Buscador PHP con índice de palabras
Estructura del índice en buscadores que procesan en el servidor
Trata este tema de las bases para el diseño de un buscador interno apoyado en un índice de palabras clave, ejecutando el proceso de búsqueda con PHP en el servidor y enviando al cliente los resultados. Lo primero que hemos de hacer es plantear la estructura de ese índice. Por un lado tenemos el índice de claves (declarado como $indice_claves en el código) que viene a ser un array donde usamos los términos de búsqueda como clave del array y cada entrada es a su vez un array de números enteros. Por ejemplo, en ese array están las palabras "algoritmos", "articulos" (sin tilde) o "utf8":
... [algoritmos] => Array(0,44) ... [articulos] => Array(0,1,2,3,4,5,6,7,42) ... [utf8] => Array(0) ...
Las palabras clave aparecen siempre en minúsculas usando exclusivamente el juego de caracteres ASCII, es decir las letras [a-z] y los dígitos [0-9]. Aunque el array permite claves con cualquier juego de caracteres, sin embargo hay ciertas consideraciones acerca de los caracteres que no pertenezcan a ese grupo, detalle que explicaré más adelante. Aún así es posible encontrar la palabra "artículos" usando la clave "articulos" sin tilde.
Este índice de claves contiene unos números enteros que referencian una entrada de documento en otro array que denomino índice web (declarado como $indice_web en el código). Así los términos "algoritmos", "articulos" o "utf8" aparecen en el documento número 0. Este es el primero del array y corresponde a la página con URL /articulos/algoritmos_utf8/:
[0] => Array(
[u] => "/articulos/algoritmos_utf8/"
[t] => "Algoritmos de transformación UTF-8"
[d] => "Saber como funciona la codificación UNICODE..."
[k] => "unicode, utf-8, utf8, utf 8, utf-16, ..."
[i] => Array(
[0] => Array( [0] => "ap0" [1] => "Buscando...")
[1] => Array( [0] => "ap1" [1] => "Comprobación...")
[2] => Array( [0] => "seguridad" [1] => "Seguridad...")
[3] => Array( [0] => "leer-bytes" [1] => "Leer...")
[4] => Array( [0] => "ap2" [1] => "De UTF-8...")
[5] => Array( [0] => "ap3" [1] => "De Unicode...")
)
)
...Cada entrada de documento es un array separado por las claves:
[u]para la URL[t]para el título, que se extrae del elemento<meta name="title">[d]para la descripción, que se extrae del elemento<meta name="description">[k]para los keywords, que se extrae del elemento<meta name="keywords">[i]para los encabezados identificados, que se extrae de los elementos<h1 id="...">,<h2 id="...">, etc.
La entrada [i] se descompone a su vez en otro array con una entrada para cada uno de los encabezados. Cada una de esas entradas almacena otro array con el identificador (id) en la primera posición y el texto interior del encabezado en la segunda posición. Note que en este array índice web de documentos se han escapado todos los caracteres Unicode: en lugar de "transformación" aparece "transformación", lo que se hace en el momento de construir el índice usando la función htmlentities(). Esto y no usar caracteres no ASCII en el índice de claves mejora la búsqueda con palabras con acentos como ya veremos.
Esta estructura del índice de documentos web permite una entrada por documento con al menos la clave [u], pues el resto son opcionales. Estos índices se construyen previamente usando la herramienta construir índices de buscadores internos. Esta utilidad crea esos arrays y los serializa para almacenarlos como archivos de texto. Se usa la función de PHP serialize() que transforma el array en un texto para luego poder ser recuperado usando unserialize().
Estructura de los arrays de resultados
El proceso de búsqueda, mediante la función buscar_docs(), genera un array de documentos del resultado de la búsqueda (denominado $array_docs en el código) que tiene esta estructura de ejemplo:
[0] => 7 [1] => 23 [2] => 51
Se trata de un array de una sóla dimensión, donde se incluyen los números de documentos en la posición del array índice web, en los cuáles se encontraron coincidencias de búsqueda al analizar los términos claves del array índice de claves. Así esta hipotética búsqueda encontró coincidencia en los documentos números 7, 23 y 51.
Este array de documentos del resultado contiene sólo números, pero es la pieza básica para gestionar el buscador. Uno de los mayores problemas es el relacionado con el paginado de resultados. Partimos de que un resultado es una concidencia encontrada en un documento. Así es usual ofrecer un conjunto de resultados limitado por ejemplo de 10 coincidencias. Pero el proceso de búsqueda pudo haber generado más resultados y es necesario almacernarlos de alguna forma para cuando el usuario pida la página siguiente de resultados de esa misma búsqueda no tener que repetir el proceso.
