HTML5 Semántico
Los elementos semánticos de HTML
El objetivo de los elementos semánticos de HTML es estructurar la página en base al contenido y no a su apariencia visual. El uso principal de la semántica en un documento HTML es que otras aplicaciones puedan distinguir los contenidos. Los elementos de HTML fueron inicialmente concebidos con un caracter semántico. Por ejemplo, un <p> contiene un párrafo de texto, un <a> contiene un vínculo a otro documento y un <h2> contiene un título de segundo nivel. Y esto de forma independiente de como se presenten visualmente esos elementos.
La idea era separar contenido de estilo, siendo HTML quien portara el contenido y CSS el estilo. Pero ese objetivo no siempre se ha cumplido y hay que hablar de excepciones como <div> y <span> que son elementos semánticamente neutros. Estos son los que debemos usar para dar estilo de presentación con CSS a partes de contenidos que no tienen caracter semántico.
Y otras excepciones más graves como <b>, <i> o <font> que eran elementos puramente presentacionales. Daban estilo negrita, itálica o fuente de texto. Los dos primeros siguen soportándose en HTML5 con un nuevo caracter semántico, pero debemos considerar el uso de elementos <b> e <i>. Si queremos resaltar semánticamente un trozo de texto hemos de usar <strong> o dar enfásis con <em>. En cuanto a <font> ya fue declarado obsoleto en HTML4 y no está en HTML5 y, aunque los navegadores siguen soportándolo, debemos usar la propiedad font de CSS.
HTML-4.1 contiene muchos elementos que sólo sirven para dotar de estilo. Aparte de los citados antes existen otros como <big> para agrandar el tamaño de la fuente o <center> para centrar texto. De hecho hice un Glosario de XHTML-1.0 que estaba basado en HTML-4.1, donde hay una página titulada XHTML-1.0: Formatos. Obviamente el nombre no es del todo correcto puesto que HTML no debería contener elementos cuya única finalidad sea dar formato visual al contenido que porten. En esa página se describe un elemento sólo de formato como <center> junto otro propiamente semántico como <cite>.
Los elementos de formato visual de HTML-4.1 son de versiones anteriores. HTML-4.1 advertía, por ejemplo, que los elementos de estilo de fuentes como I, B, BIG y SMALL no se les consideraba obsoletos pero se animaba a usar CSS en su lugar. Incluir elementos puramente de estilo en HTML hizo mucho daño porque una vez que entraron en uso ha sido y sigue siendo muy díficil sacarlos de la especificación. HTML5 no declara obsoletos muchos elementos presentacionales que son muy usados a base de darles un nuevo significado semántico. Por ejemplo, <i> se usará para designaciones taxonómicas, términos técnicos, frases de otro lenguaje, nombres de barcos y contenidos similares donde se precise una texto en itálica que lo diferencie del resto del texto.
Hay otros elementos como <br> y <hr> que son puramente presentacionales puesto que no tienen contenido. Pero que seguirán en HTML5 con un nuevo significado semántico, quizás un poco forzado en mi opinión. Por un lado <br> separará líneas de texto en contenidos que lo precisen como poemas o direcciones. Y <hr> representa una ruptura temática a nivel de párrafo. Puede ver un poco de historia acerca de los elementos vacíos en SGML, XHTML y HTML.
Los elementos semánticos tienen un estilo CSS visual inicial por defecto, como vemos en este CSS inicial para HTML4. Usar elementos de HTML simplemente por su estilo inicial de presentación es un error que no debemos permitirnos (empezando por mí, porque también hacía mal uso de ellos).
HTML5 incorpora nuevos elementos para ampliar la capacidad semántica de un documento, con elementos como <header> o <footer> que servirán para definir la cabecera y pie de un documento. Se declaran las secciones de un documento con elementos como <section>, <article>, <aside> o <nav>. Se establece que la sección predeterminada que agrupa a todas las demás es <body>. Aquí no voy a entrar en detalle de todos esos nuevos elementos y cómo se utilizan, porque principalmente aún tengo muchas dudas sobre su uso. Hay mucha documentación que se puede consultar, como el sitio Html5 Doctor, que nos ayudará a usar HTML5 tal como dice en el lema del sitio, pudiendo empezar con este artículo introductorio Let’s Talk about Semantics. Un diagrama de flujo (PDF) de ese sitio nos ayudará a decidir que elemento usar en función del contenido.
