ser utilizada en un htaccess, pero no así LocationMatch que debe incluirse en el archivo de configuración del servidor httpd.conf. FilesMatch sólo nos permite filtar por el nombre del archivo con su extensión, aplicando expresiones regulares. Mientras que la segunda nos permite hacer un filtrado de la ruta, que es lo que necesitamos en ese ejemplo para los index.html de ciertas carpetas que contienen páginas con índices de temas.
Por ahora este sitio está en un alojamiento compartido y por tanto no tengo acceso al archivo de configuración del servidor. Sólo puedo hacer uso de los htaccess. Además por otro lado también envío los recursos comprimidos usando PHP, de tal forma que todos los recursos HTML, JS y CSS se manejan con PHP para aplicarles compresión. Así que en el htaccess sólo me limitaré a configurar la caché para imágenes y otros archivos como los txt y será en PHP donde aplicaré las cabeceras de cacheado para los HTML, JS y CSS. Esto lo veremos en el siguiente apartado.
Implementando caché web con PHP
Implementar una caché web en el servidor Apache no es díficil, tal como vimos antes. Pero si los recursos HTML, JS y CSS son manejados por PHP antes de ser servidos es necesario configurar la caché con PHP. En el tema sobre comprimir web comenté sobre los scripts de pre-ejecución de PHP. Se trataba de sacar como PHP los recursos HTML, JS y CSS como si fueran documentos PHP y así poder comprimirlos con PHP. Pero necesitábamos pre-ejecutar un script para agregarles una cabecera Content-Type a los recursos JS y CSS. Ese mismo script también lo utilicé para inyectar CSS en una técnica que denominé CSS FOLD. En cualquier caso si sus HTML, JS, CSS o cualquier recurso sale a través de PHP necesitará enviar las cabeceras HTTP requeridas para implementar una correcta caché web.
A continuación expondré el código del script de pre-ejecución e iré comentando los detalles, pero tenga en cuenta que este código puede sufrir modificaciones. El código actualizado lo puede ver en prehjc.php.
A partir de la URL del recurso que se está pre-procesando obtenida con $_SERVER["PHP_SELF"] recuperamos un array con la información del archivo usando pathinfo(), que contiene entre otras cosas la extensión. Por ésta filtraremos para adjudicarle un tiempo de duración de vida de la caché tal como vimos más arriba. Agregamos una cabecera Content-Type a los JS y CSS pues por defecto el archivo de configuración php.ini pone tipo text/html a toda salida de PHP. De esta forma los HTML no necesitarían esta cabecera, pero se la agregamos para mayor seguridad y al mismo tiempo parar incorporar la codificación de caracteres con charset=utf-8.
Vea que sólo se aplica a extensiones html, js y css. Pues los documentos que salen con extensión php no los pongo generalmente en caché pues portan sesiones PHP. Pero esto lo puede modificar y elegir sólo las extensiones a los que le vaya a aplicar caché. En el caso de los HTML hago un borrado de cookies que se generan en las páginas buscador y contacto (las cookies tienen el mismo nombre). Sucede que cuando salimos de esas páginas y vamos a otras, las cookies generadas en esas páginas puede que no se borren. En ese caso estaremos enviando desde el navegador información innecesaria en las cabeceras. Así si navegamos a cualquier HTML envíamos una cookie de borrado en el caso de que aquellas existan. Esto tampoco tiene que ver con el cacheado y puede obviarlo.
La variable $time tendrá los valores de una semana (604800 segundos) para los HTML y JS tal como vimos en un apartado anterior. Pero también aplicaba la misma duración para los CSS y sin embargo en este script aparece un mes. Esto es porque los archivos CSS que no forman parte de CSS FOLD son muy pocos y no van a cambiar con frecuencia. Pues CSS FOLD nos permite inyectar prácticamente todo el CSS del sitio, pero sólo el que cada página necesite. En cualquier caso tenemos un filtro por extensiones HTML, JS y CSS y una duración de vida de caché para cada extensión.
El siguiente paso es modificar algunas duraciones de vida específicas (en días). A todos los HTML les habíamos puesto una semana, pero a algunos los rebajamos hasta un día. Son páginas con índices incluso la página principal que puede modificarse con mayor frecuencia. Si la URL que estamos procesando está en ese array entonces convertimos esos días en segundos.
A continuación formamos la ruta física de la URL que estamos procesando. Mediante la función filemtime() extraemos la fecha de la última modificación del archivo, dándole el formato requerido por HTTP con la función gmdate(). Esta fecha irá en la cabecera Last-Modified.
Pero antes tenemos que mirar si el navegador nos envió una cabecera If-Modified-Since. En este caso el navegador tiene ese recurso en su caché y le está enviando la última fecha de modificación almacenada para comprobar si el recurso en el servidor tiene una fecha posterior, es decir, si ha sido modificado.
Previo a comprobar ese extremo tenemos que enviar en todo caso las cabeceras Cache-Control y Last-Modified. Tras esto hacemos la comprobación y si no hubo modificaciones enviamos un estado 304 Not Modified. Aunque el protocolo también exige enviar una Vary: Accept-Encoding si el recurso va a salir comprimido. En este punto salimos inmediatamente del script puesto que no se enviará más contenido y el navegador al recibir un estado 304 usará la versión de su caché.
Si el recurso fue modificado o bien no hay petición del navegador para hacer esta comprobación, el script sigue su curso y PHP se encarga de enviar un estado 200, remitiendo el contenido del recurso a continuación.