Este array se almacena en una variable de sesión, pues es la mejor manera de gestionar las búsquedas por usuario. En la siguiente petición de paginado se observará si hay una variable de sesión almacenada y si es así se ofrece esa página de resultados. En cambio si el usuario modifica la cadena o las opciones de búsqueda, es que se trata de una nueva búsqueda y esa variable de sesión se sobreescribe con el nuevo array de documentos.
Como el array de documentos es de una sóla dimensión y únicamente contiene números, en lugar de serializarlos los guardamos haciendo un $_SESSION["arr-docs"] = implode(",", $arr_docs), pues luego los podemos extraer con $arr_docs = explode(",", $_SESSION["arr-docs"]) sin mayor problema.
Pero este array de documentos no nos dice en que encabezado del documento del índice web se encuentra la coincidencia, si es que hay alguna. Así que con la composición de cada página de resultados hemos de generar otro array de resultados (denominado $arr_res en el código). La función que se encarga de extraer una página de resultados es extraer_pagina() generándonos el array de resultados que tiene esta estructura de ejemplo:
[0] => Array ( [0] => 7 [1] => Array ( [0] => 4 [1] => 5 ) ) [1] => Array ( [0] => 23 ) [2] => Array ( [0] => 51 )
Este ejemplo es un array que devuelve 3 documentos coincidentes con una búsqueda hipotética. Cada entrada dispone de un array con un primer elemento que contiene el número de documento en el índice web (en amarillo). La segunda entrada es opcional y es a su vez otro array con las coincidencias con los encabezados identificados (en verde). Por ejemplo, en resalte amarillo se encuentran los números de documento del índice web. Así esta búsqueda coincidió con los documentos números 7, 23 y 51. En resalte verde vemos las coincidencias encontradas con los números de posición en el array del índice web con clave [i]. Por lo tanto esta búsqueda encontró coincidencia en los encabezados 4 y 5 (numerados siempre desde cero) del documento número 7. Este array es temporal, pues sólo servirá para enviarlo a otra función componer_pagina() que nos compone el literal HTML de esos resultados paginados que se enviará al cliente.
El proceso de búsqueda
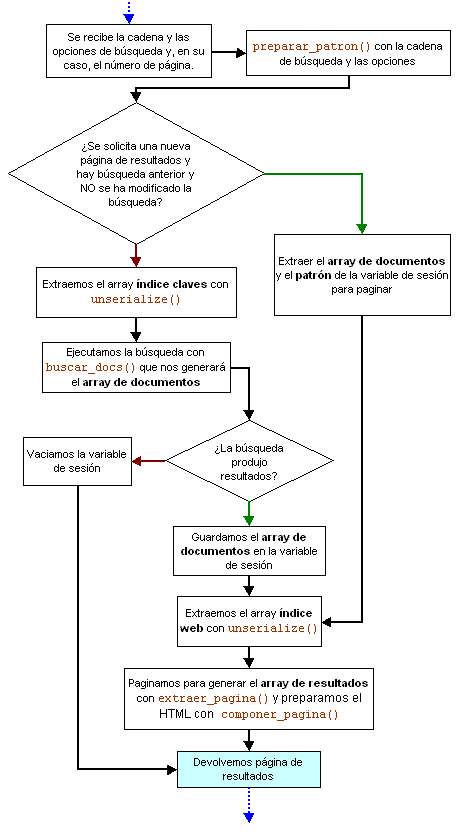
La función buscar() se encarga de realizar el proceso de búsqueda. El diagrama de flujo es el siguiente (el color verde representa salidas afirmativas y el marrón negativas de las bifurcaciones):
Esa función que realiza este proceso tiene esta declaración:
function buscar($cadena_busqueda, $pagina=-1, $seleccion="documento", $tipo_busqueda="alguna", $palabras_completas=false, $sensible_mayusculas=false)
La entrada de datos que nos envía el usuario se compone de la cadena de búsqueda y de las opciones de búsqueda. Se escapan todos los caracteres Unicode de la cadena de búsqueda (que vienen en UTF-8) usando la función htmlentities() (más abajo veremos la razón de esto). También se recibe el número de página. Si no hay resultados anteriores almacenados en la variable de sesión entonces este número es -1. En todos los casos se prepara un patrón de expresión regular con la cadena y las opciones de búsqueda. Pues para determinar si hemos de paginar un conjunto de resultados o se trata de una nueva búsqueda hemos de saber si el usuario ha modificado la cadena o las opciones de búsqueda (lo que modificará el patrón) y, por otro lado, si está solicitando una determinada página, hemos de comprobar si hay almacenados resultados anteriores en la variable de sesión.