Con las últimas actualizaciones de este sitio he incorporado esos nuevos elementos de HTML5. Pero, como dije antes, tengo y hay muchas dudas sobre esto. En el siguiente apartado intentaré reflejar la situación y en otro apartado explicaré que es lo que he implementado en este sitio.
El Outline y el seccionado semántico de un documento
El outline de un documento es un resumen de contenidos obtenido a partir de las secciones y encabezados. La especificación de HTML5 detalla un algoritmo para obtener ese outline, resumen que podría servir a otras tecnologías para encontrar contenidos en un documento. Y ese resumen que se obtiene depende de como se usen las secciones en combinación con los elementos de encabezado que se utilicen. Podemos encontrar más información en una página de Developer Mozilla titulada Sections and Outlines of an HTML5 Document. También un artículo de HTML5 Doctor titulado Document Outlines, actualizado en enero 2014.
El W3C expone como crear un outline en la especificación de HTML5 en fase de borrador (del 23 de abril de 2014), en el apartado Creating an outline, pero empieza con una advertencia:
¡Aviso! No hay implementaciones conocidas del algoritmo para montar el outline en navegadores visuales o de tecnología asistida, aunque está implementado en otros tipos de software como validadores. Así que el algoritmo outline no puede ser usado para presentar el resumen de contenidos a los usuarios. Se aconseja usar los niveles de encabezados (h1-h6) para presentar ese resumen de contenidos.
(Warning! There are currently no known implementations of the outline algorithm in graphical browsers or assistive technology user agents, although the algorithm is implemented in other software such as conformance checkers. Therefore the outline algorithm cannot be relied upon to convey document structure to users. Authors are advised to use heading rank (h1-h6) to convey document structure.)
Después de leer algo sobre esto uno llega a la conclusión de que hay muchas lagunas. Especialmente preocupante es que los navegadores y los sitios de búsqueda como Google ignoran el seccionado HTML5 y se siguen basando sólo en los encabezados h1-h6 (ver HTML5 and SEO).

Obtener un Outline o resumen de encabezados h1-h6 de HTML4 es relativamente sencillo. En enero 2011 publiqué un tema sobre la Tabla de contenidos (TOC: Table Of Contents) de un documento. Es un componente que se basa en JavaScript para recuperar una lista de encabezados h1-h6, aunque nunca llegue a usarlo en la estructura de este sitio. Lo he implementado en esta página mostrándose con el siguiente botón:
Mostrará una lista de encabezados como la imagen adjunta, cuyos niveles se diferencian por el sangrado de cada línea. Cada entrada de la lista es un vínculo que nos llevará a ese encabezado. Se observa que hay dos entradas de primer nivel, es decir, hay dos elementos <h1> en las páginas de este sitio. El primero define el título Wextensible del sitio mientras que el segundo es el título HTML5 Semántico de este tema. Desde el punto de vista de HTML4 esto no es del todo correcto. El administrador de web del buscador BING informa de esto como un error. En cambio Webmaster de Google lo pasa por alto. Pero ambos están indexando adecuadamente porque obtienen el título del elemento <title> de la página (que es el mismo que el contenido del segundo <h1>).
Puede haber más de un <h1> en HTML5 porque en todo documento hay siempre una sección predeterminada que es el <body>, de tal forma que un único <h1> en ese nivel contendrá el título del documento. Pero también podemos anidar secciones, como <article> que se define como una parte de un documento que es completamente autocontenida desde el punto de vista semántico. Es decir, si separamos esa sección y la insertamos en otro documento no deberá perder información semántica, para lo cual ha tener necesariamente un encabezado que titule la sección. Y ese encabezado puede y debe ser también un <h1>. Este elemento <article> no tiene necesariamente que ser un artículo de una publicación. Aunque ese caso es un buen ejemplo. Un artículo de una revista tiene información semántica como un título, una fecha y un autor. Si quitamos ese artículo de esa revista y lo insertamos en otra distinta, tanto una como otra así como el propio artículo no verán alterados su estructura semántica.
Esto es una estructura de secciones anidadas, como un <article> dentro de un <body>, cada uno con su <h1>. Hay quien desaconseja esto, como Steve Faulkner en The HTML5 Document Outline is a dangerous fiction. Comenta que cuando se anidan secciones también deberían usarse encabezados que a la vez fueran descendiendo en cada nivel. Pero esto se contradice con el concepto de independencia semántica que debe tener cada sección, aunque puedan anidarse.
La especificación de HTML5 de W3C del 23 de abril de 2014 dice que podemos poner cualquier nivel de encabezado en las secciones, aunque matiza que aconseja que sigan el nivel de anidamiento de las secciones. Es decir, si tengo un <h1> en el <body>, dentro de un <article> debería poner un <h2>. Esto está en el apartado de encabezados y secciones:
Las secciones pueden contener encabezados de cualquier nivel, pero se aconseja usar encabezados de nivel adecuado al anidamiento de esa sección dentro del documento.
(Sections may contain headings of any rank, and authors are strongly encouraged to use headings of the appropriate rank for the section's nesting level.)
Si buscamos la especificación del grupo WHATWG del 23 abril 2014 vemos esto en el apartado equivalente de encabezados y secciones:
Las secciones pueden contener encabezados de cualquier nivel, pero se aconseja usar sólo encabezados h1 o usar encabezados del nivel adecuado al anidamiento de esa sección dentro del documento.
(Sections may contain headings of any rank, but authors are strongly encouraged to either use only h1 elements, or to use elements of the appropriate rank for the section's nesting level.)
Si optamos por lo que dice WHATWG, un documento podría tener tantos h1 como secciones tuviera. En otro caso si no optamos por eso, las secciones deben llevar encabezados con nivel adecuado al anidamiento de esa sección. Estas contradicciones dan lugar a que hagamos mal uso de la especificación o que, por falta de claridad, no nos atrevamos a hacer uso de la misma.
El outliner para obtener el resumen de un documento
El outline en HTML5 resumirá los contenidos analizando las secciones y los encabezados como vimos antes. Para obtener este outline necesitaremos un script o aplicación, denominado como outliner, que ejecute el algoritmo de la especificación. Una herramienta que podemos utilizar es outliner de Gsnedders. Aplicada a este tema nos da algo como la imagen siguiente:
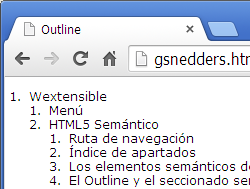
Compare esta imagen con la del apartado anterior con el outline de HTML4. Vea que ahora también se hace un sangrado de cada entrada, pero en este caso más que sólo por encabezados, se tienen en cuenta también las secciones. En esa página está la sección exterior <body> que porta un <h1> con el nombre del sitio Wextensible. Contiene dos secciones en el siguiente nivel, una es un <nav> donde su título se define en un <h2> con la palabra Menú. La otra sección es <article> que tiene también una sección <nav> con dos encabezados <h4> y luego el propio contenido estructurado en encabezados <h2>. Vea como los encabezados de distinto nivel son sangrados en el mismo nivel por el motivo de que si alguno está en una sección se considera la jerarquización de la sección y no la de su encabezado.
Podemos instalar una extensión al navegador Chrome para obtener el outline: extensión Outliner para Chrome.
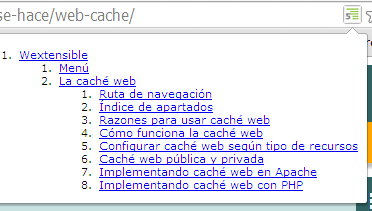
También para Opera podemos encontrar extensiones: outliner opera.
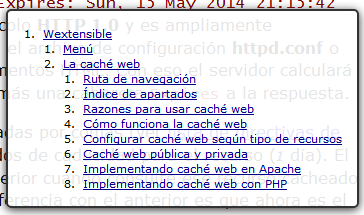
En un resumen outline si hay alguna sección sin encabezado requerido aparecerá con el título Untitled seguido del tag de esa sección. Con esto podemos hacer un seguimiento para que todas las secciones tengan su correspondiente encabezado y ver si la estructuración que habíamos diseñado coincide con el esquema de secciones y encabezados que nos da el outliner.