Si es una nueva búsqueda entonces extraemos el índice de claves y ejecutamos buscar_docs() que nos devolverá la lista de números de documentos donde hay coincidencia. Guardamos esos resultados en la variable de sesión y, tras extraer el índice web, procedemos a extraer la primera página, componiendo finalmente el HTML de esos resultados para devolvérselos al cliente. Si estamos paginando, es decir, si no se trata de una nueva búsqueda, saltamos directamente a extracción y composición de página.
La selección puede ser por documento o por apartados. Con la primera podemos tener las opciones para tipo de búsqueda con los valores alguna palabra o todas las palabras. Con la selección por apartados estos valores son alguna, todas en ese orden, todas en cualquier orden y cadena completa. La opción de palabras completas está disponible en ambos casos, pero no así sensible mayúsculas que sólo está disponible para la selección por apartados. Esta configuración de opciones se debe a aplicar los siguientes criterios generales del proceso de búsqueda:
- Función
preparar_patron()La cadena de búsqueda se divide en palabras eliminando términos de uso frecuente como preposiciones, adverbios, artículos, etc. También se omiten los signos ortográficos. Esto se hace en el momento en que se construye también el patrón para usar con expresiones regulares.
- Función
buscar_docs()Se busca iterando por las claves del array de índice de claves los números de documentos donde aparecen esas palabras. Estos números se guardan en el array de documentos. Aquí no se usan expresiones regulares con el patrón que hemos construido, sino una simple comparación de la palabra con la clave del array índice de claves, lo que reduce los tiempos de proceso. Si la lista de palabras contiene dos o más y la opción es buscar todas las palabras, se dejan sólo en el array de documentos aquellos que figuren al mismo tiempo en todas las entradas coincidentes del índice de claves. El array de documentos y el patrón se almacenan en las variables de sesión para posteriores paginados solicitados por el usuario.
- Función
extraer_pagina()Para preparar y enviar al usuario una página de resultados usamos el array de documentos y el patrón construido, buscando coincidencias en los encabezados identificados del array índice web (clave
[i]de ese array). Pues sabemos en que documentos se encuentran las coincidencias, pero aún no sabemos en que encabezados se da esa coincidencia y esto hay que hacerlo para todos los tipos de búsqueda, tanto por documentos como por apartados. Pero si el tipo de búsqueda es por apartados, se aplica también el patrón a cada uno de los apartados del documento, es decir, a la URL (clave[u]), al título ([t]), a la descripción ([d]) y a los keywords ([k]).Cuando se busca más de una palabra en un documento incluido en el array de documentos puede que no se produzca coincidencia en este paso y ese documento tenga que ser descartado e incluso eliminado del array de documentos, que se vuelve a sobreescribir en la variable de sesión. Por ejemplo, las palabras "abc" y "def" podrían estar en el documento número 77, pero en diferentes apartados, una en el título y otra en la descripción. Si la opción es búsqueda por apartados de todas las palabras, este documento 77 sería descartado del array de documentos en este paso.
Esto, que solo se ejecuta con la opción por apartados, sería una operación de filtrado a posteriori del array de documentos y se va ejecutando a medida que el usuario va solicitando nuevas páginas de una misma búsqueda. Es obvio que consume más recursos al usar expresiones regulares, pero sólo lo estamos ejecutando para UNA página de resultados que contiene sólo 10 documentos, por lo que controlamos y limitamos los tiempos de proceso al ejecutar un filtrado por página solicitada y no sobre el total de documentos coincidentes. Al final de esta fase obtenemos un array de resultados con 10 o menos documentos que tiene un caracter temporal y nos servirá para componer la página.
- Función
componer_pagina()Esta función es una continuación de la anterior, pero la hemos separado para clarificar el código. Se trata de realizar una composición HTML de los resultados encontrados en el paso anterior. Se resaltan en letra negrita las coincidencias encontradas y se devuelve este literal HTML al usuario.
En este tema se ha expuesto una visión global del buscador interno con PHP. En el siguiente tema se expone como construir los índices y como implementar el buscador incluyendo una página de ejemplo con el fomulario. Aunque con esos dos temas será suficiente para implementarlo, en los últimos se entra en el detalle de cada una de las funciones importantes del diagrama de flujo anterior, por si desea conocer más sobre el funcionamiento de este buscador.