Aplicación práctica de elementos semánticos
Actualmente todos los navegadores principales soportan los elementos HTML5 como los que estoy usando header, footer, article, section, nav, aside, time. Si aún queremos dar soporte a versiones IE8 y anteriores podemos meter un script en un comentario condicional de IE para forzar la creación de estos elementos sin ponerlos en el DOM. Esta acción es suficiente para que este navegador no trate esos elementos como desconocidos:
<!--[if lt IE 9]><script>
var t=["header","footer","article","section","nav","aside","time"];
for(var i=0,maxi=t.length;i<maxi;i++){
document.createElement(t[i]);}
</script><![endif]--> Este script hay que ponerlo en el <head> de cada página para que funcione en IE. En este sitio tengo un script PHP de pre-ejecución prehjc.php para dotar de CSS específico para cada página, donde se inyecta un comentario HTML con información del proceso en todas las páginas del sitio. Esto me será útil para evitar recorrer todos los documentos modificándolos y así aprovecharé para incorporar ahí este comentario condicional. Una vez que IE8 o versión inferior cargue la página ejecutará ese script lo que permitirá dar estilo a estos nuevos elementos:
/* Nuevos elementos de HTML5 para navegadores que no los soportan (p.e. IE8) */ header, footer, article, section, nav, aside, time { display: block; }
A la hora de estructurar estos nuevos elementos de HTML5 se sigue el principio de no usarlos como destino de CSS. Por ejemplo, <header> es una cabecera de una sección. Si en nuestra página tenemos una cabecera como <div id="cabecera"> la primera intención sería reemplazar uno por otro y poner <header id="cabecera">. Pero lo más sencillo es no tocar nuestros elementos de estructura y envolverlos con los nuevos elementos semánticos:
<!DOCTYPE html> <html lang="es"> <head> ... </head> <body><header><div id="cabeza-menu"> <div id="cabeza"> <div class="logowx"></div><h1 class="titulowx">TÍTULO DEL SITIO</h1> </div> <nav><h2 class="dispnone">Menú</h2><ul id="menuwx"> ...LISTA DE MENÚ... </ul></nav> </div></header><!-- fin cabeza --><div id="contenido"><article> <header><div class="encab-fecha"> <div class="encab-datetime"> <time datetime="AAAA-MM-DD"> <span class="encab-dia">DD</span> <span class="encab-mes">MMM</span> <span class="encab-anyo">AAAA</span> </time> </div> <div class="encab-lista"><button type="button" id="boton-lista-apartados">≡</button></div> <h1>TÍTULO DE LA PÁGINA</h1> <nav><div id="lista-apartados"> <h4 class="dispnone">Ruta de navegación</h4> <ul> ...LISTA DE MIGAS... </ul> <h4 class="dispnone">Índice de apartados</h4> <ol> ...LISTA DE ENLACES A APARTADOS... </ol> </div></nav> </div></header> <h2 class="num">...</h2> ...CONTENIDO DE LA PÁGINA... </article></div><!-- fin contenido --><footer><div id="pie"> <div><a href="#cabeza">Arriba</a></div> </div></footer><!-- fin pie --><script>...</script> <script src="/res/inc/general.js" async></script> <noscript id="nojs"><style id="css-after"><?php echo $css_fold["after"]; ?></style></noscript> <noscript><link rel="stylesheet" href="/res/sty/base-nojs.css" /></noscript></body> </html>
El código anterior es una plantilla de la estructura que ahora estoy usando en este sitio. Los elementos semánticos vienen a ser como envolturas de los elementos de estructura. Ninguno de ellos tiene atributos class o id. No son objeto de estilo y no se referencian desde JavaScript. Resaltados en amarillo vemos los nuevos elementos de HTML5 y algunos h1, h2 y h4. Estos encabezados se usan para titular las secciones. Tienen clase dispnone que aplica un estilo display: none para ocultarlos, pero no impedirá que formen parte del Outline.
Actuando así podemos incorporar esos nuevos elementos sin tener que retocar mucho nuestra estructura y, si fuera el caso, podríamos eliminarlos en el futuro pues no habrían relaciones con CSS o JavaScript que les afecten.